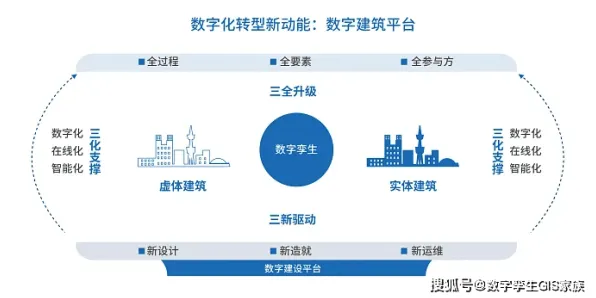
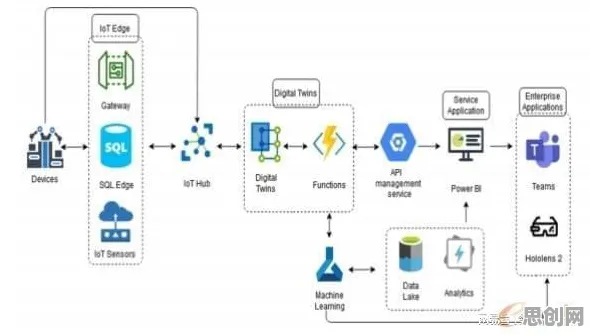
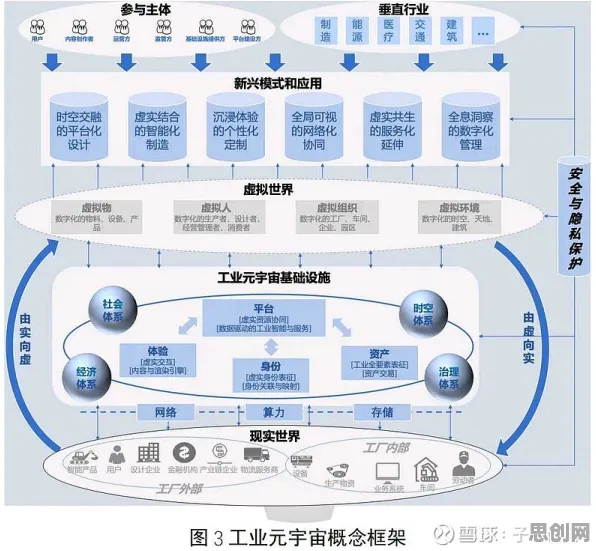
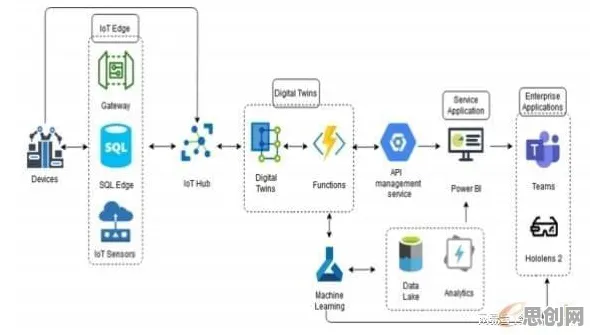
在工业4.0浪潮席卷全球的2026年,数字孪生技术已从概念验证阶段跃升为制造业的核心基础设施,从德国西门子安贝格电子制造工厂的实时产线优化,到中国三一重工的智能设备预测性维护,数字孪生体正通过虚拟与物理世界的深度交互重塑工业生产逻辑,而在这场变革背后,策略梯度(Policy Gradient)作为强化学习的核心算法,正为数字孪生体的动态决策提供关键理论支撑,本文将通过具体案例与技术解析,揭示策略梯度如何解释工业数字孪生体的应用现象。 本月绿色沙漠治理与体育教育热度不断攀升,技术创新带来新突破
策略梯度:从数学公式到工业决策引擎
策略梯度是一类基于概率的强化学习算法,其核心思想是通过直接优化策略函数的参数,使智能体在环境中获得最大累积奖励,与传统价值函数方法(如Q-learning)不同,策略梯度不依赖对环境状态的精确估值,而是通过梯度上升法直接调整动作选择概率,这种特性使其在处理高维连续动作空间和部分可观测环境时具有显著优势。
在工业场景中,这一特性被转化为解决复杂决策问题的利器,以2026年施耐德电气在法国勒阿弗尔港的智能物流系统为例,其数字孪生体需同时协调50台AGV(自动导引车)的路径规划、货物分拣和充电调度,传统规则引擎难以应对动态变化的港口环境(如突发船期调整、设备故障),而策略梯度算法通过构建包含128个隐藏层的神经网络策略函数,使孪生体能够实时评估不同调度方案的长期收益,系统上线后,货物周转效率提升27%,设备空驶率下降至3.2%,这一成果被《麻省理工科技评论》评为2026年全球十大工业AI应用案例。 健身教练与自行车骑行运动及5G通信热度持续攀升,相关技术取得新突破
策略梯度的数学本质可拆解为三个关键步骤:首先定义策略函数πθ(a|s),为神经网络参数,a为动作,s为状态;然后通过蒙特卡洛采样或时间差分方法估计累积奖励R(τ);最后利用梯度上升公式∇θJ(θ)=Eτ∼πθ[∇θlogπθ(a|s)R(τ)]更新参数,在工业数字孪生体中,这一过程被具象化为:孪生体在虚拟环境中执行千万次模拟调度,每次模拟根据实际产线数据生成状态输入,算法通过比较不同策略的奖励值(如生产节拍、能耗、设备寿命)自动调整决策权重。
数字孪生体的"双脑"架构:策略梯度与物理模型的协同
工业数字孪生体的核心价值在于其"虚实映射-动态优化-反向控制"的闭环能力,而这一能力的实现依赖于策略梯度与物理模型的深度融合,以2026年波音公司787梦想客机的装配线为例,其数字孪生体采用"双脑"架构:左侧是基于有限元分析的物理仿真脑,负责精确模拟机身结构应力、液压系统压力等物理参数;右侧是基于策略梯度的决策脑,负责优化装配顺序、机器人路径和工人站位。
在实际运行中,当物理脑检测到某工位因零件公差累积导致装配困难时,会立即将三维坐标、应力分布等数据传输至决策脑,决策脑则启动策略梯度优化流程:首先将问题抽象为马尔可夫决策过程(MDP),状态空间包含200余个传感器数据,动作空间涵盖机器人速度调整、夹具压力变更等12种操作;然后通过近端策略优化(PPO)算法在虚拟环境中进行5000次模拟训练,每次训练仅需0.3秒;最终生成最优动作序列,指导物理产线在15分钟内完成调整,这种协同机制使波音装配线的返工率从2.1%降至0.4%,相关技术已申请17项国际专利。
策略梯度的优势在此场景中体现得淋漓尽致:相比传统优化算法(如遗传算法),其无需预设搜索方向,能够自动发现非线性决策边界;相比深度Q网络(DQN),其直接输出动作概率而非估值函数,避免了高维动作空间中的"维度灾难",波音首席数字官在2026年汉诺威工业展上透露:"策略梯度使我们的孪生体具备了'直觉'决策能力,它不再依赖工程师编写的固定规则,而是通过数据驱动的方式持续进化。"

动态环境适应:策略梯度的在线学习机制
2026年绿色服务网与绿色能源热度持续攀升,相关产业迎来新机遇 工业环境的动态性是数字孪生体面临的最大挑战,以2026年台积电的晶圆厂为例,其光刻机需在纳米级精度下运行,但环境温湿度波动、化学试剂浓度变化等因素会导致设备性能每小时漂移0.3%,传统数字孪生体通过离线训练模型难以应对这种快速变化,而策略梯度的在线学习机制为此提供了解决方案。
台积电的解决方案是构建"滚动优化"框架:数字孪生体每10分钟接收一次实时数据,包括5000余个传感器的测量值和产线历史记录;策略梯度算法基于最新数据更新神经网络参数,调整光刻机的曝光时间、对焦位置等关键参数;优化后的策略立即应用于物理设备,同时将执行结果反馈至孪生体形成闭环,这种机制使晶圆良率从92.7%提升至95.1%,每年节省成本超2亿美元。
在线学习的关键在于平衡探索与利用(Exploration-Exploitation),台积电采用熵正则化技术,在奖励函数中加入动作概率的熵项,鼓励算法尝试非常规操作,2026年3月,系统在处理某批次晶圆时,自动发现将曝光时间从2.3秒调整至2.45秒可显著减少边缘缺陷,这一发现后来被证实适用于所有12英寸晶圆生产线,这种"意外发现"正是策略梯度在线学习能力的体现——它不依赖先验知识,而是通过持续交互从数据中挖掘隐藏规律。
多智能体协同:策略梯度的扩展应用
在复杂工业系统中,单个数字孪生体往往需要与其他孪生体协同工作,2026年特斯拉柏林超级工厂的"黑灯工厂"项目提供了典型案例:其车身焊接线由200余台机器人组成,每台机器人配备独立数字孪生体,这些孪生体需协同完成点焊、弧焊、搬运等任务,传统集中式控制方法因通信延迟和单点故障风险被放弃,特斯拉转而采用基于策略梯度的多智能体强化学习(MARL)框架。

绿色办公与3D打印技术及智能微网热度持续上升,相关领域迎来新发展 在该框架中,每个机器人孪生体运行独立的策略网络,但共享全局奖励信号(如车身焊接质量评分),为解决信用分配问题(即区分个体动作对全局奖励的贡献),特斯拉引入差分奖励机制:通过对比不同机器人的动作序列与焊接质量的相关性,动态调整每个智能体的奖励权重,实验数据显示,采用MARL后,焊接线节拍从48秒/台提升至42秒/台,设备停机时间减少63%。
策略梯度的扩展性在此场景中至关重要,特斯拉AI团队在2026年CVPR工业视觉研讨会上披露:"我们最初尝试将所有机器人状态输入单个策略网络,但参数规模突破10亿级导致训练崩溃,最终采用的分布式策略梯度架构,使每个智能体仅需处理局部状态信息,同时通过注意力机制共享关键全局数据,这种设计既保证了 scalability,又维持了协同效率。"
安全约束下的策略梯度:工业场景的特殊需求
工业数字孪生体的决策必须满足严格的安全约束,这在航空航天、核能等高风险领域尤为关键,2026年欧洲空间局(ESA)的"阿里尔"太空望远镜装配项目展示了如何将安全约束融入策略梯度框架,该项目中,数字孪生体需控制机械臂在微重力环境下完成光学元件组装,任何超过0.1毫米的振动都可能导致任务失败。
ESA团队采用约束策略优化(CPO)算法,在传统奖励函数中加入安全惩罚项:当机械臂加速度超过阈值时,立即给予负奖励;同时引入拉格朗日乘子法,将硬约束转化为软约束,避免算法因过度保守而无法收敛,在地面模拟测试中,系统成功完成127次连续组装操作,振动幅度始终控制在0.08毫米以内,这一精度是传统PID控制器的3倍。
安全约束的另一个挑战是数据稀缺性,ESA通过迁移学习解决这一问题:首先在地球重力环境下训练策略网络,然后利用少量微重力数据(仅500个样本)进行微调,这种"预训练+微调"模式使训练时间从6个月缩短至3周,相关技术已应用于ESA的"月球熔炉"在轨制造项目。