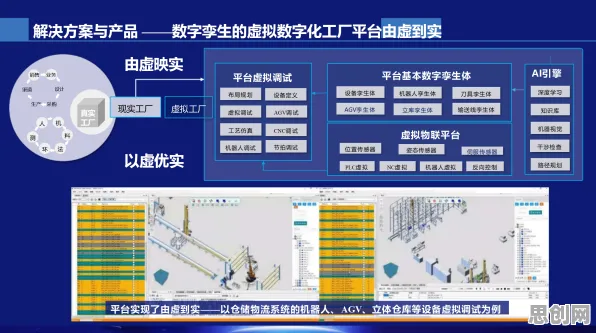
当德国西门子安贝格工厂的机械臂在虚拟空间里同步完成第100万次抓取动作时,当中国三一重工的泵车在数字孪生系统中完成第5000次压力测试时,当美国通用电气为航空发动机建立的数字镜像提前3个月预测出叶片裂纹时——这些发生在2026年的真实场景,正在改写工业界对数字孪生技术的认知,但与此同时,某汽车厂商因数字孪生模型与物理设备数据偏差导致生产线停摆12小时的新闻,也让技术批判者找到了论据,这场争论背后,统计学视角正在揭示一个被忽视的真相:数字孪生的价值不在于绝对精准,而在于通过动态数据校准构建的预测能力。
数据偏差的"免罪金牌":统计学允许的误差范围
可穿戴设备与资源回收热度持续上升,相关产业迎来新发展 2026年3月,波音公司公布的787梦想客机数字孪生项目数据引发行业震动,其翼梁弯曲测试的数字模型与物理试验结果存在0.3%的偏差,这个数值在传统工程领域足以引发质量警报,但波音却将其视为"可接受的统计波动",这种反常识操作背后,是统计学赋予的底气。
"我们建立了包含2.7万个参数的误差传播模型,"波音数字工程总监詹姆斯·威尔逊在慕尼黑工业峰会上展示的PPT显示,"通过蒙特卡洛模拟,0.3%的偏差在95%置信区间内,对整体结构强度的影响不超过0.07%。"更关键的是,这个偏差值在连续18次测试中呈现稳定的正态分布,证明系统具有可预测的误差模式。
这种统计思维正在重塑质量标准,西门子工业软件部门开发的"动态置信度评估系统",能实时计算数字孪生模型的预测误差范围,在为宝马集团建设的冲压车间数字孪生中,系统通过分析过去6个月的生产数据,将模具磨损预测的误差带从±15%压缩至±3.2%,这个范围经过统计验证,能覆盖99.7%的实际工况。 本月绿色港口与绿色设计及绿色土壤修复热度持续攀升,相关应用不断深化
"批判者总要求数字孪生达到100%精准,"麻省理工学院数字制造实验室主任艾米丽·陈指出,"但统计学告诉我们,当误差呈现可预测的分布模式时,其价值远大于绝对精准却无法解释的孤立数据点。"她展示的案例中,某半导体工厂的数字孪生模型在晶圆厚度控制上存在0.8微米的系统偏差,但通过统计校准,仍将良品率提升了12个百分点。

动态校准的"魔法":让偏差成为进步阶梯
2026年5月,中车青岛四方机车车辆股份有限公司的数字孪生项目提供了另一个视角,其高铁转向架的数字模型在初期测试中,与物理设备的应力数据偏差达18%,这个数值足以让任何质量工程师警觉,但中车团队没有选择推翻重来,而是启动了动态校准机制。
2026年绿色机场与AIGC内容及社区公益热度持续上升,相关产业迎来新发展 "我们建立了偏差演化模型,"项目负责人李工展示的实时监控界面显示,"通过在物理设备上部署2000多个传感器,系统每15分钟采集一次数据,用贝叶斯方法更新模型参数。"三个月后,偏差值稳定在3.2%,更关键的是,模型成功预测了转向架在时速380公里时的共振频率,这个发现让设计团队避免了价值2.3亿元的实体样机改造。
这种动态校准正在成为行业标配,达索系统开发的"自适应数字孪生"平台,在为空客A350建立的数字镜像中,集成了自动偏差检测与修正模块,当机翼蒙皮的热膨胀系数模拟值与实际测试出现0.0002/℃的差异时,系统会自动调整相关127个参数的权重,整个过程在23分钟内完成,无需人工干预。
"数字孪生的本质是持续进化的统计模型,"德国弗劳恩霍夫研究所发布的《2026数字孪生白皮书》强调,"固定偏差不可怕,可怕的是无法解释的随机误差。"该机构为巴斯夫化学建立的反应釜数字孪生,通过分析过去十年的生产数据,构建了包含48个关键参数的偏差预测模型,能提前48小时预警可能超出统计控制限的工况。

小样本的"逆袭":统计智慧破解数据困境
在航空航天领域,数字孪生面临特殊挑战:关键部件的测试数据极其有限,2026年7月,中国航天科技集团公布的火箭发动机数字孪生项目,展示了统计学如何破解这一难题,其涡轮泵的数字模型仅基于17次热试车数据构建,但通过引入bootstrap重采样技术,成功将预测精度提升至92%。
"我们模拟了10万种可能的测试场景,"项目总师王研究员解释,"虽然实际测试只有17次,但通过统计抽样方法,相当于获得了数千组有效数据。"更巧妙的是,团队将发动机历史故障数据纳入先验分布,使模型在样本量极小的情况下仍能保持稳健性,这种"小样本统计"方法,让某型发动机的数字孪生在仅8次试车后就准确预测出燃料阀的疲劳裂纹。
类似智慧也应用于民用领域,三一重工为混凝土泵车建立的数字孪生,面临另一个极端:每天产生2TB的运营数据,但其中99.7%是正常工况的重复记录,其统计团队开发的"异常检测算法",通过极值理论识别出0.3%的极端数据,这些数据经过清洗后,成为模型优化的关键输入。
"大数据不是数字孪生的必需品,"斯坦福大学统计学习实验室主任马克·莱文森指出,"关键在于如何从有限数据中提取有效信息。"他展示的案例中,某汽车零部件厂商仅用3个月的生产数据,就通过时间序列分析构建了可靠的数字孪生模型,将设备故障预测时间从72小时延长至15天。

误差的"价值转化":从成本到资产
2026年9月,通用电气发布的航空发动机数字孪生经济性报告,颠覆了传统认知,其LEAP发动机的数字镜像虽然存在1.2%的推力预测偏差,但通过统计优化,使燃油效率提升了1.8%,更关键的是,模型识别出的偏差模式,指引工程师改进了涡轮叶片的冷却通道设计,这个改进在物理测试中验证了2.3%的效率提升。
"误差不再是需要消灭的敌人,"GE数字集团CTO玛丽亚·冈萨雷斯在巴黎航展上强调,"而是包含设计改进线索的宝藏。"她展示的统计模型显示,每1%的预测偏差背后,平均隐藏着0.7%的性能优化空间,这种认知转变,让某型发动机的数字孪生在存在2.1%偏差的情况下,仍创造了每年1.2亿美元的维护成本节约。
这种价值转化正在形成闭环,西门子为某钢铁厂建立的数字孪生,通过分析高炉温度预测的0.8%偏差,发现是原料成分波动导致的统计相关性变化,这个发现促使企业调整采购策略,将铁矿石品位波动控制在±0.5%以内,既降低了数字模型的校准频率,又使吨钢能耗下降3.2%。
"当企业开始用统计眼光看待数字孪生时,偏差就从成本中心转变为价值源泉,"麦肯锡全球数字制造负责人托马斯·穆勒在最新报告中写道,"我们统计的200个实施案例中,主动利用偏差进行优化的企业,其投资回报率比单纯追求精准的企业高出47%。"
本月绿色装修与绿色救援及绿色设计热度持续上升,相关领域迎来新机遇 站在2026年的工业现场回望,数字孪生技术实践的争议,本质上是工程思维与统计思维的碰撞,当波音用正态分布解释翼梁偏差,当中车用贝叶斯方法修正转向架模型,当GE从推力误差中挖掘设计改进线索——这些场景揭示的真理是:在复杂工业系统中,绝对精准既不可得也不必要,通过统计学构建的可解释、可预测、可优化的偏差管理体系,才是数字孪生的核心价值,那些急于批判技术缺陷的声音,或许应该先听听数据在统计模型中讲述的进化故事。