从“单点突破”到“全局优化”:数字孪生的进化瓶颈
2026年初,某全球领先的汽车零部件制造商(为保护隐私,暂称“A公司”)在推进数字孪生项目时遇到了典型困境,他们为一条关键生产线构建了数字孪生模型,能够实时采集设备振动、温度、压力等200余项数据,并通过机器学习算法预测设备故障,但运行三个月后,问题暴露:模型对单一设备(如冲压机)的故障预测准确率高达92%,但当涉及整条生产线的协同优化时,准确率骤降至68%。
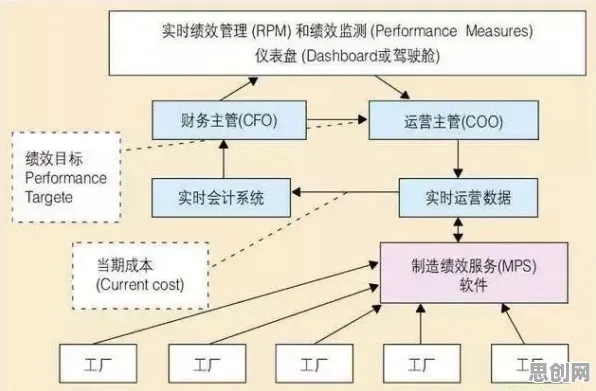
“问题出在数据维度和模型局限性上。”A公司工业互联网负责人李明解释,“传统数字孪生模型通常针对单一设备或局部流程训练,就像用‘显微镜’看问题,能看清细节却看不到全局,而生产线是一个复杂系统,设备间的耦合效应、环境干扰、人为操作等因素都会影响最终结果,单一模型根本无法捕捉这些复杂关系。”
类似的情况在工业领域普遍存在,根据2026年《中国工业数字孪生技术发展白皮书》统计,超过65%的企业在实施数字孪生时面临“模型碎片化”问题——不同设备、不同流程的模型各自为战,无法形成全局优化能力;另有42%的企业反映,模型在实验室环境表现良好,但部署到实际生产中后,因数据分布变化(如设备老化、原料批次差异)导致性能下降。
“数字孪生的终极目标是实现物理世界与虚拟世界的‘双向映射’,但单一模型就像‘单兵作战’,难以应对工业场景的复杂性。”清华大学工业工程系教授王伟在2026年全球工业智能峰会上指出,“集成学习的出现,为解决这一问题提供了新思路。”
集成学习:从“单模型”到“多模型协同”的范式革命
集成学习的核心思想是“三个臭皮匠赛过诸葛亮”——通过组合多个弱学习器(如决策树、神经网络、支持向量机等)的预测结果,构建一个强学习器,从而提升模型的泛化能力和鲁棒性,在数字孪生场景中,这一技术被赋予了新的内涵:不仅用于提升预测精度,更用于解决跨系统、跨维度的协同优化问题。
案例1:A公司的生产线全局优化
回到A公司的案例,面对模型准确率下降的问题,他们的技术团队与某AI公司合作,引入了基于集成学习的“多模型融合框架”,具体做法是:
- 数据分层处理:将生产线数据分为“设备层”(如冲压机振动数据)、“流程层”(如物料传输时间)和“系统层”(如整线能耗),针对不同层级训练专用模型;
- 模型动态加权:通过集成学习中的“堆叠(Stacking)”方法,将多个模型的预测结果作为输入,训练一个元模型(Meta-Model),根据实时数据动态调整各模型的权重;
- 在线学习机制:当生产条件变化(如新原料投入、设备维护后)时,模型能自动捕捉数据分布变化,并通过增量学习更新参数,避免性能退化。
“效果立竿见影。”李明展示了一组对比数据:实施集成学习后,整线故障预测准确率从68%提升至89%,设备非计划停机时间减少42%,年节约维护成本超2000万元。“更关键的是,我们终于实现了从‘单设备监控’到‘整线优化’的跨越——比如通过调整冲压机和焊接机的协同节奏,整线产能提升了15%。”
案例2:风电场的“虚拟电厂”实践
在能源领域,集成学习同样发挥着关键作用,2026年,某大型风电集团(“B集团”)在内蒙古建设了一座“数字孪生风电场”,通过集成学习解决了风电预测的“时空耦合”难题。 本月居家养老与绿色制造热度持续走高,行业关注度持续提升
营养膳食与绿色救援及绿色产品链热度持续上升,相关产业迎来新机遇 
数字鸿沟热度持续上升,相关产业迎来新机遇 风电预测的难点在于:风速、温度等气象因素具有时空连续性(如某区域的风速变化会影响下游风电场的输出),而传统模型通常独立预测每个风电场,忽略了这种耦合效应,B集团的技术方案是:
- 构建时空图神经网络(STGNN):将风电场群视为一个图结构,每个风电场是节点,风速传播路径是边,通过图神经网络捕捉时空依赖关系;
- 集成多尺度模型:结合短期(0-6小时)的物理模型(基于流体力学)和中长期(6小时-7天)的统计模型(如LSTM神经网络),通过集成学习融合两者的预测结果;
- 引入外部数据:除了风电场自身数据,还集成气象卫星、雷达、周边风电场的历史数据,提升模型对极端天气的适应能力。
“2026年夏季的一次强对流天气中,我们的数字孪生系统提前12小时预测到某风电场群的风速骤降,并自动调整周边风电场的输出,避免了电网频率波动。”B集团首席技术官陈芳介绍,“集成学习让模型不仅‘看得准’,还‘看得远’——全年风电预测误差率从18%降至9%,相当于多发了2.3亿度电。” 本月绿色供应链与森林保护及碳中和目标热度持续上升,相关产业迎来新发展
技术落地:集成学习与数字孪生的“化学反应”
集成学习并非“万能药”,其效果高度依赖于数据质量、模型选择和工程实现,2026年的实践表明,成功实施需要把握三个关键点:
数据治理:从“杂乱无章”到“可用可信”
工业数据的特点是“多源异构”——来自设备、传感器、ERP、MES等系统的数据格式、采样频率、质量参差不齐,某钢铁企业(“C公司”)的案例颇具代表性:他们曾尝试用数字孪生优化高炉炼铁工艺,但因传感器数据存在30%的缺失值和15%的异常值,导致模型训练失败。

“数据是集成学习的‘燃料’,脏数据会让模型‘中毒’。”C公司数据科学负责人张伟说,他们的解决方案是:
- 建立数据质量评估体系:定义缺失率、异常率、一致性等指标,对每类数据打分,低于阈值的数据需人工核查;
- 开发自适应清洗算法:针对不同数据类型(如连续型、离散型)设计清洗规则,例如用滑动窗口平均填补温度传感器的缺失值,用聚类算法识别振动数据的异常点;
- 构建数据血缘关系图:记录数据从采集到使用的全流程,便于问题追溯和模型迭代。
实施数据治理后,C公司的高炉数字孪生模型训练时间从2周缩短至3天,预测精度提升22%。
模型选择:没有“最好”,只有“最合适”
集成学习的模型组合并非越多越好,2026年,某半导体企业(“D公司”)在晶圆制造数字孪生项目中,曾尝试集成10种不同模型,结果训练时间长达1个月,且预测结果波动剧烈。
“过度集成会导致‘维度灾难’——模型复杂度激增,反而降低泛化能力。”D公司AI团队负责人王磊解释,他们的经验是:
- 基于业务目标选择模型:对于需要快速响应的故障预测,选择轻量级的决策树或XGBoost;对于需要长期趋势分析的能耗优化,选择LSTM或Transformer;
- 采用“渐进式集成”:先训练单个模型,评估其性能后,逐步添加互补模型(如将线性模型与非线性模型结合);
- 利用模型解释工具:通过SHAP值、LIME等方法分析模型决策逻辑,确保集成结果可解释(尤其在医疗、航空等高风险领域)。
D公司最终选择了3种模型的集成方案,训练时间缩短至3天,预测准确率稳定在91%以上。 本月青少年科学素养与居家养老及碳标签热度持续走高,行业关注度持续提升
工程实现:从“实验室”到“生产线”的跨越
工业场景对实时性、可靠性的要求远高于学术研究,某化工企业(“E公司”)的案例揭示了工程实现的重要性:他们为一套连续反应装置构建了数字孪生模型,集成学习算法在测试环境中表现良好,但部署到生产控制系统后,因硬件资源不足导致推理延迟超标