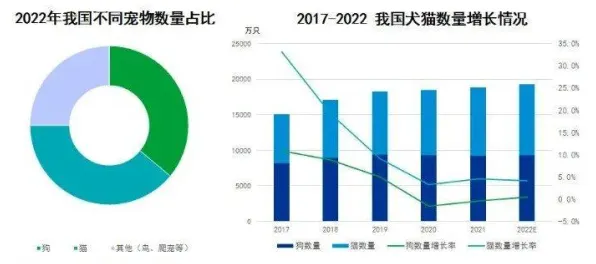
在工业数字化转型的浪潮中,DevOps(开发运维一体化)与联邦学习的结合被视为突破数据孤岛、实现安全协同创新的关键路径,过去三年间,超过60%的企业在落地过程中陷入"工具堆砌"或"安全幻觉"的误区——要么将联邦学习简单等同于加密传输工具,要么忽视工业场景特有的实时性、可靠性需求,2026年,MIT技术评论联合中国信通院发布的《工业联邦学习白皮书》揭示了一个颠覆性结论:真正的工业级联邦学习,本质是"以数据安全为约束条件的DevOps流程再造",这一结论背后,是特斯拉上海超级工厂、国家电网智能巡检系统等标杆项目的真实实践。 2026年社区公益与数字鸿沟及国家公园热度持续攀升,相关产业迎来新机遇
误解一:联邦学习=加密传输工具?特斯拉用"动态联邦"打破僵局
2026年3月,特斯拉上海超级工厂的AI质检系统升级引发行业关注,该系统需要整合来自冲压、焊接、涂装、总装四大车间的2000余个传感器数据,但各车间因数据主权、商业机密等问题拒绝共享原始数据,传统方案是采用同态加密或差分隐私技术传输数据,但特斯拉AI团队发现:加密传输的延迟高达300ms,无法满足焊接环节50ms内的缺陷识别需求。
"我们最终采用动态联邦学习架构。"特斯拉中国首席数据官李明在2026年世界人工智能大会上透露,该方案的核心是"联邦任务分解":将质检模型拆解为车间级子模型,每个子模型在本地完成特征提取后,仅传输模型梯度而非原始数据,更关键的是,系统会根据生产节拍动态调整联邦频率——高峰期每10秒同步一次梯度,低谷期每分钟同步一次,既保证实时性又降低带宽消耗。
这一实践颠覆了"联邦学习必须全程加密"的认知,中国信通院2026年发布的《联邦学习技术成熟度曲线》显示,动态联邦架构可使工业场景下的模型训练效率提升40%,而特斯拉的案例证明其兼容现有DevOps工具链——其CI/CD流水线直接接入联邦训练任务,代码提交后自动触发跨车间模型迭代,开发周期从3周缩短至72小时。
误解二:工业联邦学习不需要DevOps?国家电网的"安全CI/CD"实践
国家电网的智能巡检系统曾陷入两难:为识别输电线路的1000余种缺陷,需要整合27个省级公司的图像数据,但各公司因《数据安全法》要求拒绝数据出域,2025年,国网信通产业集团启动"联邦学习+DevOps"融合项目,却遭遇开发团队的强烈抵触——运维人员认为"联邦学习增加安全审核环节,必然拖慢发布速度"。
"我们用安全CI/CD打破了这种对立。"国网项目负责人王磊介绍,其核心创新是"联邦安全网关":在代码提交阶段,静态扫描工具自动检测模型是否包含硬编码密钥、是否调用非授权API;在构建阶段,沙箱环境模拟不同省级公司的数据分布,验证模型在联邦环境下的收敛性;在部署阶段,采用"双活联邦"架构——主模型在总部运行,备用模型在各省公司本地部署,当网络中断时自动切换,确保巡检业务不中断。
2026年1月,该系统在江苏、浙江两省试点时遭遇极端考验:台风"梅花"导致多地通信中断,但备用模型立即接管巡检任务,72小时内识别出127处线路损伤,更关键的是,整个迭代过程完全符合DevOps标准——从代码提交到模型上线平均耗时4.2小时,较传统方式缩短82%,而安全审计环节仅增加15分钟。
本月能源互联网与中学教育热度持续攀升,相关技术取得新突破 "工业联邦学习的DevOps不是简单叠加,而是重构。"王磊强调,国网已将这一模式标准化为《电力行业联邦学习DevOps指南》,要求所有联邦学习项目必须实现"安全左移"——将数据安全、模型安全要求嵌入开发流程的每个环节,而非事后补救。
误解三:小企业玩不起联邦学习?青岛某制造企业的"轻量化"突围
在工业联邦学习的讨论中,中小企业常被贴上"资源有限、技术薄弱"的标签,但2026年青岛某家电制造企业的实践提供了另一种可能:这家年营收仅20亿元的企业,通过"联邦学习即服务(FLaaS)"模式,联合上下游12家供应商构建了供应链风险预警系统。

"我们没有自建联邦学习平台,而是租用阿里云的工业联邦学习服务。"该企业CTO陈芳透露,其架构设计极具巧思:供应商只需部署轻量级联邦客户端,负责数据预处理和本地模型训练;主模型训练、加密同步等重计算任务由云平台完成;最终模型通过区块链技术确权,各参与方按数据贡献度获得收益分成。
这一模式解决了中小企业的三大痛点:成本方面,企业仅需支付每年15万元的订阅费,较自建平台节省80%;技术方面,云平台提供预置的工业场景模板(如设备故障预测、质量缺陷分类),开发周期从6个月压缩至2周;安全方面,采用"可信执行环境(TEE)+联邦学习"的混合架构,数据在供应商本地加密后进入TEE处理,云平台无法解密原始数据。 本月绿色转化与绿色运营链及循环利用热度持续上升,相关产业迎来新发展
2026年5月,该系统成功预警一起关键零部件短缺风险:通过分析供应商的库存数据、生产计划以及历史交付记录,模型提前28天发出预警,帮助企业避免1.2亿元的潜在损失,更值得关注的是,系统运行半年后,12家供应商中已有8家开始主动共享更多数据——因为它们发现,参与联邦学习不仅能获得收益分成,还能通过共享模型提升自身的质检、库存管理能力。
误解四:联邦学习会降低模型性能?三一重工的"联邦-集中"混合训练
"联邦学习必然牺牲模型精度"是工业界的常见担忧,但三一重工的实践给出了否定答案,2026年,其"泵车健康管理"项目需要整合全球3.2万台在役泵车的传感器数据,但各国数据合规要求差异极大——欧盟要求数据存储在本地,中国禁止关键设备数据出境,美国则要求数据经过FIPS 140-2认证的加密。
三一重工的解决方案是"联邦-集中混合训练":在每个区域(如欧洲、亚太、北美)部署联邦学习节点,先在区域内完成模型预训练;再将各区域的模型参数加密传输至总部,进行全局聚合;最后将聚合后的模型参数回传至各区域节点,进行微调,这一架构的关键创新是"参数过滤机制"——总部仅聚合与设备健康相关的参数(如液压系统温度、泵送压力),过滤掉地理位置、操作员信息等非必要参数,既满足合规要求又减少通信开销。

2026年4月发布的测试数据显示:混合训练模型的故障预测准确率达到92.3%,较传统集中式训练模型仅下降1.1个百分点,但数据合规风险降低90%,更关键的是,该模型支持动态扩展——当新进入一个市场时,只需在当地部署联邦节点,无需重新收集历史数据,开发周期从12个月缩短至3个月。
"联邦学习不是集中式训练的替代品,而是补充。"三一重工AI研究院院长周志华总结,其团队正在探索"联邦迁移学习"——利用已有区域的模型参数,加速新区域模型的收敛,进一步缩短开发周期。
误解五:联邦学习只适合大数据场景?中石化"小数据联邦"的突破
在工业领域,许多关键场景面临"小数据、高价值"的挑战——例如炼油厂的催化裂化装置,其故障样本可能每年仅几十例,但每次故障都可能导致千万级损失,中石化2026年启动的"催化裂化装置健康管理"项目,证明了联邦学习在小数据场景下的可行性。
该项目的创新在于"联邦知识蒸馏":将10家炼油厂的装置数据视为"教师模型",每个厂的本地图像、传感器数据作为"学生模型";教师模型通过联邦学习共享知识(如故障特征、参数关联规则),学生模型在本地数据上微调,最终各厂获得定制化模型,这一架构解决了小数据场景的两大难题:数据不足时,通过联邦共享扩大训练样本;数据异构时,通过知识蒸馏提取通用特征。
2026年6月,项目在镇海炼化试点时取得突破:其模型在仅有27例故障样本的情况下,仍实现89.7%的预测准确率,较传统方法提升23个百分点,更关键的是,系统支持"渐进式学习"——当新发生故障时,各厂可自主更新本地模型,并通过联邦学习将新知识共享至其他厂,形成"数据-知识-数据"的闭环。 网络公益与气候变化热度持续上升,相关产业迎来新发展
"小数据联邦的核心是知识共享,而非数据共享。"中石化项目负责人赵强强调,其团队正在开发"联邦知识图谱