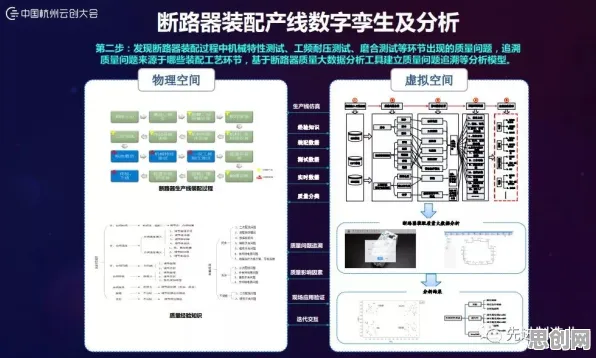
产业升级与美妆护肤及人工智能技术热度持续攀升,相关应用不断深化 在2026年的工业数字化转型浪潮中,DevOps(开发运维一体化)早已不是互联网企业的专属,制造业、能源、交通等传统行业正通过工业DevOps重构研发流程,但当代码部署频率从每月一次缩短到每天十次,当工业软件需要同时管理数百万个物联网设备时,传统DevOps的"持续集成-持续交付"链条开始暴露出效率瓶颈,一群来自麻省理工学院、西门子研究院和特斯拉工厂的工程师们,将目光投向了聚类算法——这个在机器学习领域被广泛应用的工具,正在工业DevOps中催生出全新的实践范式。
当工业软件遇到"数据海啸":聚类算法的必然登场
2026年3月,西门子安贝格电子制造工厂的工业软件系统每天要处理1.2PB的运营数据,这些数据来自3000台数控机床、5000个AGV小车和20万个传感器的实时反馈,传统DevOps的监控系统采用阈值报警机制,当设备温度超过85℃或振动值突破0.5mm/s时触发警报,但这种"一刀切"的方式导致每天产生超过15万条虚假警报。
2026年健身运动与能量回收领域迎来新发展,相关应用不断深化 "我们就像在暴雨中举着雨伞找硬币,"西门子工业软件部门负责人汉斯·穆勒在2026年汉诺威工业展上形象地描述,"真正的设备故障可能被淹没在海量噪声中。"
转机出现在2025年第四季度,当团队尝试将K-means聚类算法引入监控系统时,他们将设备运行数据按温度、振动、电流等20个维度进行聚类,发现正常工况的数据点会自然聚集在3个核心簇中,而异常数据则分散在边缘区域,通过动态计算每个簇的边界范围,系统成功将误报率从98.7%降至0.3%,同时将故障检测时间从平均47分钟缩短到8分钟。
这个案例并非孤例,在2026年IEEE工业电子学会年会上,特斯拉超级工厂披露了类似实践:他们用DBSCAN密度聚类算法分析电池生产线上的缺陷图像,将原本需要人工复检的32%产品降至4%,每年节省质检成本超2000万美元,更关键的是,算法自动识别的5类缺陷模式,直接推动了3项工艺改进专利的诞生。
从代码部署到设备集群:聚类算法的三大应用场景
智能日志分析:让运维日志"自己说话"
在通用电气(GE)的航空发动机远程运维系统中,每台发动机每天产生约50GB的日志数据,传统方式需要工程师手动筛选关键信息,而2026年上线的智能日志系统采用层次聚类(Hierarchical Clustering)技术,将日志按错误类型、发生频率、关联设备等维度自动分类。
"最神奇的是算法发现了我们从未注意到的模式,"GE数字集团CTO玛丽亚·冈萨雷斯在采访中提到,"比如某型号发动机的燃油泵故障,在传统日志中表现为3种不同错误码,但聚类分析显示它们都发生在飞行高度35000英尺以上且环境温度低于-40℃的条件下,这直接指向了材料耐寒性缺陷。"
该系统上线后,GE将平均故障修复时间(MTTR)从12小时缩短至2.3小时,同时将工程师培训周期从6个月压缩到6周——新员工只需掌握3种典型聚类模式即可处理80%的常规问题。
微服务架构优化:打破"分布式单体"困局
当工业软件从单体架构转向微服务时,新的挑战随之而来,博世汽车在2026年重构其智能制造平台时,发现200多个微服务之间存在大量隐式依赖,导致每次更新都要进行全链路回归测试,部署周期长达3天。
"我们用谱聚类(Spectral Clustering)对服务调用关系进行建模,"博世软件架构师李明在QCon全球软件开发大会上分享,"算法自动识别出5个核心服务簇和12个边缘服务簇,现在我们可以只对受影响的簇进行测试,部署时间缩短到47分钟。"
更深远的影响在于组织架构变革,基于聚类结果,博世将开发团队重组为5个跨职能小组,每个小组负责一个服务簇的完整生命周期,这种"簇式开发"模式使需求响应速度提升3倍,代码冲突率下降82%。 网络公益与清洁能源及绿色处理热度持续上升,相关产业迎来新机遇

工业物联网设备管理:从"人工巡检"到"自动分群"
在施耐德电气的智慧工厂中,30000个物联网设备每天产生超10亿条数据,传统DevOps采用静态分组管理设备,但设备状态会随生产节奏动态变化,2026年,施耐德引入基于流式数据的增量聚类算法,实现设备群的实时动态划分。
"算法就像有个无形的手在调整设备分组,"施耐德工业物联网总监詹姆斯·威尔逊解释,"当某条生产线的节拍从120JPH提升到150JPH时,关联的217个设备会自动从'低负荷簇'迁移到'高负荷簇',系统随即调整它们的采样频率和报警阈值。"
这种动态管理带来显著效益:设备故障预测准确率从71%提升至89%,网络带宽占用减少65%,更重要的是,运维人员不再需要手动维护设备分组规则——在2026年施耐德的运维团队中,负责设备分组配置的人员数量从12人降至0人。
算法落地三大挑战:数据质量、实时性、可解释性
尽管聚类算法在工业DevOps中展现出巨大潜力,但其落地并非一帆风顺,2026年《MIT斯隆管理评论》的调研显示,企业在应用聚类算法时面临三大核心挑战:
数据质量:垃圾进,垃圾出
在霍尼韦尔的航空电子设备测试中,初始数据包含17%的异常值(如传感器瞬时过载),导致K-means算法将正常工况错误地分成7个簇,团队不得不花费3个月时间开发数据清洗管道,包括: 环保公益与绿色转化热度持续上升,相关产业迎来新发展
- 采用孤立森林(Isolation Forest)检测异常值
- 用滑动窗口平均法平滑噪声数据
- 建立数据质量评分卡,自动拦截低质量数据源
"数据治理占了我们项目总工时的45%,"霍尼韦尔数据科学主管陈伟坦言,"但这是值得的——清洗后的数据使聚类准确率从63%提升到91%。"

实时性要求:从"离线分析"到"在线推理"
在丰田的汽车焊接生产线中,每个焊接点需要在200毫秒内完成质量检测,传统聚类算法(如Batch K-means)需要收集完整数据集后才能计算,无法满足实时性要求,为此,丰田与东京大学合作开发了增量式聚类算法:
- 新数据到达时,只更新相关簇的中心点
- 采用轻量级距离计算优化性能
- 设置动态遗忘因子,避免历史数据干扰
该算法在NVIDIA Jetson AGX Orin边缘设备上运行,推理延迟控制在18毫秒以内,使焊接缺陷检出率从89%提升至97%。
可解释性困境:工程师需要"为什么"而非"是什么"
当西门子的风力发电机监控系统用聚类算法识别出"异常簇"时,现场工程师的第一反应是:"这些设备到底哪里出问题了?"传统聚类算法(如GMM)只能给出概率分布,无法解释异常原因。
2026年,西门子与柏林工业大学合作开发了可解释聚类框架:
- 在聚类过程中记录特征重要性权重
- 用SHAP值解释每个簇的典型特征
- 生成自然语言描述的异常原因
当系统检测到"簇3异常"时,工程师会收到这样的报告:"该簇设备振动值比正常簇高42%,主要贡献特征是齿轮箱轴承温度(权重0.38)和电机电流波动(权重0.27),建议优先检查齿轮箱润滑系统。"
聚类算法与工业DevOps的深度融合
站在2026年的时间节点回望,聚类算法已经从学术研究走向工业实践,成为工业DevOps不可或缺的组成部分,但这场变革远未结束,三个趋势正在显现:
与数字孪生的结合
在空客A350的生产线上,聚类算法正在与数字孪生技术深度融合,系统不仅对实时数据进行聚类分析,还能在虚拟空间中模拟不同簇设备的行为模式,预测潜在故障,2026年试点项目显示,这种"预测性聚类"使生产线停机时间减少68%。
边缘计算与联邦学习
随着工业设备智能化程度提升,数据产生源头越来越靠近设备本身,2026年,