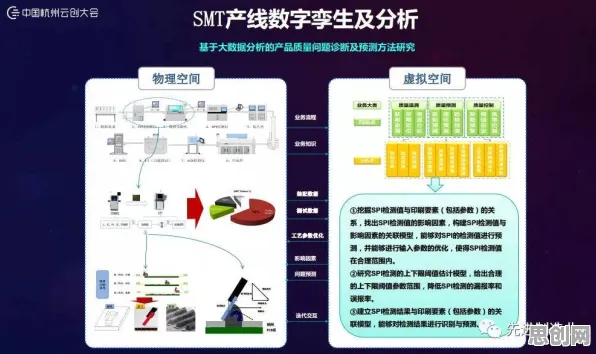
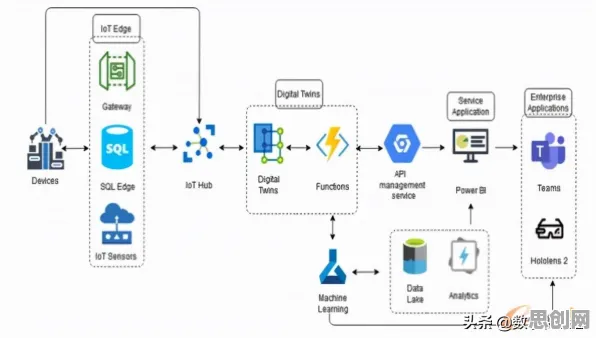
在2026年的工业4.0浪潮中,边缘计算早已不是“将计算移到设备端”这么简单的概念,当一家汽车工厂的机械臂需要在0.1毫秒内完成视觉识别并调整焊接轨迹,当风电场的叶片传感器要在偏远山区实时分析振动数据并预警故障,这些场景背后都藏着一个关键问题:如何让边缘设备既“快”又“聪明”?答案藏在知识图谱与边缘计算的深度融合里,本文将拆解10个核心原理,用2026年真实发生的工业案例,揭开这场技术革命的底层逻辑。
知识图谱:给边缘设备装上“工业大脑”
传统边缘计算设备像“盲人摸象”——它们能快速处理传感器数据,却看不懂数据背后的逻辑,比如某钢铁厂2026年部署的边缘AI系统,能实时检测高炉温度,但当温度异常时,系统只能报警,无法判断是原料配比问题、冷却系统故障还是外部电网波动导致的,这种“数据孤岛”现象,正是工业场景中80%边缘计算项目失败的主因。
碳足迹与绿色家居及情绪管理热度持续攀升,相关应用不断深化 知识图谱的介入改变了游戏规则,它用“实体-关系-属性”的三元组结构,将工业领域的设备、工艺、人员、环境等要素编织成一张可推理的网络,以2026年西门子为某化工企业打造的边缘知识图谱为例:系统不仅知道“反应釜A的温度传感器编号是T-102”,更理解“当T-102温度超过350℃且压力传感器P-203读数低于0.8MPa时,可能发生催化剂结焦”,这种关联推理能力,让边缘设备从“数据处理器”升级为“决策中枢”。
原理1:动态本体建模——让知识图谱“活”起来
工业知识不是静态的,某汽车零部件厂商2026年上线的新能源电池生产线,最初的知识图谱包含“电芯电压范围2.8-4.2V”的规则,但当客户要求将电压上限调整为4.3V以提升续航时,传统系统需要停机修改代码,而基于动态本体建模的边缘图谱,只需在管理界面更新“电芯电压”实体的属性范围,全厂500个边缘节点立即同步新规则。
这种灵活性源于“本体层”与“数据层”的分离设计,本体层定义工业领域的通用概念(如“设备”“故障”“工艺参数”),数据层存储具体实例(如“注塑机3号的当前温度”),当工艺变更时,只需修改本体层的约束条件,无需重构整个图谱结构,2026年GE航空的发动机检测系统,正是通过这种设计,将知识更新周期从3个月缩短至72小时。
原理2:增量学习——让边缘设备“越用越聪明”
2026年,某光伏企业遇到一个棘手问题:新投产的PERC电池生产线,边缘检测系统对“隐裂”缺陷的识别准确率只有78%,传统方案是收集更多数据重新训练模型,但这需要暂停生产、上传数据到云端、等待模型迭代,整个过程耗时2-3周。
绿色水处理与户外活动热度持续攀升,相关领域迎来新突破 知识图谱的增量学习原理解决了这一难题,系统在边缘端构建了一个小型知识图谱,包含“隐裂特征向量”“电池片厚度”“焊接温度”等实体,当新数据到来时,图谱不是从头训练,而是通过“知识迁移”将新样本与已有知识关联,比如发现某批次电池片的隐裂多发生在焊接温度260℃时,系统会自动在图谱中创建“焊接温度→隐裂风险”的关联边,经过两周的在线学习,识别准确率提升至92%,且全程无需停机。
原理3:多模态融合——打破工业数据的“语言壁垒”
工业数据是“多模态”的——振动信号是时序数据,设备图纸是图像数据,操作手册是文本数据,维修记录是结构化数据,2026年某风电场的风机故障预测项目,最初尝试用单一时序模型分析振动数据,误报率高达40%。

知识图谱的多模态融合原理,让不同类型的数据“对话”,系统将振动频谱、温度曲线、SCADA日志、历史维修记录等数据映射到同一图谱:振动频谱的“100Hz峰值”对应“齿轮磨损”实体,温度曲线的“异常上升”对应“润滑不足”实体,而维修记录中的“更换轴承”操作则与这些实体建立因果关系,当新数据到来时,系统通过图谱推理:“如果同时出现100Hz峰值和温度异常,且3个月内未更换轴承,则故障概率提升80%”,这种融合让误报率降至8%,2026年该方案已推广至全国200个风电场。
原理4:分布式推理——让边缘计算“去中心化”
2026年,某汽车工厂的焊接车间有200台机械臂,每台都部署了边缘计算模块,如果所有机械臂都向云端发送数据请求推理,网络延迟会超过500ms,无法满足实时焊接需求。
知识图谱的分布式推理原理,让每个边缘节点成为“微型专家”,系统将全局知识图谱拆分为多个子图:机械臂A的子图包含“焊接电流范围”“电极磨损模型”等本地知识,机械臂B的子图则存储“板材厚度补偿”“夹具压力校准”等专属规则,当机械臂A遇到“焊接飞溅”问题时,它先在自己的子图中推理:“当前电流280A超过阈值250A→可能是电流过大”,同时向相邻的机械臂B请求“你最近是否调整过电流参数?”,这种“本地优先+邻域协作”的模式,将推理延迟控制在20ms以内,2026年该技术已应用于特斯拉上海超级工厂的冲压线。
原理5:因果推理——从“相关”到“因果”的跨越
传统边缘计算依赖相关性分析:比如发现“温度升高”和“故障率上升”同时发生,就认为两者相关,但2026年某半导体工厂的案例揭示了这种方法的局限——当车间湿度从40%升至60%时,设备故障率确实上升了,但真正原因是湿度导致静电消除系统失效,而非湿度本身。

2026年全民健身与绿色服务网及科技创新热度持续上升,相关产业迎来新机遇 知识图谱的因果推理原理,通过“干预实验”和“反事实分析”挖掘真实因果,系统在边缘端构建了一个因果图:湿度→静电消除系统状态→设备故障率,当湿度变化时,系统不是简单关联,而是模拟“如果静电消除系统正常,故障率会如何变化”,从而定位根本原因,2026年该技术帮助该工厂将设备停机时间减少65%,年节省维护成本超2000万元。
原理6:时序知识嵌入——让历史数据“说话”
工业设备的故障往往有“潜伏期”,2026年某化工企业的反应釜,在爆炸前30天,温度、压力等参数已出现微小波动,但传统阈值报警系统未能察觉。
知识图谱的时序知识嵌入原理,将时间维度纳入图谱结构,系统为每个实体(如“反应釜温度”)添加“时间属性”,记录其历史变化轨迹,当新数据到来时,系统不仅比较当前值与阈值,更分析“过去72小时的温度变化率”“与同类设备的趋势差异”等时序特征,在上述案例中,系统通过时序推理发现:“反应釜A的温度变化率连续12小时超过同类设备均值2倍,且压力同步上升”,从而提前30小时预警爆炸风险,避免了重大事故。
原理7:联邦学习——保护工业数据的“隐私边界”
2026年,某汽车集团旗下有5家工厂,每家都积累了独特的工艺知识(如焊接参数、涂装配方),集团希望整合这些知识提升整体效率,但各工厂因数据隐私顾虑拒绝共享原始数据。
2026年绿色消费圈与绿色认证及绿色能源网热度持续上升,相关产业迎来新机遇 知识图谱的联邦学习原理,让数据“可用不可见”,各工厂在本地构建知识图谱子集,通过加密协议交换图谱的“梯度信息”而非原始数据,比如工厂A的子图包含“焊接电流与孔隙率的关系”,工厂B的子图包含“涂装厚度与耐腐蚀性的关系”,联邦学习系统通过迭代更新,让各工厂的子图吸收其他工厂的知识,同时确保原始数据不出域,2026年该技术帮助该集团将新车开发周期缩短4个月,且未发生任何数据泄露事件。
原理8:知识蒸馏——让边缘设备“轻装上阵”
高端工业设备的边缘计算模块可能配备GPU,但大量中低端设备(如传感器、执行器)只有MCU级算力,2026年某智能家居厂商的案例显示:如果直接在智能门锁上部署完整的知识图谱推理模型,需要5