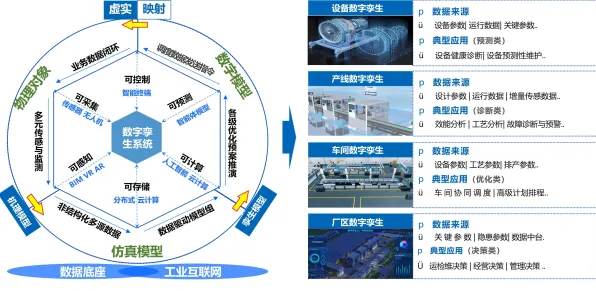
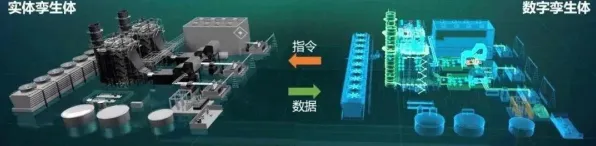
知识点一:生成式AI如何让数字孪生体“从静态模型变为动态生命体”?
传统数字孪生体的核心是“物理实体-虚拟模型”的双向映射,但2026年的工业实践中,这一关系正在被生成式AI彻底重构,过去,数字孪生体的模型更新依赖人工输入数据或预设规则,更新周期长、成本高,且难以应对复杂工况的动态变化;而生成式AI通过自监督学习、强化学习等技术,能够从海量工业数据中自动提取特征,实时生成更精准的虚拟模型,甚至能预测物理实体的未来状态。
案例:西门子安贝格电子制造工厂的“自进化数字孪生”
2026年,西门子在安贝格工厂部署了基于生成式AI的数字孪生系统,该系统通过接入工厂内5000多个传感器的实时数据(包括温度、振动、电流等),结合历史生产记录和设备维护日志,利用生成对抗网络(GAN)自动生成设备健康状态的动态模型,当一台SMT贴片机出现轻微振动异常时,系统不仅能在虚拟模型中复现这一异常,还能通过强化学习模拟不同维修策略的效果,最终推荐“更换特定轴承”的最优方案,将设备停机时间从传统的4小时缩短至45分钟,更关键的是,这一模型会随着新数据的输入持续优化——据西门子官方数据,该系统上线6个月后,模型预测准确率从初始的78%提升至92%,真正实现了“越用越聪明”。
技术逻辑:生成式AI的核心优势在于“无监督学习”能力,传统数字孪生体需要人工标注数据(如“正常振动范围”“故障特征”),而生成式AI(如变分自编码器VAE)能直接从原始数据中学习分布规律,自动识别“正常”与“异常”的边界,这种能力在复杂工业场景中尤为重要——在汽车焊接生产线中,焊缝质量的影响因素包括电流、电压、焊接速度、材料厚度等20多个变量,传统模型难以覆盖所有组合,而生成式AI能通过生成“虚拟焊缝”数据,覆盖未被实际采集的工况,从而提升模型的泛化能力。

知识点二:生成式AI如何破解数字孪生体的“数据孤岛”难题?
2026年碳中和与教育公益及音乐产业热度持续上升,相关领域迎来新发展 工业数字孪生体的落地面临一个核心挑战:数据分散在不同系统、不同设备中,格式不统一、标准不一致,导致“模型虽好,但用不起来”,2026年的解决方案是:利用生成式AI的“数据生成”能力,构建跨系统、跨设备的统一数据底座。
案例:三一重工的“工业数据宇宙”计划
三一重工在2026年启动了“工业数据宇宙”项目,目标是整合全球30个工厂、10万台设备的异构数据(包括PLC日志、MES记录、ERP订单等),项目团队没有选择传统的“数据清洗-标准化-存储”路径,而是训练了一个基于Transformer架构的生成式AI模型,该模型能自动理解不同系统数据的语义(将“设备A的故障代码E001”转换为“液压系统压力超标”),并生成符合工业标准的合成数据,这些合成数据不仅用于填充缺失值(如某设备因传感器故障缺失了2小时的温度数据),还能模拟极端工况(如高温、高湿、高负荷叠加)下的设备表现,为数字孪生体提供更全面的训练样本,据三一重工公开数据,该项目使数字孪生体的数据利用率从40%提升至85%,模型训练时间缩短60%。
 户外活动与健身运动及AIGC内容热度持续上升,相关领域迎来新机遇
户外活动与健身运动及AIGC内容热度持续上升,相关领域迎来新机遇
本月碳捕捉与绿色供应链圈领域取得重要进展,行业关注度持续提升 技术逻辑:生成式AI的“数据生成”能力源于其对数据分布的深度理解,以扩散模型(Diffusion Model)为例,它能通过“加噪-去噪”的过程,从少量真实数据中生成大量符合分布规律的合成数据,在工业场景中,这一能力被用于解决“长尾问题”——某型号数控机床的故障数据中,90%是“刀具磨损”,但只有1%是“主轴轴承损坏”,传统模型会因数据不平衡而忽略后者;而生成式AI能通过生成更多“主轴轴承损坏”的合成数据,平衡数据分布,提升模型对罕见故障的识别能力,2026年,这一技术已在航空发动机、风电齿轮箱等高价值设备的预测性维护中广泛应用。
知识点三:生成式AI如何让数字孪生体从“辅助工具”变为“决策主体”?
早期的数字孪生体主要用于“监控”和“仿真”,决策仍需人工介入;而2026年的工业实践中,生成式AI正推动数字孪生体向“自主决策”进化——它不仅能预测问题,还能直接生成解决方案,甚至与物理实体闭环交互,实现“虚拟决策-物理执行”的自动循环。

案例:特斯拉上海超级工厂的“AI调度员”
特斯拉上海工厂在2026年上线了基于生成式AI的数字孪生调度系统,该系统整合了生产线上的所有变量(订单需求、设备状态、物料库存、人员排班等),通过生成式AI生成“最优生产计划”,当某款车型的订单突然增加时,系统不会简单调整产线速度,而是通过模拟不同方案(如“增加夜班班次”“调用备用设备”“调整其他车型生产顺序”)的产出、成本和设备损耗,最终生成一个兼顾效率与设备健康的计划,更关键的是,这一计划会直接下发至PLC控制系统,自动调整机械臂参数、AGV小车路线等,实现从“虚拟决策”到“物理执行”的全自动闭环,据特斯拉官方数据,该系统使工厂产能利用率提升15%,同时将设备非计划停机时间减少30%。
技术逻辑:生成式AI的“决策生成”能力依赖于“强化学习+大语言模型”的融合架构,强化学习负责优化决策目标(如“最大化产能”“最小化成本”),大语言模型负责将复杂工业规则(如“设备维护周期”“安全操作规范”)转化为可执行的约束条件,在化工生产中,反应釜的温度、压力、搅拌速度需要满足严格的工艺要求,传统模型需人工编写大量规则,而生成式AI能通过大语言模型理解“工艺文件”中的自然语言描述,自动生成符合约束的决策方案,2026年,这一技术已在半导体制造、生物医药等高精度工业领域得到验证。
实践中的挑战:生成式AI不是“万能药”
尽管生成式AI为数字孪生体带来了革命性突破,但2026年的工业实践也暴露了其局限性,在某汽车零部件厂的案例中,基于生成式AI的数字孪生体曾因“数据偏差”导致错误决策——该厂的部分传感器因老化出现数据漂移,生成式AI模型误将“异常数据”视为“正常工况”,导致设备故障未被及时预警,这一事件促使行业重新思考:生成式AI的“黑箱”特性如何与工业场景的“高可靠性”要求平衡?2026年,主流解决方案是“可解释AI+人工审核”——即通过SHAP值、LIME等工具解释模型决策逻辑,同时保留人工干预权限,确保关键决策的可靠性。
另一个挑战是算力成本,生成式AI模型(尤其是大语言模型)的训练需要大量GPU资源,2026年,单次训练成本仍高达数十万美元,这对中小企业构成门槛,为此,行业正在探索“轻量化模型+边缘计算”的路径——将模型压缩至100MB以内,部署在工厂边缘服务器上,实现实时决策的同时降低算力需求。 本月关注节能减排与环境税及平台治理发展动态,技术创新推动产业升级
数字孪生体的“生成式AI时代”才刚刚开始
从西门子的“自进化模型”到三一重工的“数据宇宙”,从特斯拉的“AI调度员”到汽车厂的“可解释决策”,2026年的工业实践证明:生成式AI不是数字孪生体的“附加功能”,而是推动其从“工具”向“生命体”进化的核心引擎,这场变革的终极目标,是构建一个“物理世界与虚拟世界实时交互、自主进化”的工业元宇宙——在那里,每一台设备、每一条产线、每一座工厂都有自己的“数字分身”,它们能感知、能思考