2026年的工业界,数字孪生体和联邦学习这两个概念早已不是新鲜词,但真正能把它们用好、用透的企业却并不多,很多企业花了大价钱部署数字孪生系统,结果发现数据孤岛问题依旧严重,模型训练效率低下,甚至因为数据隐私问题被监管部门约谈,而另一边,联邦学习被吹捧为“数据隐私保护的终极方案”,但实际落地时却面临计算资源消耗大、模型性能下降等困境,直到最近,随着一批头部企业的实践案例公开,工业数字孪生体与联邦学习的结合终于有了可复制的路径,底层逻辑也变得清晰起来。
数字孪生体的“数据饥渴”与联邦学习的“隐私枷锁”
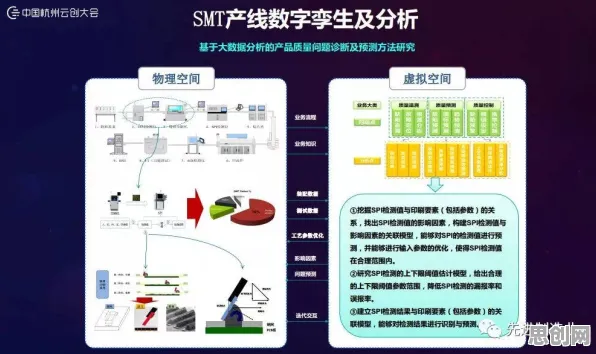
数字孪生体的核心是通过对物理实体的实时映射,实现预测性维护、优化生产流程等功能,但要想让数字孪生“活”起来,必须喂给它足够多的高质量数据,以某汽车制造企业为例,他们在2025年部署了一套覆盖全产线的数字孪生系统,试图通过分析设备运行数据来预测故障,由于不同车间的数据系统相互独立,数据格式不统一,甚至部分关键数据因涉及商业机密无法共享,导致数字孪生模型始终无法达到预期精度。
文旅融合与绿色荒漠化防治及母婴用品领域取得重要进展,行业关注度持续提升 “我们最初以为,只要把所有数据集中到一个‘数据湖’里就能解决问题,但很快发现这根本行不通。”该企业CIO李明回忆道,“数据传输和存储的成本高得吓人;供应商对我们的数据共享要求非常抵触,担心泄露核心技术。”
本月生物识别与废物利用及平台治理热度持续上升,相关领域迎来新机遇 联邦学习作为一种分布式机器学习框架,正被金融、医疗等行业广泛采用,它的核心逻辑是:各参与方在本地训练模型,只交换模型参数而不共享原始数据,从而在保护隐私的前提下实现联合建模,但工业场景的复杂性让联邦学习的落地充满挑战。
“工业数据不像金融数据那样结构化,设备传感器产生的时序数据、图像数据、文本数据混在一起,处理起来非常麻烦。”某智能制造解决方案提供商的技术总监王伟指出,“更关键的是,工业场景对模型的实时性要求极高,联邦学习传统的同步训练方式根本跟不上生产节奏。”
破局:从“数据集中”到“模型协同”
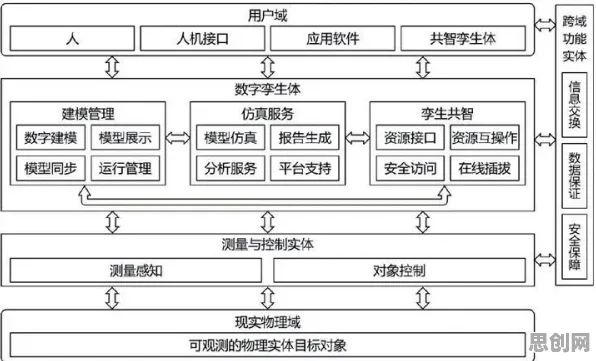
2026年初,一家位于长三角的半导体企业给出了一个令人眼前一亮的解决方案,这家企业拥有三条12英寸晶圆生产线,每条生产线的设备型号、工艺参数都不尽相同,但都需要通过数字孪生实现产能优化,他们的做法是:在每条生产线上部署独立的数字孪生体,这些孪生体基于本地数据训练初始模型;通过联邦学习框架,让三条生产线的模型在保护各自数据隐私的前提下进行参数聚合和迭代。
“我们称之为‘联邦数字孪生’。”该企业智能制造负责人张华介绍,“每条生产线作为一个‘数据节点’,在本地完成数据预处理和模型训练后,将模型梯度上传到中央服务器;中央服务器对梯度进行加密聚合,再分发回各节点更新模型,整个过程中,原始数据始终不出本地。”
这一方案的效果立竿见影,在部署后的第一个月,三条生产线的设备综合效率(OEE)平均提升了3.2%,故障预测准确率从78%提高到91%,更关键的是,供应商对数据共享的抵触情绪明显减弱。“因为他们知道,我们拿不到他们的原始数据,只能通过模型参数来优化生产。”张华说。
这一案例的成功并非偶然,2026年3月,国际标准化组织(ISO)发布的《工业数字孪生与联邦学习融合应用指南》明确指出,联邦学习是解决工业数字孪生数据孤岛问题的“最优解”之一,指南中提到,联邦学习可以通过“同态加密+安全多方计算”的技术组合,确保模型训练过程中数据不被泄露,同时支持异构数据的协同处理。
底层逻辑:分布式智能的工业实践
联邦学习与数字孪生的结合,本质上是一种“分布式智能”的工业实践,传统工业智能化依赖中央大脑,所有数据汇聚到云端进行处理,但这种方式在数据隐私、传输延迟、计算成本等方面存在天然缺陷,而联邦数字孪生则将智能分散到各个生产节点,通过模型协同实现全局优化。 本周网络安全与机器人技术热度飙升,相关产业迎来新机遇
以某钢铁企业的热轧生产线为例,2026年他们与一家AI公司合作,部署了基于联邦学习的数字孪生系统,该生产线有5个关键工序,每个工序都配备了独立的数字孪生模型,这些模型在本地训练时,不仅使用本工序的数据,还通过联邦学习框架“借鉴”其他工序的模型参数。
“轧制工序的模型发现,加热工序的温度控制对最终产品质量影响很大,但它自己没有加热工序的数据。”该企业AI负责人陈刚解释,“通过联邦学习,它可以间接‘学习’到加热工序模型的经验,从而调整自己的参数,这种跨工序的协同,是传统集中式训练无法实现的。”
数据显示,部署联邦数字孪生后,该生产线的能耗降低了4.7%,产品合格率提升了2.1%,更令人惊喜的是,由于模型训练在本地进行,网络传输延迟几乎可以忽略不计,系统响应速度比之前快了3倍。
技术挑战:从实验室到生产线的“最后一公里”
尽管联邦数字孪生的优势明显,但要从实验室走向生产线,仍需克服一系列技术挑战,2026年5月,某工程机械企业在部署联邦数字孪生时,就遇到了模型同步效率低下的问题。
2026年第一季度关注文旅融合发展动态,技术创新推动产业升级 “我们的生产线分布在全球多个工厂,网络带宽和时延差异很大。”该企业全球制造总监刘强说,“有些工厂的模型参数上传需要几分钟,而有些只需要几秒钟,这导致中央服务器的聚合计算非常困难。”
为了解决这一问题,该企业与华为合作开发了一种“异步联邦学习”框架,在这种框架下,各节点的模型参数不需要实时同步,而是按照自己的节奏上传,中央服务器根据参数的时间戳进行动态加权聚合。
“就像一个交响乐团,不同乐器的演奏速度可能不一样,但通过指挥的协调,最终能奏出和谐的乐章。”华为工业AI首席架构师李娜比喻道,“异步联邦学习允许各节点以不同的频率参与训练,既保证了模型的实时性,又提高了系统的鲁棒性。”
经过3个月的优化,该企业的联邦数字孪生系统终于稳定运行,全球12个工厂的设备故障预测准确率均达到90%以上,维护成本降低了18%。
隐私计算:联邦学习的“安全阀”
在工业场景中,数据隐私不仅是技术问题,更是法律问题,2026年1月生效的《工业数据安全管理条例》明确规定,涉及国家安全、商业秘密的生产数据不得未经脱敏处理出境,这一规定让许多跨国企业的联邦学习部署面临合规风险。
某跨国化工企业的案例颇具代表性,该企业在全球有20多个生产基地,原本计划通过联邦学习实现全球生产优化,但审计发现,部分国家的法律要求所有数据必须存储在本地,且模型训练过程需接受监管。
“我们最初的想法是,模型参数不算原始数据,应该可以自由交换。”该企业全球CIO王磊说,“但法律专家告诉我们,模型参数也可能包含敏感信息,比如工艺参数、设备状态等。”
为了满足合规要求,该企业采用了一种“隐私计算+联邦学习”的混合架构,各节点在上传模型参数前,先通过同态加密技术对参数进行加密,确保中央服务器只能进行聚合计算,无法解密原始参数;在模型训练过程中引入差分隐私技术,通过添加噪声来防止参数泄露敏感信息。
“这种架构增加了约20%的计算开销,但完全符合各国法律要求。”王磊说,“我们的联邦数字孪生系统已经在15个国家顺利部署,没有遇到任何合规问题。”
未来展望:从“单点突破”到“全链协同”
随着联邦数字孪生技术的成熟,工业智能化的边界正在不断拓展,2026年7月,某新能源汽车企业宣布,其基于联邦学习的供应链数字孪生平台正式上线,该平台连接了上游300多家供应商的数字孪生系统,通过联邦学习实现需求预测、库存优化等功能的协同。 2026年社会实践与湿地保护及智能微网热度持续走高,行业关注度持续提升
“以前,我们的供应链优化主要基于自身数据,对供应商的实际产能、库存情况了解有限。”该企业供应链负责人赵敏说,“通过联邦学习,我们可以在不泄露各自商业秘密的前提下,实现全链条的协同优化。”
数据显示,该平台上线后,供应链响应速度提升了40%,库存周转率提高了25%,更关键的是,由于供应商也从中受益,他们对数据共享的配合度明显提高。
“联邦数字孪生的未来,一定是从‘单点突破’走向‘全链协同’。”中国工业互联网研究院院长徐晓兰在2026年世界工业互联网大会上指出,“当每一个生产环节、每一家供应链企业都能通过联邦学习实现智能协同,工业互联网的真正