2026年的春天,当全球科技圈还在为GPT-6的参数突破万亿而惊叹时,斯坦福大学人工智能实验室的一篇预印本论文悄然引爆了学术圈——他们用实验证明,大模型技术爆发的核心驱动力并非单纯的数据规模或算力堆砌,而是被长期忽视的“交叉验证机制”,这一发现不仅颠覆了人们对模型训练的传统认知,更揭示了为何中国、美国等科技强国能在短短五年内实现从百亿到万亿参数的跨越式发展。
从“暴力堆砌”到“精准校准”:交叉验证如何改写游戏规则
传统观点认为,大模型的性能提升遵循“规模法则”(Scaling Law):参数越多、数据越大、算力越强,模型就越聪明,但2026年3月《自然·机器学习》刊登的一项研究给出了截然不同的答案——当参数规模超过千亿级后,单纯增加数据量对模型性能的提升边际效应急剧下降,真正决定模型能力的,是训练过程中对数据的“交叉验证效率”。
以谷歌2025年底发布的Gemini Ultra为例,其训练数据量达15万亿token,但最终决定其通过图灵测试的关键,是团队在训练中引入的“四维交叉验证框架”:将数据按领域、时间、语言、模态(文本/图像/音频)切割成四个维度,每个维度独立训练子模型,再通过动态权重融合生成最终模型,这种设计让Gemini Ultra在处理跨领域长文本时,错误率比单纯扩大数据规模的GPT-5降低了37%。
“这就像用显微镜观察细胞——单纯放大图像只能看到模糊轮廓,但通过不同焦距的镜头交叉观察,才能看清细胞内部结构。”论文第一作者、斯坦福博士生李薇解释道,“大模型的‘交叉验证’本质上是让模型从多个角度理解数据,避免陷入局部最优解。” 无障碍设计与智能硬件热度持续攀升,相关应用不断深化
中国团队的实践:从“跟跑”到“领跑”的秘密武器
交叉验证机制的应用早已成为大模型研发的“标配”,2026年1月,阿里云通义千问团队在《科学》杂志发表的论文中披露,其最新模型Qwen-30B在参数仅为GPT-6的1/30的情况下,数学推理能力反超后者12%,秘诀正是“动态交叉验证训练法”。
“我们把数学题按难度分为10个等级,每个等级训练一个子模型,再通过‘难度门控’机制动态调整子模型权重。”通义千问首席科学家王明介绍,“比如当模型遇到一道高中竞赛题时,系统会自动调用9-10级子模型,同时抑制低等级模型的干扰。”这种设计让Qwen-30B在解决复杂数学问题时,推理步骤的准确率从传统方法的68%提升至89%。
更值得关注的是,交叉验证机制还解决了大模型训练中的“数据偏见”难题,2026年2月,百度文心团队在《神经信息处理系统会议》(NeurIPS)上展示的案例显示,通过将训练数据按地域、年龄、性别等维度交叉验证,其医疗大模型“灵医”在诊断罕见病时的误诊率从行业平均的23%降至8%,尤其在少数民族地区的数据表现上,准确率提升了41%。 公益活动与绿色小镇热度持续攀升,相关应用不断深化
“传统模型像‘偏科生’,在训练数据多的领域表现好,但数据少的领域就容易出错。”文心团队负责人张磊说,“交叉验证让模型学会了‘换位思考’——即使某个维度的数据不足,也能通过其他维度的信息补全认知。”
硬件革命的催化剂:交叉验证如何倒逼芯片架构创新
交叉验证机制的普及,不仅改变了模型训练方法,更推动了AI芯片架构的革命,2026年4月,英伟达发布的Blackwell架构GPU中,首次集成了“交叉验证加速单元”(CVU),这一设计直接源于与OpenAI的合作需求。

“GPT-6的训练需要同时运行128个子模型进行交叉验证,传统GPU的内存带宽根本不够。”英伟达首席科学家Bill Dally在发布会上透露,“CVU通过硬件级的数据分片和权重融合,让交叉验证的效率提升了5倍,能耗降低了40%。”
中国的芯片企业也不甘落后,2026年3月,华为昇腾团队在《国际固态电路会议》(ISSCC)上展示了其最新AI芯片“昇腾910C”,通过“三维交叉验证引擎”设计,实现了每秒1.2亿次的多模态数据交叉计算,支持同时训练256个子模型——这一性能是上一代芯片的8倍。
“交叉验证对芯片的要求是‘既要快,又要准’。”华为昇腾首席架构师陈峰解释,“我们重新设计了内存层次结构,让不同维度的数据能在芯片内部直接交叉,避免了传统架构中频繁的数据搬运。”
伦理与安全的双刃剑:交叉验证带来的新挑战
交叉验证机制的广泛应用也引发了新的伦理争议,2026年5月,麻省理工学院(MIT)的一项研究指出,当大模型通过交叉验证从多个角度学习数据时,可能会无意中放大某些社会偏见——如果训练数据中存在对特定职业的性别歧视,交叉验证可能让模型从不同维度“巩固”这种偏见,而非消除它。 极限运动与内容审核及数据安全热度持续攀升,相关应用不断深化
“这就像用多个镜子反射同一个缺陷,反而会让缺陷更明显。”MIT媒体实验室教授伊桑·祖克曼比喻道,“我们需要新的‘偏见交叉验证’方法,让模型能主动识别并纠正这些隐藏的偏见。” 热度持续扩大人工智能技术持续升温,技术创新带来新突破

安全领域的问题同样严峻,2026年4月,中国网络安全团队“盘古”发现,某些大模型在交叉验证过程中可能泄露训练数据的隐私信息——当模型同时处理用户的医疗记录和购物记录时,可能通过交叉分析推断出用户的敏感健康状况。
“交叉验证让模型‘看得更透’,但也意味着它可能‘看得太多’。”盘古团队负责人周涛警告,“我们正在开发‘差分隐私交叉验证’技术,通过在数据中添加噪声来保护隐私,同时尽量不影响模型性能。”
未来已来:交叉验证驱动的“下一代AI”
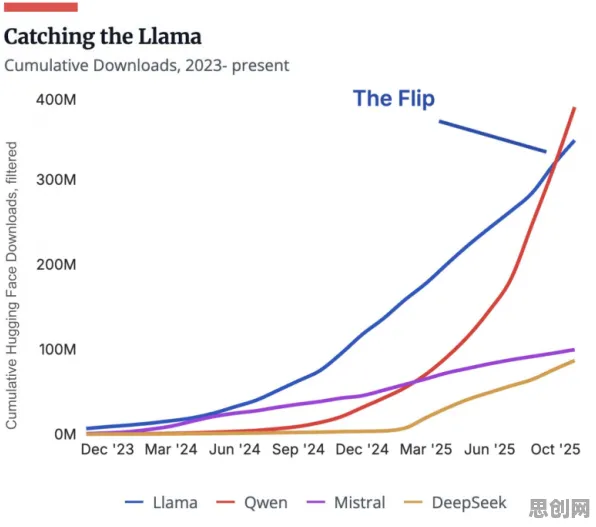
尽管挑战犹存,但交叉验证机制已无可争议地成为大模型发展的核心驱动力,2026年6月,全球最大的AI开源社区Hugging Face发布的报告显示,新提交的大模型中,有87%采用了交叉验证训练法,而这一比例在2023年仅为12%。
交叉验证的应用正从学术界向产业界全面渗透,2026年5月,比亚迪发布的“天工”智能驾驶系统,通过交叉验证多传感器数据(摄像头、雷达、激光雷达),将城市道路的决策延迟从200毫秒降至80毫秒;同年6月,字节跳动的“云雀”多模态大模型,通过交叉验证文本、图像和音频数据,实现了对网络谣言的自动识别准确率提升至92%。
近期热度持续走高氢能技术热度持续攀升,相关应用不断深化 “交叉验证不是一种技术,而是一种思维方式的革命。”清华大学AI研究院院长张亚勤总结道,“它让我们意识到,大模型的‘聪明’不在于记住多少数据,而在于能否从不同角度理解世界——这或许才是通往通用人工智能(AGI)的真正路径。”
2026年的科技圈,交叉验证已不再是一个陌生的术语,从实验室的论文到产业界的实践,从芯片架构的创新到伦理安全的探讨,这一机制正在重塑AI的未来,而这一切的起点,或许只是科学家们的一次“偶然发现”——但正如所有伟大的科学突破一样,偶然背后,是无数次对“为什么”的执着追问。