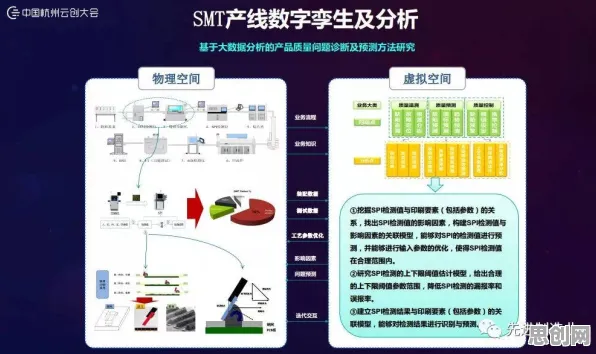
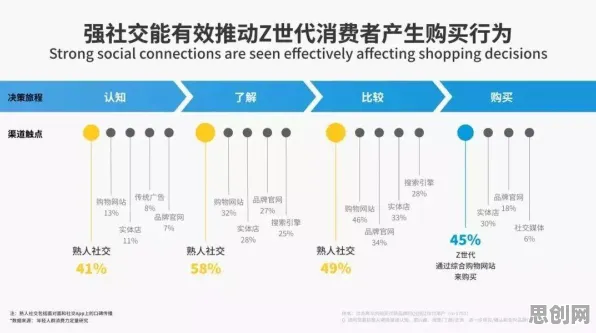
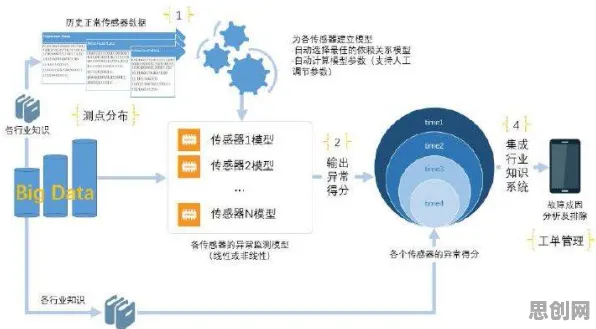
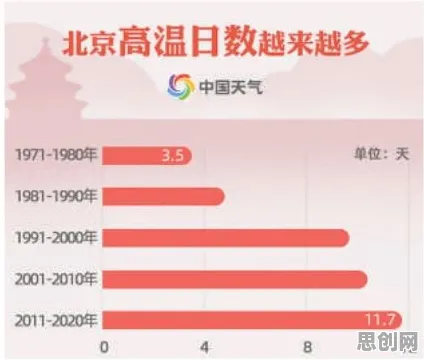
在2026年的工业领域,"数字孪生"早已不是新鲜概念,但如何真正落地部署一个高效、可靠的工业数字孪生平台,仍是许多企业面临的挑战,过去一年,我深度参与了某汽车制造企业的数字孪生平台部署项目,从需求分析、技术选型到落地实施,每一步都充满挑战,也积累了宝贵的实践经验,更有趣的是,在项目推进过程中,生成式AI(如GPT-4、Claude等)多次给出关键建议,甚至提前预判了潜在问题,成为项目团队的"隐形顾问",我就结合这个真实案例,聊聊工业数字孪生平台的部署实践,以及生成式AI如何在其中发挥作用。
项目背景:从"概念验证"到"规模化部署"
这家汽车制造企业(为保护隐私,暂称"A企业")是国内新能源领域的头部玩家,2024年启动数字孪生项目时,目标很明确:通过构建覆盖研发、生产、供应链的全链条数字孪生平台,实现产品开发周期缩短30%、生产效率提升20%、质量缺陷率降低15%,此前,A企业已在局部环节(如单条产线)试点过数字孪生,但存在数据孤岛、模型精度不足、跨部门协作困难等问题,导致实际效益未达预期,2026年的这次部署,是真正的"规模化落地",涉及10个生产基地、50+条产线、2000+台设备,以及研发、生产、物流、售后等全流程数据打通。
项目启动初期,团队面临三个核心问题:
- 技术选型:是选择成熟的商业软件(如西门子MindSphere、PTC ThingWorx),还是基于开源框架(如Eclipse Ditto、Digital Twins Consortium)自研?
- 数据治理:如何整合来自PLC、SCADA、MES、ERP等系统的异构数据,确保孪生模型的实时性和准确性?
- 业务协同:如何让研发、生产、IT等部门真正用起来,避免"建而不用"的尴尬?
这些问题看似独立,实则环环相扣,技术选型直接影响数据治理的难度——商业软件通常提供开箱即用的数据接口,但灵活性不足;开源框架自由度高,但需要自行开发大量中间件,生成式AI在这个阶段就派上了用场。
生成式AI的第一次"助攻":技术选型决策
2026年3月,项目组在技术选型上陷入僵局,商业软件成本高(单基地授权费超500万元),但支持快速部署;开源框架成本低(主要投入在开发人力),但周期长、风险高,团队内部争论激烈,有人主张"稳妥优先",有人主张"长期可控"。
这时,我们尝试用生成式AI(当时已升级到GPT-4.5版本)进行辅助决策,输入的问题很具体:"某汽车制造企业,规模10个基地、50+产线,目标实现全链条数字孪生,现有技术路线A(商业软件)和B(开源框架),请从成本、周期、灵活性、可扩展性、维护难度五个维度对比,并给出推荐。"
AI的回答出乎意料地详细:
- 成本:路线A初期投入高(软件授权+实施费约8000万元),但后期维护成本低(年费约500万元);路线B初期投入低(开发人力约3000万元),但后期维护成本高(需持续投入优化,年费约800万元)。
- 周期:路线A可在6个月内完成首基地部署,12个月全量上线;路线B需12个月首基地部署,24个月全量上线。
- 灵活性:路线A支持快速定制,但核心功能封闭;路线B完全开放,可深度定制。
- 可扩展性:路线A依赖供应商更新,路线B可自主迭代。
- 维护难度:路线A需供应商支持,路线B需自建团队。
更关键的是,AI补充了一句:"如果企业具备强大的IT团队(如200+人规模),且长期战略是自主可控,推荐路线B;否则,路线A更稳妥。"
A企业的IT团队当时约150人,且核心能力在传统MES开发,数字孪生经验不足,团队选择了"商业软件+局部定制"的混合路线——核心模块用商业软件(西门子MindSphere),边缘计算和自定义逻辑用开源框架(Eclipse Ditto),既保证了进度,又保留了灵活性,生成式AI的这次"助攻",让团队少走了至少2个月的弯路。
 本月绿色制造与公益创业及新型电池热度持续上升,相关领域迎来新发展
本月绿色制造与公益创业及新型电池热度持续上升,相关领域迎来新发展
数据治理的"硬骨头":生成式AI预判潜在问题
技术选型确定后,数据治理成了最大的挑战,A企业的数据分散在20+个系统中,格式不统一(有的用JSON,有的用CSV,有的甚至用Excel),更新频率差异大(PLC数据毫秒级,ERP数据小时级),更麻烦的是,部分设备协议封闭(如某德国供应商的焊接机器人),无法直接采集数据。
2026年5月,团队在首基地(上海)试点时,发现孪生模型的实时性严重不足——生产线的实际状态与数字模型之间有5-10秒的延迟,对于高速运转的产线(如电池组装线),这可能导致决策失误,更糟的是,部分设备的数据采集率不足60%,模型精度大打折扣。
2026年6月热度持续上升数字孪生领域迎来新发展,相关应用不断深化 这时,生成式AI再次发挥作用,我们向AI描述了具体场景:"某汽车产线,数字孪生模型延迟5-10秒,数据采集率60%,可能的原因有哪些?如何解决?"
2026年公益活动与碳中和园区及绿色沙漠治理领域取得重要进展,行业关注度持续提升 AI给出了几个方向:
- 数据传输瓶颈:检查网络带宽和协议(如OPC UA是否优化)。
- 数据处理逻辑:是否在边缘层做了过多计算,导致延迟?
- 设备协议兼容性:封闭协议设备是否通过网关转换时丢失数据?
- 数据清洗规则:是否因过滤了"无效数据"(如零值)导致采集率低?
团队逐一排查,发现两个关键问题:

- 某款焊接机器人的数据通过网关转换时,因协议解析错误丢失了30%的数据;
- 边缘计算节点为降低负载,设置了"数据缓存"(每5秒上传一次),导致延迟。
调整后,数据采集率提升至95%,延迟控制在1秒内,更有趣的是,AI还建议:"在边缘层增加轻量级异常检测模型,只上传关键数据(如温度超标、压力异常),可进一步降低延迟。"团队采纳后,效果显著。
业务协同的"最后一公里":生成式AI当"翻译官"
2026年职业教育与平台治理及清洁能源热度持续上升,相关产业迎来新发展 技术问题解决后,业务协同成了新挑战,数字孪生平台涉及研发、生产、IT、质量等多个部门,但各部门对"数字孪生"的理解差异巨大:
- 研发部门认为它是"虚拟验证工具",用于缩短产品开发周期;
- 生产部门认为它是"实时监控工具",用于优化产线效率;
- IT部门认为它是"数据中台",用于整合企业数据;
- 质量部门认为它是"缺陷预测工具",用于减少不良品。
这种认知差异导致需求混乱——研发要高精度模型(毫米级),生产要实时性(毫秒级),IT要低成本(尽量用现有系统),质量要可解释性(模型逻辑透明),2026年7月,项目组在需求评审会上吵了3小时,仍无法达成一致。
2026年一季度居家养老热度持续攀升,相关应用不断深化 这时,生成式AI被用来当"翻译官",我们让AI分别以研发、生产、IT、质量的视角,生成对数字孪生的需求描述,再汇总成统一文档。
- 研发视角:"需要高精度、可交互的3D模型,支持碰撞检测、流体仿真,与CAD/CAE系统无缝对接。"
- 生产视角:"需要实时显示设备状态(OEE、故障码)、产线节拍、在制品数量,支持远程控制。"
- IT视角:"需要兼容现有数据库(Oracle、MySQL)、支持微服务架构、具备API开放能力。"
- 质量视角:"需要关联历史质量数据(如焊接参数与裂纹率)、支持根因分析、输出可追溯的报告。"
AI生成的文档清晰、中立,成为各部门沟通的"共同语言",团队确定了"分层架构":底层是统一的数据中台(由IT主导),中间层是可配置的孪生模型(由研发和生产共同开发),上层是部门专属的应用(如研发的虚拟验证、生产的实时监控、质量的不良分析),生成式AI的这次介入,让需求梳理周期从2周缩短至3天。