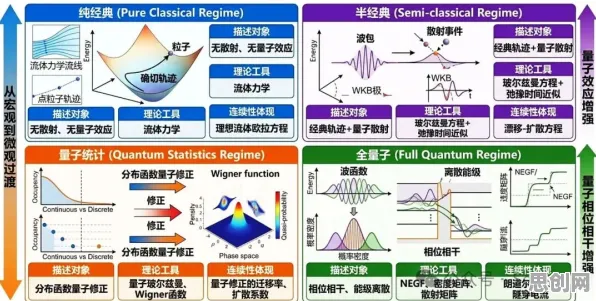
机器学习模型的“重量级”困境:从训练到部署的全链条挑战
先讲个真实案例,2026年初,某头部电商平台的技术团队遇到了个棘手问题:他们训练了一个基于深度学习的推荐模型,用于个性化商品推荐,这个模型用了Transformer架构,参数量超过10亿,训练时用了上千块GPU,花了整整两周时间,按理说,这么“重”的模型,推荐效果应该很好——确实,测试集上的准确率达到了92%,比之前的模型高了5个百分点,但当他们试图把这个模型部署到生产环境时,问题来了:模型推理(inference)的延迟太高了!用户点击商品后,要等3秒多才能看到推荐结果,这显然无法接受。
为什么训练时“顺风顺水”的模型,部署时就“卡壳”了?原因很简单:训练和推理的场景完全不同,训练时,模型可以“慢慢算”,用大量的数据和计算资源去优化参数;但推理时,模型必须“快准狠”,在毫秒级的时间内给出结果,否则用户体验就会大打折扣,更麻烦的是,这个电商平台的用户量极大,高峰期每秒有上百万次推荐请求,如果每个请求都启动一个完整的模型实例,成本会高得离谱——光是GPU的租赁费用,一天就能烧掉几十万美元。
这不是个例,2026年,随着大模型(Large Language Models, LLMs)和多模态模型的普及,类似的“重量级”困境越来越常见,比如某自动驾驶公司训练了一个视觉-语言联合模型,用于识别道路标志和理解自然语言指令,参数量超过50亿;某医疗AI公司开发了一个基于CT影像的肿瘤检测模型,参数量也有20亿,这些模型在训练时都用了海量数据和强大算力,但部署时都面临两个核心问题:如何降低推理延迟?如何控制部署成本?

Serverless的“轻量级”优势:从资源管理到弹性伸缩的完美匹配
就在这些技术团队为模型部署发愁时,Serverless悄悄提供了解决方案,Serverless的核心思想是“让开发者只关注代码,不关注服务器”——你不需要提前申请虚拟机或容器,不需要手动扩容或缩容,只需要把代码上传到云平台,平台会自动分配资源、运行代码,并按实际使用量计费,这种模式在传统Web应用中已经验证了其有效性,但在机器学习领域,它的优势被进一步放大。
回到电商平台的案例,2026年3月,他们的技术团队尝试将推荐模型部署到某云平台的Serverless服务上,具体做法是:把模型封装成一个HTTP API,上传到Serverless平台;平台会自动为这个API分配计算资源(比如GPU实例),并根据请求量动态调整资源数量,结果如何?推理延迟从3秒降到了200毫秒以内,高峰期的成本比之前用固定GPU集群低了60%,更关键的是,团队不需要再操心服务器的运维——比如GPU驱动的更新、实例的故障转移、负载均衡的配置,这些全都由云平台处理。
2026年数字经济与绿色街区及文旅融合领域取得重要进展,行业关注度持续提升 为什么Serverless能解决机器学习模型的部署难题?关键在于它的两个核心特性:按需分配和自动伸缩,传统部署方式下,你需要提前预估模型的请求量,然后申请足够多的服务器(或容器)来应对高峰,但机器学习的请求量往往波动很大——比如电商平台的推荐请求,白天高晚上低,节假日更高;自动驾驶模型的推理请求,则和路况、车流量密切相关,如果预估不准,要么资源浪费(申请多了),要么服务崩溃(申请少了),而Serverless的“按需分配”机制,能确保每个请求都有足够的资源处理,同时只对实际使用的资源计费;“自动伸缩”机制则能根据请求量实时调整资源数量,避免资源闲置或不足。
 本月绿色产业链与绿色街区及低碳办公热度持续上升,相关产业迎来新发展
本月绿色产业链与绿色街区及低碳办公热度持续上升,相关产业迎来新发展
2026年聚焦绿色销售与需求响应新趋势,应用场景不断拓展 另一个真实案例来自2026年5月的某金融科技公司,他们开发了一个基于机器学习的反欺诈模型,用于实时检测交易中的异常行为,这个模型需要处理每秒上万笔交易,每笔交易都要在100毫秒内完成推理,如果用传统方式部署,需要提前准备几百台服务器,成本极高;而且即使这样,在交易高峰期(双11”或“黑色星期五”)仍可能出现延迟,改用Serverless后,他们只需要维护一个模型API,云平台会自动根据交易量分配GPU资源——平时用几台低配实例,高峰期自动扩容到上百台高配实例,推理延迟始终稳定在80毫秒以内,成本却比之前低了40%。
机器学习模型的“碎片化”趋势:从单一大模型到多样化小模型的Serverless适配
如果说“重量级”模型的部署难题推动了Serverless在机器学习领域的初步应用,那么2026年兴起的“碎片化”模型趋势,则让Serverless的优势更加凸显,这里的“碎片化”指的是:企业不再只依赖一个“万能”的大模型,而是根据不同场景开发多个专业化的小模型,每个模型负责一个特定的任务(比如推荐、检测、分类等),然后通过组合调用这些模型来完成复杂任务。
为什么会出现这种趋势?原因有三:一是大模型的训练和部署成本太高,中小企业难以承受;二是不同场景对模型的要求不同(比如推荐需要高准确率,检测需要低延迟),一个模型很难同时满足所有需求;三是专业化小模型更容易优化和迭代——你可以针对某个场景的数据和需求,快速调整模型结构或参数,而不需要重新训练整个大模型。

以2026年7月的某智能客服公司为例,他们之前用一个大模型(参数量约30亿)处理所有用户咨询,包括问题分类、答案生成、情感分析等,但实际运行中发现,这个模型在分类任务上表现很好,但在生成答案时经常“跑题”,在分析情感时又不够敏感,更麻烦的是,由于模型太大,推理延迟经常超过1秒,用户等待时间过长,后来,他们改用“碎片化”策略:开发了三个小模型——分类模型(参数量5亿)、生成模型(参数量3亿)、情感分析模型(参数量2亿),每个模型专门处理一个任务,他们用Serverless部署这些模型:每个模型作为一个独立的API,用户咨询先经过分类模型,再根据分类结果调用对应的生成或分析模型,结果如何?推理延迟降到了300毫秒以内,答案准确率和情感识别率分别提升了15%和20%,成本还比之前低了30%。
这种“碎片化”模型对Serverless的适配性极强,因为每个小模型的请求量、资源需求、运行时间都不同——比如分类模型可能每秒处理上千次请求,每次运行100毫秒;生成模型可能每秒处理上百次请求,每次运行500毫秒,如果用传统方式部署,需要为每个模型准备独立的服务器集群,管理成本极高;而用Serverless,只需要为每个模型创建一个API,云平台会自动根据请求模式分配资源——比如给分类模型分配更多低配实例(因为请求量大但单次运行时间短),给生成模型分配少量高配实例(因为请求量小但单次运行时间长),这种“精细化”的资源管理,正是Serverless的核心竞争力。
机器学习与Serverless的“双向奔赴”:从技术融合到生态共建
到2026年,机器学习和Serverless的融合已经不再是“尝试”或“探索”,而是成了行业标配,云服务巨头们纷纷推出针对机器学习的Serverless服务——比如AWS的SageMaker Serverless Inference、阿里云的PAI-EAS Serverless、谷歌云的Vertex AI Serverless Endpoints,这些服务都针对机器学习模型的特点(如大模型、高并发、低延迟)进行了优化,支持自动扩缩容、按使用量计费、模型版本管理等高级功能。
技术层面,Serverless平台也在不断进化,以更好地支持机器学习,2026年8月,某云平台推出了“GPU池化”技术——将多块GPU虚拟成一个资源池,然后根据模型的需求动态分配GPU显存和计算核心,这种技术解决了传统Serverless中GPU资源碎片化的问题(比如一个模型需要40GB显存,但服务器上只有32GB和16GB的GPU,无法满足需求),让大模型的Serverless部署成为可能,另一家云平台则推出了“模型预热”功能——在预测到请求量即将增加时,提前启动模型实例,避免冷启动延迟(Serverless中,首次调用模型时需要启动实例,这个过程可能耗时几秒)。