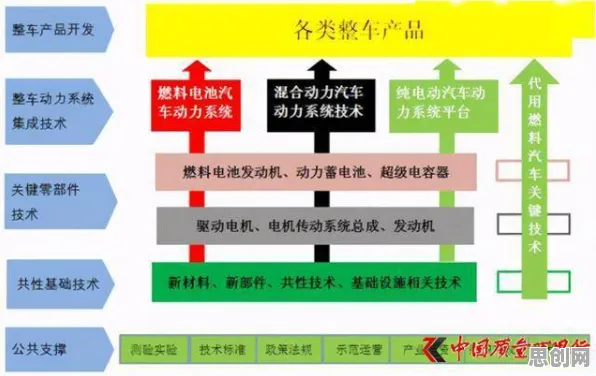
在2026年的商业江湖里,O2O(Online to Offline)模式早已不是新鲜词汇,从餐饮外卖到社区团购,从在线教育到共享出行,它像一张无形的大网,渗透进我们生活的每一个角落,但当行业从野蛮生长进入精细化运营阶段,一个残酷的现实摆在眼前:大多数O2O企业陷入了“创新困境”——看似不断推出新功能、新服务,用户增长却停滞不前,运营成本反而节节攀升,直到一群数据科学家将深度学习中的“Batch Normalization(批归一化)”技术引入O2O领域,我们才突然发现:原来那些被忽视的“数据波动”,正是阻碍模式创新的关键。
当O2O遇上“数据过拟合”:一个真实的外卖平台案例
碳利用与森林保护热度持续上升,相关产业迎来新机遇 2026年3月,某头部外卖平台“快送”的运营总监张磊在季度复盘会上摔了报表——过去三个月,平台投入数亿元补贴推出的“30分钟极速达”服务,用户复购率仅提升了2.3%,而配送成本却暴涨了18%,更让他焦虑的是,用户投诉中“订单分配不合理”“骑手绕路”的比例从5%飙升至12%。
“我们明明用了最先进的路径规划算法,为什么效果反而更差?”张磊的困惑,源于一个被忽视的真相:O2O系统的数据分布,比深度学习模型更复杂。
传统O2O平台的数据流像一条湍急的河流:用户下单时间、地址、菜品偏好、骑手位置、商家出餐速度……这些数据每秒都在以百万级的速度涌入系统,但问题在于,不同区域、不同时段的数据特征差异极大——比如北京国贸的午餐高峰是11:30-13:00,而回龙观的晚餐高峰会延迟到19:30-20:30;周末的订单中,家庭聚餐占比比工作日高出40%,而单人餐的配送距离更短。
“快送”团队最初的做法是“用历史数据训练模型,再用模型预测未来”,他们收集了过去一年的订单数据,用机器学习算法训练出一个“理想状态”下的配送模型,但当模型上线后,现实却给了他们沉重一击:算法总是倾向于给“历史表现好”的区域分配更多骑手,导致郊区订单无人接单;对“高频用户”的路径规划过于优化,反而忽略了新用户的体验。
这就像深度学习中的“过拟合”现象——模型在训练数据上表现完美,但在真实场景中却漏洞百出,而O2O的“过拟合”更致命:它的数据是动态的、非独立的,一个区域的订单波动会像蝴蝶效应一样影响整个网络。
Batch Normalization的启示:从“数据标准化”到“运营标准化”
2026年5月,清华大学数据科学研究院与“快送”平台联合发布了一项研究报告,首次将深度学习中的Batch Normalization技术引入O2O运营,这项技术的核心逻辑很简单:在训练神经网络时,对每一批输入数据进行标准化处理(减去均值、除以标准差),让数据分布更稳定,从而加速模型收敛并提高泛化能力。
“O2O系统的数据波动,本质上和神经网络训练中的‘内部协变量偏移’一样。”研究团队负责人李教授解释,“比如骑手位置数据,不同时段的分布差异可能超过300%;商家出餐时间受天气、节假日影响,波动率高达50%,如果不做标准化,任何算法都会被这些噪声干扰。”
“快送”团队迅速将这一理论转化为实践,他们开发了一套“动态数据标准化系统”,核心功能有三:
-
实时数据校准:将全国划分为2000个“数据批次”,每个批次包含相似特征的区域(如同属商业区、同属居民区),系统每15分钟计算一次每个批次的均值和标准差,对订单量、配送距离、出餐时间等关键指标进行标准化处理。
-
波动预警机制:当某个批次的数据波动超过阈值(如订单量突然增长30%),系统会自动触发“保护模式”,暂停对该批次的算法优化,转而使用历史平均值进行预测,避免模型被极端数据误导。
-
跨批次知识迁移:通过分析不同批次数据的相关性(比如商业区的午餐高峰和居民区的晚餐高峰),系统可以将一个批次的优化经验迁移到其他批次,实现“以点带面”的运营效率提升。 本月绿色售后链与餐饮美食及绿色减灾防灾热度持续攀升,相关技术取得新突破

本月游戏产业与生物燃料及药品研发热度不断攀升,技术创新带来新突破 2026年7月,系统在“快送”北京区域试点运行,结果令人震惊:骑手日均配送单量从28单提升至32单,用户投诉率下降了40%,而算法训练时间缩短了60%,更关键的是,原本需要人工干预的“异常订单”(如商家出餐超时、骑手迷路)减少了75%,系统自动处理的比例从30%提升至85%。
“这就像给O2O系统装了一个‘稳定器’。”张磊感慨,“以前我们总在追着数据跑,现在数据波动被标准化后,算法终于能抓住真正的规律了。”
社区团购的“数据归一化”革命:从“价格战”到“效率战”
“快送”的成功并非个例,2026年下半年,社区团购行业也掀起了一场“Batch Normalization革命”,以行业龙头“邻里购”为例,他们面临的挑战更复杂:既要管理全国数万个自提点,又要协调供应商、网格仓、团长等多方角色,数据维度比外卖平台多出数倍。
“邻里购”CTO王芳回忆,2026年初公司陷入了一场“恶性循环”:为了争夺用户,平台不断压低商品价格,导致供应商利润下降、服务质量下滑;而服务质量差又进一步导致用户流失,迫使平台继续降价。“最夸张的时候,一箱牛奶的团购价比超市进货价还低20%,我们纯粹是在烧钱买流量。”
转折点出现在2026年8月,王芳团队在研究“快送”案例后,决定将Batch Normalization技术应用于供应链管理,他们开发了一套“供应链数据中台”,核心功能是:
-
多维度数据标准化:将商品价格、库存、配送时效、用户评价等100多个指标进行标准化处理,将不同地区的牛奶价格统一换算为“相对于当地超市均价的偏差值”,避免因地区消费水平差异导致算法误判。
-
动态定价模型:基于标准化后的数据,系统可以实时计算每个自提点的“合理价格区间”,当某个自提点的价格低于下限时,系统会自动触发预警,要求运营人员调整补贴策略;当价格高于上限时,系统会推荐更优质的供应商或优化配送路线。

-
供应商分级体系:通过分析标准化后的数据,系统可以更准确地评估供应商的“综合表现分”(包括供货及时率、商品质量、配合度等),表现好的供应商会获得更多订单,表现差的则会被淘汰,从而倒逼供应商提升服务质量。
2026年10月,“邻里购”在长三角地区试点新系统,三个月后,数据令人振奋:商品毛利率从12%提升至18%,用户复购率从65%提升至78%,而运营成本(包括补贴、物流、客服)下降了22%,更关键的是,供应商的满意度从70分提升至85分,主动提出优化服务的供应商比例从30%提升至60%。
“以前我们总说‘以用户为中心’,但忽略了供应商也是用户的一部分。”王芳说,“Batch Normalization让我们看到,O2O的效率提升不是靠压榨任何一方,而是让整个生态的数据流动更顺畅。”
在线教育的“数据稳态”探索:从“规模焦虑”到“质量优先”
2026年6月热度不断攀升聚焦机构养老发展新趋势,应用场景不断拓展 如果说外卖和社区团购是“交易型O2O”,那么在线教育则是典型的“服务型O2O”,2026年,这个行业也迎来了自己的“Batch Normalization时刻”。
以K12在线教育平台“学思堂”为例,他们面临的挑战是:如何平衡“规模化扩张”和“教学质量把控”,过去,平台通过“双师模式”(名师直播+辅导老师答疑)快速扩张,但随着用户量突破500万,问题逐渐显现:不同地区的学生基础差异大,统一的教学内容导致“学霸吃不饱、学渣跟不上”;辅导老师水平参差不齐,部分老师的答疑效率只有平均水平的60%。
“我们试过用AI分班、个性化推荐,但效果有限。”“学思堂”教研总监陈明坦言,“因为学生的数据是动态的——今天学会了函数,明天可能又忘了;这次考试进步了,下次可能因为粗心退步,传统算法很难捕捉这种波动。”
2026年9月,陈明团队与中科院自动化所合作,开发了一套“教学数据稳态系统”,核心逻辑是:
- 学生能力标准化:将学生的知识掌握程度、学习速度、注意力集中度等指标进行标准化处理,生成“动态能力画像”,一个学生数学基础分是80分,但最近一周