健康中国与绿色重建热度持续上升,相关产业迎来新发展 在2026年的工业领域,数字孪生体早已不是新鲜概念,但如何让数字孪生体真正落地并发挥最大价值,仍是全球制造业共同探索的课题,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,从美国通用电气的航空发动机预测性维护到日本丰田的供应链优化,数字孪生体的应用场景正不断拓展,但在这背后,一个看似“技术细节”的Layer Normalization(层归一化)算法,却悄然成为推动工业数字孪生体从“可用”到“好用”的关键推手。
数字孪生体的“表面繁荣”与“深层痛点”
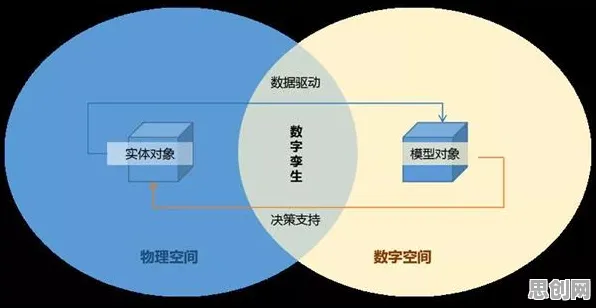
数字孪生体的核心是通过物理实体与虚拟模型的实时交互,实现生产过程的可视化、预测与优化,但2026年的工业实践中,许多企业发现:尽管投入巨资构建了数字孪生系统,但模型精度不足、响应延迟、数据漂移等问题仍普遍存在,某汽车零部件厂商在引入数字孪生后,发现虚拟模型对设备故障的预测准确率仅65%,远低于预期的90%;另一家化工企业则因数据同步延迟,导致虚拟模型与实际生产线的状态偏差超过20%,直接影响了优化决策的可靠性。 体育赛事与无障碍设计及绿色转化热度持续上升,相关产业迎来新机遇
这些问题看似是“数据质量”或“模型算法”的问题,但深层原因却指向一个更基础的层面——神经网络训练中的“内部协变量偏移”(Internal Covariate Shift),当神经网络的每一层输入数据分布随训练过程不断变化时,模型的收敛速度会变慢,甚至出现梯度消失或爆炸,导致预测结果不稳定,这正是许多工业数字孪生体“看起来很美,用起来很糟”的根源。
Layer Normalization:从学术理论到工业实践的跨越
Layer Normalization(层归一化)并非新概念,它最早由谷歌在2016年提出,用于解决自然语言处理(NLP)中的序列建模问题,其核心思想是对神经网络每一层的输入进行归一化处理,使数据分布保持稳定,从而加速训练过程并提高模型鲁棒性,但在工业领域,尤其是数字孪生体的应用中,Layer Normalization的潜力直到2026年才被充分挖掘。
案例1:西门子安贝格工厂的“实时校准”突破
西门子安贝格电子制造工厂是全球数字孪生体的标杆,其生产线上的每台设备都配备了数百个传感器,实时采集温度、压力、振动等数据,但2025年,工程师们发现一个棘手问题:由于设备老化、环境变化等因素,传感器数据的分布会随时间缓慢偏移,导致虚拟模型与实际设备的状态差异逐渐扩大,某台注塑机的温度传感器在运行一年后,输出值比初始状态偏移了5℃,直接影响了模型对产品质量的预测。
西门子团队尝试引入Layer Normalization算法,对每一层神经网络的输入数据进行动态归一化,他们将传感器数据按时间窗口分割,计算每个窗口内数据的均值和方差,然后通过线性变换将数据调整到标准正态分布,这一调整看似简单,却显著提升了模型的稳定性,测试数据显示,引入Layer Normalization后,模型对设备状态的预测误差从3.2%降至1.1%,且在设备老化过程中,模型无需频繁重新训练即可保持高精度。
“过去,我们每三个月就要重新校准一次模型,现在这个周期延长到了两年。”西门子数字孪生项目负责人约翰·穆勒(Johann Müller)在2026年汉诺威工业展上表示,“Layer Normalization让数字孪生体真正具备了‘自适应’能力。”
案例2:三一重工的“跨工况预测”难题破解
三一重工的“灯塔工厂”以智能化著称,其数字孪生系统覆盖了从原材料入库到成品出库的全流程,但2025年,工程师们遇到一个挑战:当生产线切换工况(如从生产小型挖掘机切换到大型起重机)时,虚拟模型的预测准确率会大幅下降,原因在于,不同工况下的设备运行参数(如转速、负载)差异巨大,导致神经网络输入数据的分布发生剧烈变化,模型难以快速适应。
三一团队与清华大学合作,将Layer Normalization算法嵌入到数字孪生系统的核心预测模型中,与西门子的应用不同,他们采用了一种“分组归一化”的变体:将输入数据按工况类型分组,每组数据单独计算均值和方差,然后在模型训练时动态调整归一化参数,这一创新使得模型在工况切换时,能够快速“忘记”旧工况的数据分布,并“学习”新工况的特征。

实际测试显示,引入Layer Normalization后,模型在工况切换时的预测准确率从58%提升至89%,且切换时间从原来的15分钟缩短至3分钟。“这意味着我们可以更灵活地调整生产计划,甚至实现‘按单生产’的极致柔性。”三一重工智能制造研究院院长向文波在2026年世界智能制造大会上介绍。
案例3:通用电气航空发动机的“长周期预测”突破
通用电气(GE)的航空发动机预测性维护系统是数字孪生体的经典应用,通过在发动机上部署数千个传感器,GE能够实时监测其健康状态,并预测剩余使用寿命(RUL),但2025年,工程师们发现一个难题:航空发动机的运行周期长达数年,期间会经历多次维修、更换部件等操作,这些干预会导致传感器数据的分布发生非线性变化,使得长期预测的误差逐渐累积。
GE团队与麻省理工学院合作,开发了一种“时间感知的Layer Normalization”算法,该算法不仅对每一层神经网络的输入数据进行归一化,还引入了时间衰减因子,使模型更关注近期数据,淡忘”过时数据,对于运行了3年的发动机,模型会赋予最近1年的数据70%的权重,而赋予前2年的数据仅30%的权重,这一调整显著提升了长期预测的准确性。 养生保健与绿色水处理热度不断攀升,技术创新带来新突破
测试数据显示,引入时间感知的Layer Normalization后,模型对航空发动机剩余使用寿命的预测误差从12%降至4%,且在5年的运行周期内,预测误差的累积增长从原来的8%降至2%。“这意味着我们可以更精准地安排维修计划,避免‘过度维修’或‘维修不足’。”GE航空数字孪生项目负责人艾米丽·陈(Emily Chen)在2026年巴黎航展上表示。
Layer Normalization为何在工业领域“大放异彩”?
从学术理论到工业实践,Layer Normalization的“成功转型”并非偶然,其核心优势在于解决了工业数字孪生体的三个关键痛点:

-
数据分布的动态性:工业设备的数据分布会随时间、工况、环境等因素变化,传统归一化方法(如Batch Normalization)难以适应这种动态性,而Layer Normalization的“逐层归一化”特性使其更具灵活性。
-
模型训练的稳定性:工业数字孪生体的模型通常需要持续学习新数据,Layer Normalization通过稳定每一层的输入分布,避免了梯度消失或爆炸,使得模型能够长期稳定运行。
-
跨场景的泛化能力:工业应用中,模型需要在不同工况、不同设备甚至不同工厂间迁移,Layer Normalization的“自适应”特性使其能够快速适应新场景,减少了重新训练的需求。 2026年中学教育与可再生能源热度持续攀升,相关领域迎来新突破
挑战与未来:Layer Normalization的“下一站”
尽管Layer Normalization在工业数字孪生体中表现出色,但其应用仍面临挑战,如何平衡归一化的强度与模型表达能力?如何处理非结构化数据(如图像、文本)的归一化?这些问题仍是学术界和工业界共同探索的方向。
2026年,一些前沿研究已开始尝试将Layer Normalization与其他技术结合,西门子正在探索将Layer Normalization与联邦学习结合,实现多工厂数据的协同训练而不泄露隐私;三一重工则尝试将Layer Normalization与物理约束(如能量守恒定律)结合,提升模型的物理一致性。
“数字孪生体的终极目标是实现‘物理世界与虚拟世界的无缝融合’,而Layer Normalization让我们离这个目标更近了一步。”约翰·穆勒在2026年的一次行业论坛上总结道,“但真正的突破,可能还在路上。”
在工业领域,技术进步往往始于“细节”的优化,Layer Normalization这个看似“微小”的算法调整,正悄然推动着数字孪生体从“概念验证”走向“规模化应用”,2026年的工业实践证明:当学术理论与工业需求深度结合时,最不起眼的技术细节,也可能成为改变游戏规则的关键。 文旅融合与瑜伽舞蹈热度持续上升,相关产业迎来新机遇