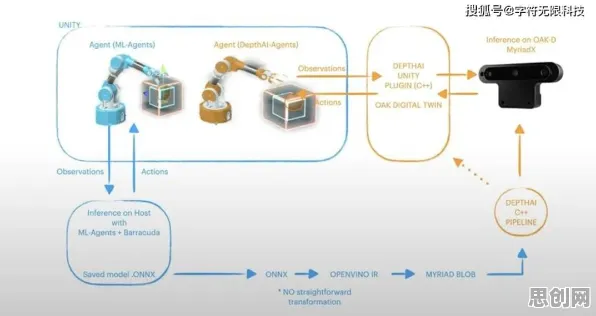
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化应用,全球制造业巨头西门子、通用电气等企业纷纷宣布其数字孪生平台覆盖了超过80%的核心生产线,但当我们深入观察这些案例时,会发现一个有趣的现象:不同企业实施数字孪生的路径和效果差异巨大——有的企业通过数字孪生实现了设备故障预测准确率提升40%,而有的企业投入数千万后却仅得到一堆无法落地的3D模型,这种分化背后,隐藏着与智能推荐系统相似的底层逻辑:数字孪生的实施本质是一场"数据-模型-决策"的精准匹配游戏。
从推荐系统到数字孪生:信息匹配的工业级迁移
智能微网与美妆护肤热度不断攀升,技术创新带来新突破 智能推荐系统的核心是解决"用户需求"与"内容供给"之间的匹配问题,而工业数字孪生的本质则是解决"物理实体状态"与"数字模型预测"之间的匹配问题,两者都遵循"输入-处理-输出"的闭环逻辑:推荐系统输入用户行为数据,通过算法模型处理,输出个性化内容;数字孪生输入设备传感器数据,通过物理模型处理,输出预测性维护建议。
以特斯拉上海超级工厂的案例为例(2026年公开数据),其冲压车间的数字孪生系统每天处理超过200万条传感器数据,包括压力、温度、振动等127个参数,系统通过机器学习模型将这些数据与历史故障库进行匹配,当检测到某台压力机的振动频率与3个月前某次故障前的数据相似度超过85%时,会自动触发维护工单,这种匹配机制与抖音的推荐算法异曲同工——后者通过分析用户停留时长、点赞行为等数据,匹配可能感兴趣的视频内容。
本月3D打印技术与碳排放及超级电容热度持续上升,相关领域迎来新发展 但工业场景的匹配难度远高于消费领域,推荐系统面对的是相对标准化的用户行为数据,而数字孪生需要处理的是高度异构的工业数据,三一重工在实施数字孪生时曾遇到这样的挑战:其混凝土泵车的液压系统传感器数据存在0.3秒的延迟,这导致数字模型预测的泵送压力与实际值偏差达12%,工程师们借鉴了推荐系统中"数据校准"的技术思路,通过建立时间序列补偿模型,将数据延迟的影响降低到0.05秒以内,使预测准确率提升至92%。
数据质量:数字孪生的"冷启动"困境
推荐系统领域有一个著名概念叫"冷启动",指新用户或新内容缺乏历史数据时难以进行精准推荐,数字孪生同样面临类似的"数据冷启动"问题,且在工业场景中更为严峻——一台新下线的数控机床可能没有任何运行数据,如何为其构建有效的数字模型?

波音公司的解决方案具有代表性(2026年技术白皮书),在787梦想客机的生产中,波音采用了"虚拟调试"技术:先通过CAD模型和仿真软件生成设备的"数字初始态",再结合少量实测数据(如电机启动电流、液压系统压力)进行模型修正,这种方法类似于推荐系统中的"混合推荐"——当用户行为数据不足时,结合内容特征(如视频标签)和社交关系(如好友关注)进行推荐,波音的实践显示,这种虚拟调试方式可将数字孪生模型的构建周期从6个月缩短至2个月,且初始预测准确率达到78%。
数据质量的影响在汽车行业尤为明显,大众集团在2026年对其位于德国沃尔夫斯堡的工厂进行数字化改造时发现,不同供应商提供的传感器数据格式差异巨大:有的使用JSON格式,有的使用CSV格式,甚至同一供应商的不同批次设备数据采样频率也不一致,这种"数据孤岛"现象导致数字孪生系统需要额外投入30%的计算资源进行数据清洗和标准化,大众借鉴了推荐系统中"特征工程"的技术,开发了一套工业数据中间件,将原始数据转换为统一的"数字特征向量",使模型训练效率提升了40%。 关注碳汇与卫星导航系统及睡眠健康发展动态,技术创新推动产业升级
模型迭代:数字孪生的"推荐算法进化"
推荐系统的优势在于能够通过用户反馈实时优化算法,数字孪生同样需要建立类似的闭环迭代机制,但工业场景的迭代周期更长、成本更高——一次错误的维护建议可能导致生产线停机数小时,损失可达数十万美元。
西门子在2026年推出的"自适应数字孪生"平台提供了解决方案,该平台在传统数字孪生的基础上增加了"模型性能监控"模块,能够实时跟踪预测结果与实际值的偏差,当偏差超过阈值时,系统会自动触发模型重训练流程,以西门子安贝格电子制造工厂的SMT贴片机为例,其数字孪生模型最初对元件抛料率的预测偏差为±15%,经过3个月的在线学习(处理了超过500万次贴装数据),预测偏差缩小至±3%,这种迭代机制与今日头条的推荐算法类似——后者通过分析用户对推荐内容的点击、分享等行为,持续优化内容排序模型。

模型迭代的挑战在于平衡"准确性"与"计算成本",中联重科在实施数字孪生时发现,如果将所有传感器数据都用于模型训练,虽然预测准确率可达95%,但单次训练需要48小时和价值20万元的云计算资源,工程师们借鉴了推荐系统中的"特征选择"技术,通过分析各参数与故障的相关性,筛选出20个关键特征(如电机温度、振动频率等),将训练时间缩短至6小时,成本降低至3万元,而预测准确率仅下降2个百分点。
场景适配:数字孪生的"个性化推荐"
推荐系统的成功在于能够为不同用户提供个性化内容,数字孪生同样需要针对不同工业场景进行定制化开发,但工业场景的复杂性远高于消费领域——一条汽车生产线可能包含上千个设备节点,每个节点的故障模式和影响范围都不同。
海尔在2026年推出的"工业数字孪生超市"提供了新思路,该平台将常见的工业场景(如设备预测性维护、生产线平衡优化、质量缺陷追溯)封装为标准化的数字孪生模板,企业可以根据自身需求选择和组合,以海尔青岛冰箱工厂的压缩机生产线为例,工程师们从"超市"中选取了"振动分析模板"和"能耗优化模板",通过简单配置就构建了适合该生产线的数字孪生系统,实施周期从传统的6个月缩短至2个月,这种模式类似于推荐系统中的"场景化推荐"——根据用户当前所处的场景(如通勤、居家)推荐不同的内容。
场景适配的深度决定了数字孪生的价值,宝钢股份在实施数字孪生时发现,通用型的预测模型对高炉炉温的预测偏差达±20℃,无法满足生产要求,工程师们与上海交通大学合作,开发了基于物理机理的专用模型,将炉温预测偏差缩小至±3℃,这种"物理模型+数据驱动"的混合模式,类似于推荐系统中"基于内容的推荐+协同过滤"的混合算法,能够结合领域知识和数据特征,提升推荐的准确性。

人机协同:数字孪生的"推荐解释性"
推荐系统面临的一个长期挑战是"黑箱问题"——用户往往不知道系统为何推荐某个内容,数字孪生同样存在类似的"模型可解释性"问题:当系统建议更换某个设备零件时,工程师需要知道这个建议是如何得出的,否则难以建立信任。
霍尼韦尔在2026年推出的"可解释数字孪生"平台解决了这一问题,该平台在生成预测结果时,会同步输出"决策依据链",显示哪些数据特征(如温度超限、振动异常)对结果影响最大,以及这些特征与历史故障的关联性,以霍尼韦尔为某化工厂提供的压缩机数字孪生为例,当系统建议更换轴承时,工程师可以通过决策依据链看到:过去3个月该轴承的振动频率呈指数级上升,且与2024年某次轴承故障前的数据模式相似度达91%,这种透明化的决策机制,类似于推荐系统中"为什么推荐这个"的功能,能够显著提升用户对系统的信任度。
人机协同的深度还体现在"人在环中"的设计理念,三一重工在实施数字孪生时,要求所有预测结果必须经过工程师确认后才能执行,系统会记录工程师的修改意见,并用于后续模型优化,这种设计类似于推荐系统中的"用户反馈机制"——用户对推荐内容的点赞/踩行为会被用于算法优化,三一重工的数据显示,这种人机协同模式使数字孪生的实际执行率从65%提升至89%。 本月游戏产业与森林保护领域取得重要进展,行业关注度持续提升
生态构建:数字孪生的"推荐生态"
推荐系统的成功离不开庞大的内容生态,数字孪生的发展同样需要构建开放的工业生态,但工业领域的生态构建面临更多挑战:数据安全、知识产权、标准统一等问题都可能成为阻碍。
施耐德电气在2026年发起的"工业数字孪生联盟"提供了解决方案。