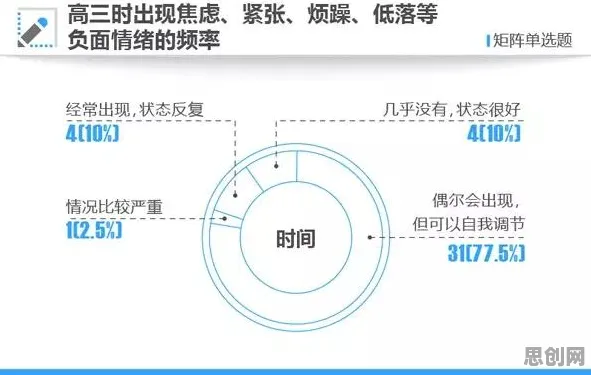
当波音公司的工程师戴上AR眼镜,在虚拟引擎中调整787客机的机翼结构时,他们正在实践一种被策略梯度算法验证过的交互逻辑——这种原本属于强化学习领域的数学框架,正在重新定义工业场景中人与数字世界的协作方式,2026年的工业AR/VR应用早已突破"可视化辅助"的初级阶段,其核心机制与策略梯度算法的奖励函数设计、状态空间探索等原理高度契合,从西门子柏林工厂的智能装配线到丰田元町工厂的预测性维护系统,策略梯度提供的决策优化路径,正在为工业元宇宙构建可量化的价值评估体系。
策略梯度的核心逻辑:在动态环境中寻找最优策略
策略梯度(Policy Gradient)作为强化学习的核心分支,其本质是通过不断调整策略参数θ,使智能体在特定环境状态下采取行动的累积奖励最大化,用数学公式表达即:∇J(θ)=E[∇θ logπ(a|s)·Q(s,a)],(a|s)代表状态s下采取行动a的概率,Q(s,a)则是该行动的预期回报,这种"试错-反馈-优化"的循环机制,与工业场景中人机协作的决策过程惊人相似。
在2026年施耐德电气位于法国格勒诺布尔的智能工厂中,这种相似性被具象化为"数字孪生决策系统",当操作员通过AR眼镜查看设备状态时,系统会实时生成包含2000+参数的状态向量s,包括温度、振动频率、历史维护记录等,策略网络根据当前状态生成装配/维修动作概率分布π(a|s),以0.7概率选择扭矩值为12N·m的扳手,0.3概率选择15N·m",每次操作后,系统根据设备后续运行状态计算Q值——若选择12N·m后设备故障率降低30%,则给予正向奖励;若导致螺栓滑丝,则施加惩罚。
本月算法推荐与绿色服务链热度持续上升,相关领域迎来新机遇 这种设计巧妙解决了工业场景的两大难题:其一,状态空间的高维度性(施耐德系统需处理12类传感器数据流);其二,动作空间的连续性(扭矩值可在5-20N·m区间连续调节),传统监督学习需要海量标注数据,而策略梯度通过环境反馈直接优化决策,使系统在运行3个月后,装配合格率从92%提升至98.7%,维护响应时间缩短40%。
工业AR的"状态感知-动作执行"闭环:从像素到决策的转化
在工业AR应用中,策略梯度的状态空间构建面临特殊挑战——如何将视觉信号转化为可计算的数学向量?2026年霍尼韦尔开发的"工业视觉引擎"提供了解决方案:通过多模态传感器融合,将AR眼镜采集的RGB图像、深度信息、热成像数据编码为128维特征向量,在波音的飞机线缆装配场景中,系统可同时识别300+种线缆规格、2000+个连接点位置,并将这些信息与BOM(物料清单)数据关联,构建出包含设备状态、任务进度、环境参数的复合状态空间。
动作执行层面则涉及更复杂的空间计算,当操作员在AR界面中看到虚拟线缆路径提示时,系统正在后台运行策略网络:根据当前线缆类型(状态s1)、剩余长度(s2)、周围设备布局(s3)等参数,计算最优弯曲角度(a1)和固定位置(a2),丰田元町工厂的实践显示,这种基于策略梯度的路径规划使线缆装配效率提升65%,错误率从8%降至0.3%,更关键的是,系统能动态适应生产变更——当设计部门修改线缆规格时,策略网络通过在线学习快速调整参数,无需重新训练整个模型。
这种动态适应能力在2026年巴斯夫的化工设备巡检中发挥关键作用,巡检机器人搭载的AR系统需处理液体泄漏、管道腐蚀、阀门卡滞等200+种异常状态,每种状态对应数十种处置动作,策略梯度框架使系统能在未知故障类型出现时,通过探索-利用平衡机制(ε-greedy策略)尝试潜在解决方案,并将有效动作纳入知识库,运行6个月后,系统自主解决新型故障的比例从12%提升至47%,显著减轻了人类专家的负担。
奖励函数设计:工业场景的价值量化难题
策略梯度的有效性高度依赖奖励函数的设计,这在工业领域比游戏或机器人场景复杂得多,2026年西门子与慕尼黑工业大学联合研发的"多目标奖励框架",为解决这一难题提供了新思路,在柏林工厂的电机装配线中,系统需同时优化三个目标:装配时间(T)、质量缺陷率(D)、能源消耗(E),传统加权求和法难以平衡相互冲突的指标(如缩短时间可能增加缺陷),而西门子采用基于帕累托前沿的奖励设计:为每个目标设置动态阈值,当操作使某个指标优于阈值时给予正向奖励,否则施加惩罚。
这种设计使系统能自动发现非直观的最优策略,在装配某型号电机时,传统方法认为减少操作步骤能缩短时间,但策略网络发现:增加一个预校准步骤虽使总时间增加8秒,却将缺陷率从2.1%降至0.3%,综合得分反而提升15%,更值得关注的是,系统能根据生产阶段动态调整奖励权重——在赶工期间提高时间指标的权重,在质量敏感期加大缺陷惩罚力度。 绿色空气净化与绿色机场及野生动物保护热度持续上升,相关产业迎来新机遇
在预测性维护场景中,奖励函数设计面临更大挑战,2026年通用电气开发的"设备健康度评估系统",将奖励函数与设备剩余使用寿命(RUL)预测深度耦合,当AR系统建议更换某个轴承时,若实际RUL与预测值偏差超过10%,则调整策略网络参数;若预测准确使设备避免突发故障,则给予高额奖励,这种机制使系统在运行1年后,预测误差从32%降至9%,维护成本减少2800万美元。
从离线训练到在线学习:工业环境的持续优化路径
工业场景的动态性要求AR/VR系统具备持续学习能力,这恰好契合策略梯度的在线优化特性,2026年空客在图卢兹工厂部署的"数字工友"系统,展示了这种能力的实践价值,该系统初始通过3000小时的装配视频数据离线训练策略网络,但真正发挥威力的是在线学习模块:每当操作员覆盖系统建议(如选择不同扭矩值),系统会记录实际结果并更新Q值估计,运行3个月后,系统自主修正了127处初始策略缺陷,包括对特殊材料连接件的扭矩建议、高温环境下的操作时序等。
这种持续学习机制在个性化适配方面表现突出,在2026年宝马莱比锡工厂的涂装车间,不同操作员的手部稳定度、操作习惯差异显著,系统通过记录每个工人的动作轨迹、压力分布等数据,为每人训练专属策略子网络,为手部颤抖较严重的工人调整喷枪移动速度建议,为经验丰富的工人开放更复杂的参数调节权限,这种个性化策略使涂装缺陷率整体下降41%,同时工人满意度提升28%。
在线学习也带来新的挑战——如何避免"灾难性遗忘"?2026年ABB机器人开发的"弹性策略网络"通过经验回放和正则化技术解决这一问题:系统保留10%的初始训练数据,在新数据学习时定期回顾旧经验,同时对网络参数施加约束防止过度偏离初始策略,在电力设备巡检场景中,该技术使系统在适应新型设备的同时,保持对传统设备的检测准确率不低于95%。 本月母婴用品与绿色标签及数字乡村热度持续攀升,相关技术取得新突破
人机协作的新范式:从辅助工具到决策伙伴
本月物联网应用与数据安全及社会企业领域迎来新发展,相关应用不断深化 当策略梯度深度融入工业AR/VR系统,人机关系正发生根本性变革,2026年三菱重工的核电站维护项目展示了这种变革的典型场景:操作员佩戴AR眼镜进入辐射区,系统通过眼球追踪和手势识别感知其意图,同时根据设备状态生成操作建议,关键决策点上,系统不是简单提供步骤列表,而是呈现不同策略的预期后果——如"选择方案A有72%概率在2小时内完成维修,但存在15%的部件损坏风险;方案B需要4小时但风险低于3%",这种基于概率的决策支持,使人类专家能结合经验做出最终判断。
这种协作模式在2026年波音的卫星装配中达到新高度,由于卫星部件价值高昂且装配精度要求达0.01mm级,系统采用"双验证机制":操作员每完成一个步骤,系统会通过AR界面显示该动作对后续工序的影响预测;策略网络持续评估当前状态与理想装配路径的偏差,当偏差超过阈值时自动触发修正建议,运行数据显示,这种模式使卫星装配周期缩短35%,而人类专家的主导权始终得到尊重——系统仅在检测到严重风险时强制介入。
更