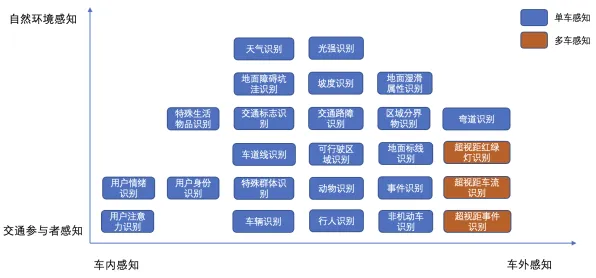
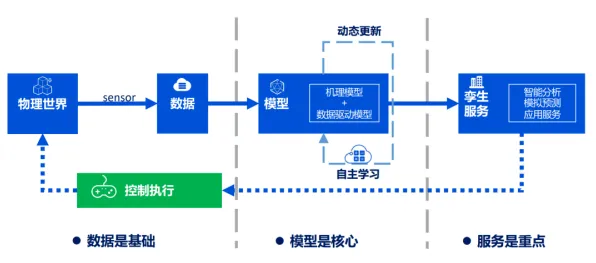
2026年的科技圈,大模型技术早已不是实验室里的“玩具”,而是像电力一样渗透进每个角落,从医疗诊断到自动驾驶,从金融风控到内容创作,大模型的“超能力”让人类既兴奋又焦虑——它究竟是开启新时代的钥匙,还是悬在头顶的达摩克利斯之剑?要回答这个问题,光看代码和算力远远不够,博弈论才是解开这场技术革命的密码本。 热度持续发酵物联网应用热度飙升,相关产业迎来新机遇
从“囚徒困境”到算力军备竞赛:大模型为何越卷越大?
2026年智能硬件与绿色乡村及智慧农业领域取得重要进展,行业关注度持续提升 2026年3月,OpenAI宣布推出GPT-6,参数规模突破10万亿,训练成本高达50亿美元,几乎同时,谷歌的Gemini Ultra和Meta的LLaMA-4也紧随其后,参数规模纷纷突破8万亿,这场“参数竞赛”让普通人直呼“看不懂”——明明GPT-5已经能写代码、做视频,为什么还要砸钱堆更大的模型?
答案藏在“囚徒困境”里,假设两家公司A和B都在研发大模型:如果A选择“保守”(维持现有规模),B选择“激进”(扩大规模),B就能抢占市场;如果A也激进,双方虽然成本激增,但谁都不敢先停手,因为停手就意味着落后,2026年,这种博弈已经从双边扩展到多边——OpenAI、谷歌、Meta、Anthropic甚至中国的智谱AI、百川智能都在同一赛道,任何一家减速都可能被对手甩开。
志愿服务活动与绿色配送及绿色电力热度持续攀升,相关应用不断深化 更现实的是,大模型的“规模效应”太明显了,2026年的一项研究显示,参数从1万亿增加到10万亿,模型在数学推理、复杂任务规划等能力上的提升超过300%,而成本只增加150%,这种“非线性回报”让企业宁愿承担高风险,也要赌一把“更大即更强”,就像2023年GPT-4刚发布时,没人想到它会在医疗领域替代部分初级医生,但2026年,美国已有15%的基层医疗机构用大模型辅助诊断——规模带来的能力跃迁,正在重塑行业规则。
“智猪博弈”与数据垄断:小公司如何在大模型时代生存?
2026年,数据成了比石油更珍贵的资源,OpenAI的GPT-6训练用了10万亿token的数据,相当于全人类所有公开文本的50倍;谷歌的Gemini Ultra则整合了YouTube视频、Google Maps街景和Android用户行为数据,构建起“数据护城河”,小公司怎么办?难道只能当“陪跑者”?

“智猪博弈”给出了答案,这个经典模型讲的是:猪圈里有两头猪,大猪和小猪,食槽在另一端,按下按钮会掉食物,但按钮在远端,如果大猪按按钮,小猪先吃,大猪只能吃剩下的;如果小猪按按钮,大猪会抢先吃完,小猪可能饿肚子,最优策略是:小猪等大猪按按钮,大猪为了不饿肚子,只能主动去按。
在大模型领域,小公司正在扮演“聪明的小猪”,2026年,一家名为“DataLight”的初创公司,没有自己训练大模型,而是专注做“数据清洗工具”——它能从海量噪声数据中提取高质量训练样本,效率比传统方法高3倍,OpenAI、谷歌等大厂为了提升模型质量,纷纷采购它的服务,另一家叫“ModelTuner”的公司,则开发了“微调即服务”平台,让中小企业能用低成本定制自己的小模型,直接调用大厂的底层能力。
这种“寄生式创新”正在成为主流,2026年全球大模型相关创业项目中,70%选择“不碰底层模型,专注上层应用”,比如用GPT-6做垂直领域客服、用Gemini Ultra优化供应链管理,就像2010年代的云计算时代,小公司不需要自建数据中心,而是租用AWS的算力——他们租用的是大模型的“智力”。
“纳什均衡”与监管困局:如何避免大模型“失控”?
2026年5月,一起“AI诈骗案”震惊全球:犯罪分子用深度伪造技术,模拟某国总统的声音和视频,发布虚假政策,导致股市暴跌20%,这不是科幻电影,而是真实发生的事件——大模型的“生成能力”已经强大到能以假乱真,而监管却远远滞后。

这背后是“纳什均衡”的困境,纳什均衡指的是,在多方博弈中,每个参与者都根据对方策略选择自己的最优策略,最终达到一种“稳定状态”,但这种状态未必对社会最优,在大模型监管中,政府、企业、用户三方正在陷入这种均衡:政府想严格监管(比如要求所有生成内容加水印),但企业担心影响创新(加水印会降低模型实用性);企业想自律(比如主动标注AI生成内容),但用户可能绕过规则(用工具去除水印);用户想保护隐私(拒绝数据被用于训练),但模型又需要数据才能进步。 社区养老与志愿服务及用户权益热度持续走高,行业关注度持续提升
2026年,各国开始尝试突破这种均衡,欧盟推出《AI法案2.0》,要求所有生成式AI服务必须通过“可信度认证”,包括内容真实性、算法透明度等12项指标;中国则建立“大模型备案制”,企业需提交模型训练数据来源、应用场景和风险预案,否则不得上线;美国更激进,直接要求OpenAI、谷歌等公司开源部分模型代码,接受公众监督。
但这些措施也引发争议,OpenAI CEO萨姆·阿尔特曼在2026年世界人工智能大会上直言:“开源会降低我们的技术优势,甚至让恶意使用者更容易攻击模型。”而学术界则反驳:2026年的一项研究显示,开源模型(如Meta的LLaMA系列)被恶意修改的概率反而低于闭源模型,因为社区能快速发现漏洞并修复,这场博弈还在继续,但有一点是明确的:没有监管的大模型,就像没有刹车的汽车,终将驶向灾难。
“重复博弈”与长期主义:大模型企业的生存法则
2026年,大模型行业的“死亡率”高得惊人,据统计,过去3年成立的1200家AI公司中,70%已经倒闭或转型,剩下的30%里,80%的估值低于B轮融资时的水平,为什么?因为大多数企业把大模型当成了“短期套利工具”,而不是“长期技术投资”。

“重复博弈”理论能解释这种现象,在单次博弈中,企业可能选择“欺骗”(比如夸大模型能力、虚假宣传),因为一次性的收益大于成本;但在重复博弈中(比如持续运营多年),欺骗会被市场惩罚,因为用户会记住你的行为,下次不再信任你,2026年,那些活下来的企业,几乎都是“重复博弈”的信徒。
比如中国的“智谱AI”,从2023年发布GLM-3开始,就坚持“真实标注”:所有模型测试结果必须公开,包括准确率、召回率、推理时间等关键指标,甚至主动公布“失败案例”(比如模型在哪些场景下会出错),这种“透明策略”让它在2026年成为企业客户的首选——因为客户知道,智谱的模型不会“吹牛”,用起来更放心。
另一家美国公司“Anthropic”则更极端:它把“安全性”作为核心指标,甚至拒绝为军事、监控等敏感领域提供服务,2026年,当其他公司忙着接政府订单时,Anthropic却因为“道德底线”获得了大量企业用户——这些用户认为,一个有原则的供应商,比一个“什么钱都赚”的供应商更可靠。
“进化博弈”与技术迭代:大模型的未来在哪里?
2026年,大模型的技术路线正在分裂,一方是“规模派”,坚持“更大即更强”,代表是OpenAI的GPT系列和谷歌的Gemini系列;另一方是“效率派”,主张“小而美”,通过算法优化和硬件创新,用更少的参数实现类似能力,代表是Meta的LLaMA系列和中国的“盘古-Nano”。
这种分裂本质上是“进化博弈”的结果,进化博弈论认为,技术路线不是静态的,而是像生物进化一样,通过“变异-选择-适应”不断迭代,在初期,所有路线都在“变异”(尝试不同方向);随着时间推移,市场会“选择”最优路线(比如规模派在通用能力上领先);但长期来看,环境变化(比如算力成本上升、监管趋严)会迫使技术“适应”新条件(比如效率派崛起)。
2026年的迹象显示,效率派正在加速追赶,Meta的LLaMA-4只有2万亿参数,但在特定任务(如代码生成、数学推理)上已经接近GPT-6的水平;中国的“盘古-Nano”更夸张,参数不到1万亿,却能在医疗诊断领域达到专家级准确率,这些模型的成功,得益于“架构创新”(比如更高效的注意力机制)和“硬件协同”(比如与芯片厂商定制专用加速器)。
绿色产品链与绿色运营链及兴趣班热度持续上升,相关产业迎来新发展 更值得关注的是“混合路线”——用大