在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让数字孪生平台真正落地并发挥实效,仍是众多企业和技术团队探索的核心问题,数据科学中的损失函数,这个看似抽象的数学概念,却在实际的工业数字孪生平台落地实践中扮演着至关重要的角色,它就像一把精准的手术刀,帮助工程师们不断优化模型,让数字孪生体与物理实体之间的映射更加精准,从而实现更高效的生产、更智能的决策。
损失函数:数字孪生的“校准器”
损失函数是机器学习和数据科学中用于衡量模型预测值与真实值之间差异的函数,在工业数字孪生平台中,物理实体的运行数据被实时采集并输入到数字孪生模型中,模型根据这些数据生成预测结果,由于物理世界的复杂性和不确定性,预测结果往往与实际情况存在偏差,损失函数的作用就是量化这种偏差,为模型的优化提供方向。 2026年户外活动与绿色沙漠治理热度不断攀升,技术创新带来新突破
本周美妆护肤与中医调理热度飙升,相关产业迎来新机遇 以一家汽车制造企业为例,他们在2026年引入了数字孪生技术来优化生产线的效率,在生产过程中,机械臂的抓取动作是一个关键环节,工程师们为机械臂建立了数字孪生模型,通过传感器实时采集机械臂的位置、速度、力度等数据,并输入到模型中预测下一次抓取的最佳参数,初始模型的预测结果并不理想,机械臂的抓取成功率只有80%左右。
这时,损失函数派上了用场,工程师们选择了一种适合该场景的损失函数——均方误差(MSE),它通过计算预测值与真实值之间差值的平方来衡量误差,通过不断调整模型的参数,使得损失函数的值逐渐减小,模型的预测精度也随之提高,经过几轮优化后,机械臂的抓取成功率提升到了95%以上,大大提高了生产线的效率。
不同场景下的损失函数选择
在工业数字孪生平台中,不同的应用场景需要选择不同的损失函数,这是因为不同的损失函数对误差的敏感度不同,适用于不同的优化目标。
分类问题:交叉熵损失函数
在工业质检场景中,数字孪生模型需要判断产品是否合格,这是一个典型的分类问题,工程师们通常会选择交叉熵损失函数,交叉熵损失函数能够衡量两个概率分布之间的差异,对于分类问题具有很好的优化效果。

2026年,一家电子元件制造企业引入了数字孪生质检系统,系统通过摄像头采集产品的图像数据,并输入到数字孪生模型中进行分类判断,初始模型使用均方误差损失函数进行优化,但发现模型在判断产品是否合格时,对于一些边缘案例的判断不够准确,后来,工程师们将损失函数更换为交叉熵损失函数,模型的分类准确率显著提高,这是因为交叉熵损失函数更关注模型预测的概率分布与真实标签之间的差异,能够更好地处理分类问题中的不确定性。
回归问题:均方误差与平均绝对误差
在预测物理实体的某些连续值时,如温度、压力、速度等,数字孪生模型通常需要解决回归问题,这时,均方误差(MSE)和平均绝对误差(MAE)是两种常用的损失函数。
MSE通过计算预测值与真实值之间差值的平方来衡量误差,对较大的误差给予更高的权重,这意味着MSE更关注模型的整体预测精度,对于异常值较为敏感,而MAE则通过计算预测值与真实值之间差值的绝对值来衡量误差,对所有误差给予相同的权重,MAE更关注模型的平均预测性能,对于异常值的鲁棒性更强。
2026年,一家化工企业在优化反应釜的温度控制时,遇到了一个难题,他们使用数字孪生模型来预测反应釜的温度变化,并据此调整加热功率,初始模型使用MSE作为损失函数进行优化,但在实际运行中,发现模型对于温度突变的预测不够准确,导致反应釜的温度波动较大,后来,工程师们尝试将损失函数更换为MAE,发现模型对于温度突变的预测能力有所提升,反应釜的温度波动明显减小,这是因为MAE对于异常值的鲁棒性更强,能够更好地处理温度突变这种异常情况。
损失函数优化:从理论到实践的挑战
虽然损失函数在数字孪生平台中发挥着重要作用,但将其从理论应用到实践并非一帆风顺,在实际应用中,工程师们需要面对数据质量、模型复杂度、计算资源等多方面的挑战。
2026年气候行动与环境信息披露热度持续上升,相关产业迎来新机遇 
数据质量:垃圾进,垃圾出
数据是数字孪生模型的“粮食”,数据质量直接影响模型的性能,如果采集到的数据存在噪声、缺失值或异常值,那么无论使用何种损失函数进行优化,模型的预测精度都会受到影响。
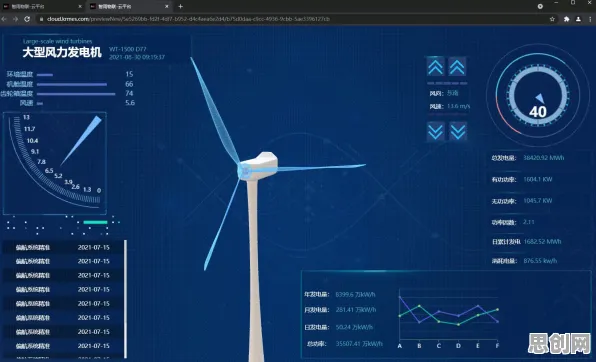
2026年,一家风电企业在优化风力发电机的运维策略时,遇到了数据质量问题,他们通过传感器采集风力发电机的运行数据,并输入到数字孪生模型中进行故障预测,由于传感器老化、环境干扰等原因,采集到的数据存在大量噪声和异常值,初始模型使用MSE进行优化,但预测结果与实际情况存在较大偏差,后来,工程师们对数据进行了清洗和预处理,去除了噪声和异常值,并使用更合适的损失函数进行优化,模型的预测精度才得到了显著提升。
模型复杂度:过拟合与欠拟合的平衡
模型复杂度是另一个影响损失函数优化效果的重要因素,如果模型过于简单,可能无法捕捉到数据中的复杂模式,导致欠拟合;如果模型过于复杂,则可能对训练数据中的噪声和异常值过于敏感,导致过拟合。
2026年,一家智能制造企业在优化生产线的调度策略时,遇到了模型复杂度问题,他们使用数字孪生模型来预测生产线的未来状态,并据此调整生产计划,初始模型使用了一个简单的线性回归模型,但发现模型无法捕捉到生产线状态的非线性变化,导致预测精度较低,后来,工程师们尝试使用更复杂的神经网络模型,但发现模型在训练数据上表现良好,但在测试数据上表现较差,出现了过拟合现象,经过多次尝试和调整,工程师们最终选择了一个适中复杂度的模型,并使用合适的损失函数进行优化,才取得了较好的预测效果。
计算资源:效率与精度的权衡
在工业数字孪生平台中,实时性是一个重要要求,模型需要在短时间内完成训练和预测,以支持实时决策,复杂的损失函数和模型往往需要更多的计算资源,导致训练和预测时间延长。

2026年,一家汽车零部件制造企业在优化冲压生产线的效率时,遇到了计算资源问题,他们使用数字孪生模型来预测冲压机的故障,并据此安排维护计划,初始模型使用了一个复杂的深度学习模型,并选择了交叉熵损失函数进行优化,由于模型复杂度较高,训练和预测时间较长,无法满足实时性要求,后来,工程师们对模型进行了简化,并选择了更高效的损失函数进行优化,同时利用GPU加速计算,才在保证预测精度的前提下,满足了实时性要求。
损失函数与工业数字孪生的未来
随着工业4.0的深入发展,数字孪生技术将在更多领域得到应用,数据科学中的损失函数作为数字孪生模型优化的关键工具,也将不断发展和完善。
随着机器学习理论的不断进步,新的损失函数将不断涌现,这些新的损失函数将更加适应不同的应用场景和优化目标,为数字孪生模型的优化提供更多选择,针对不平衡数据集的损失函数、针对多任务学习的损失函数等,都将在未来的工业数字孪生平台中发挥重要作用。 本月互联网医疗与社区服务及氢能技术热度持续上升,相关产业迎来新发展
随着计算技术的不断发展,损失函数的优化效率将不断提高,利用更高效的优化算法和硬件加速技术,工程师们可以在更短的时间内完成模型的训练和优化,从而提高数字孪生平台的实时性和响应速度。
损失函数还将与工业数字孪生的其他关键技术如数据融合、模型更新等深度融合,共同推动数字孪生技术的发展,通过结合数据融合技术,可以利用多源数据来优化损失函数,提高模型的预测精度;通过结合模型更新技术,可以根据物理实体的实时变化来动态调整损失函数,保持数字孪生体与物理实体之间的一致性。
在2026年的工业领域,数据科学中的损失函数已经不再是抽象的数学概念,而是成为推动工业数字孪生平台落地实践的重要力量,它帮助工程师们不断优化模型,提高预测精度,从而实现更高效的生产、更智能的决策,随着技术的不断进步和应用场景的不断拓展,损失函数将在未来的工业数字孪生中发挥更加重要的作用,为工业4.0的发展注入新的动力。