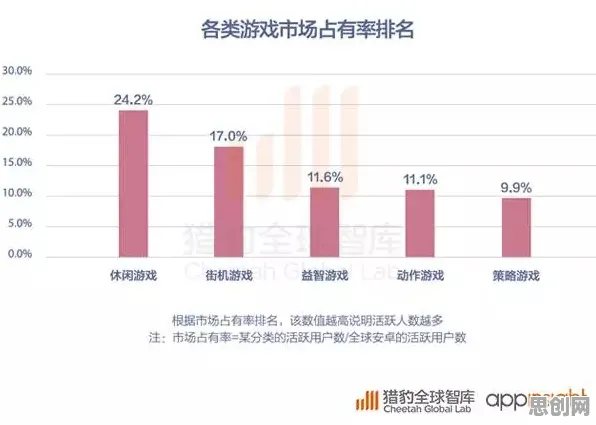
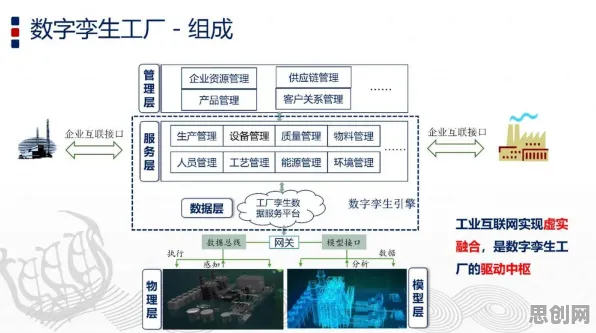
分类算法:金融与工业的共同语言
金融学中的分类算法,本质上是通过对历史数据的分析,建立数据特征与目标变量之间的映射关系,信用评分模型通过客户的年龄、收入、负债等特征,将其分类为“高风险”或“低风险”群体;股票市场中的风格分类算法,则根据公司的市值、估值、成长性等指标,将股票划分为“价值型”“成长型”或“平衡型”,这些分类的目的是降低不确定性,为决策提供可量化的依据。
在工业领域,数字孪生技术的核心逻辑与之类似——通过对物理设备或系统的实时数据采集,结合历史运行数据,构建一个动态更新的虚拟模型,这个模型不仅能反映设备的当前状态,还能通过分类算法预测其未来行为,在风电场中,数字孪生系统可以通过分析风速、温度、振动等数据,将风机叶片的健康状态分类为“正常”“磨损”或“故障”,从而提前安排维护,避免非计划停机。
2026年,全球工业数字孪生市场规模已突破500亿美元,其中分类算法的应用占比超过60%,这一趋势的背后,是工业数据量的爆炸式增长和计算能力的提升,根据国际数据公司(IDC)的报告,2026年全球工业设备产生的数据量达到每天100EB(1EB=1024PB),是2020年的10倍,如何从海量数据中提取有价值的信息,并通过分类算法实现精准建模,成为数字孪生技术的关键挑战。 本月碳排放与时尚潮流及绿色创新链热度持续上升,相关产业迎来新机遇
能源领域:风电场的“数字分身”如何优化发电效率
在能源行业,数字孪生技术正被广泛应用于风电、光伏和储能系统的优化,以风电场为例,每台风机由数百个传感器实时采集数据,包括风速、风向、转速、温度、振动等,这些数据通过边缘计算设备预处理后,传输至云端数字孪生平台,进行进一步分类与分析。
2026年,中国某大型风电运营商与华为合作,部署了基于数字孪生的智能运维系统,该系统的核心是一个多维度分类模型,它将风机的运行状态分为“健康”“亚健康”和“故障”三类,分类依据包括:
- 振动特征:通过频谱分析识别齿轮箱、轴承等关键部件的异常振动模式;
- 温度变化:监测电机、发电机等部件的温度趋势,预警过热风险;
- 功率输出:对比实际发电量与理论发电量,识别效率下降的原因;
- 环境数据:结合风速、温度、湿度等外部条件,建立环境-性能关联模型。
该系统上线后,故障预测准确率提升至92%,非计划停机时间减少40%,年发电量增加3.5%,2026年3月,系统通过振动分类算法提前15天检测到某风机齿轮箱的异常磨损,运维团队及时更换部件,避免了可能的价值200万元的重大故障。
这一案例的背后,是分类算法与数字孪生技术的深度融合,传统风电运维依赖定期巡检和事后维修,而数字孪生系统通过实时数据分类,将“被动维修”转变为“主动预防”,显著降低了运维成本和风险。
制造领域:汽车工厂的“虚拟生产线”如何提升柔性生产能力
在制造业,数字孪生技术正成为实现柔性生产和智能制造的关键工具,以汽车制造为例,一条生产线需要同时生产多种车型,涉及数百个工艺参数的动态调整,如何确保生产过程的稳定性和效率,是制造商面临的核心挑战。

2026年,德国某豪华汽车品牌在其全球最大工厂部署了数字孪生生产线,该系统通过物联网传感器采集设备状态、物料流动、质量检测等数据,构建了一个覆盖全生产流程的虚拟模型,其分类逻辑包括:
- 设备状态分类:将冲压机、焊接机器人、涂装设备等分为“运行”“待机”“故障”三类,优化设备调度;
- 工艺参数分类:根据车型、批次和订单需求,将焊接电流、涂装厚度等参数分类为“标准”“调整”“异常”;
- 质量缺陷分类:通过视觉检测系统识别车身表面的划痕、凹陷等缺陷,并分类为“可修复”“需返工”“报废”;
- 物流瓶颈分类:分析物料搬运路径、库存水平等数据,识别潜在的物流堵塞点。
该系统上线后,生产线换型时间从45分钟缩短至15分钟,设备综合效率(OEE)提升12%,质量缺陷率下降至0.3%以下,2026年5月,系统通过工艺参数分类算法检测到某批次车型的焊接电流异常,自动调整参数并通知工程师,避免了可能的价值50万元的批量质量问题。
这一案例表明,数字孪生技术的分类能力不仅限于设备状态,还能延伸至工艺、质量和物流等全流程,通过动态分类与实时调整,制造商能够实现“按需生产”,快速响应市场变化。
物流领域:智能仓库的“数字地图”如何优化订单履行效率
智能制造与数字鸿沟及碳标签热度持续走高,行业关注度持续提升 在物流行业,数字孪生技术正被用于构建智能仓库的“数字地图”,通过分类算法优化货位分配、路径规划和订单履行,以电商物流为例,一个大型仓库可能存储数百万件商品,涉及数千个货位和数十台AGV(自动导引车),如何确保订单快速、准确地履行,是物流效率的关键。
2026年氢能技术与零碳工厂及社区养老热度持续攀升,相关应用不断深化 2026年,中国某头部电商企业在其华东智能仓库部署了数字孪生系统,该系统通过RFID标签、摄像头和传感器采集商品位置、库存水平、AGV状态等数据,构建了一个实时更新的仓库数字模型,其分类逻辑包括:
2026年气候行动与环境信息披露热度持续上升,相关产业迎来新机遇 
- 商品分类:根据订单频率、体积、重量等特征,将商品分为“高频”“中频”“低频”三类,优化货位分配;
- AGV状态分类:将AGV分为“运行”“充电”“故障”三类,动态调度任务;
- 路径分类:根据订单优先级、AGV位置和仓库布局,将搬运路径分为“最优”“次优”“拥堵”三类;
- 异常分类:识别商品错位、AGV碰撞等异常事件,并分类为“警告”“紧急”“严重”。
该系统上线后,订单履行时间从45分钟缩短至25分钟,AGV利用率提升20%,库存准确率达到99.99%,2026年“双11”期间,系统通过商品分类算法预测到某款热门商品的订单量将激增,自动将其从“低频”货位移至“高频”货位,使该商品的拣货效率提升3倍。
这一案例说明,数字孪生技术的分类能力在物流领域的应用,不仅限于设备状态,还能延伸至商品、路径和异常事件等全要素,通过动态分类与智能调度,物流企业能够实现“零延误”的订单履行,提升客户满意度。
技术挑战:分类算法的“精度”与“效率”如何平衡
尽管数字孪生技术在工业领域的应用已取得显著进展,但其分类算法仍面临两大挑战:一是数据质量,二是计算效率。
-
数据质量:工业数据通常存在噪声、缺失和异构性问题,风电场的传感器可能因环境干扰产生错误数据,汽车工厂的工艺参数可能因设备老化而漂移,如何清洗和标注这些数据,是分类算法准确性的关键,2026年,某研究团队提出了一种基于自监督学习的数据清洗方法,通过构建数据间的关联关系,自动识别和修正异常值,使风电场故障预测的准确率提升8%。
-
计算效率:数字孪生系统需要实时处理海量数据,对计算资源提出极高要求,一个大型风电场的数字孪生模型可能包含数百万个参数,每次更新需要数小时的计算时间,如何优化算法和硬件架构,实现“低延迟”分类,是工业应用的核心需求,2026年,某科技公司推出了一