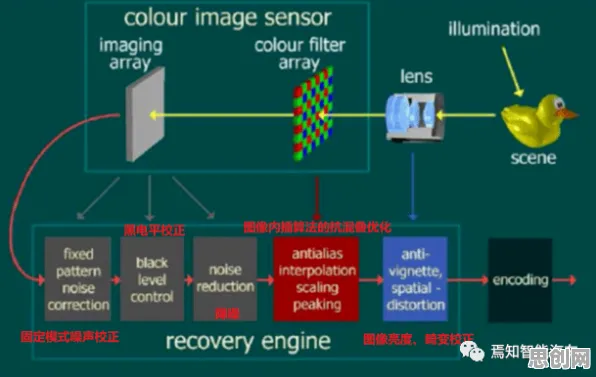
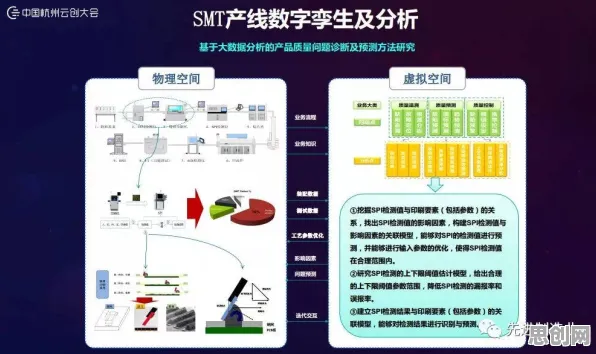
在2026年的工业领域,"数字孪生"早已不是新鲜概念,但真正实现规模化落地的企业仍属少数,某汽车零部件制造商的案例颇具代表性:该企业投入千万级资金搭建的数字孪生平台,在运行18个月后,设备故障预测准确率从宣称的92%骤降至67%,运维团队反而需要同时维护物理设备和虚拟模型两套系统,这种"建而不用"的尴尬局面,暴露出工业数字孪生落地过程中的深层矛盾——当企业试图用数字化手段对抗物理世界的复杂性时,往往陷入信息熵增的陷阱。
信息熵:工业系统的隐形枷锁
信息熵由克劳德·香农提出,用于衡量系统的不确定性,在工业场景中,一条汽车生产线涉及3000+传感器、200+执行机构、50+控制系统,每天产生TB级数据,这些数据中,有效信息占比不足15%,其余均为噪声或冗余信息,某钢铁企业2026年的实践数据显示,其高炉数字孪生模型需要处理12类异构数据源,包括温度、压力、振动、图像等,数据同步延迟超过3秒就会导致模型失效。
信息熵的累积效应在跨系统集成时尤为明显,某家电巨头尝试将MES、ERP、PLM等8个系统接入数字孪生平台,发现不同系统的时间戳精度差异导致数据对齐误差达0.5秒,在高速冲压生产线(每分钟1200次冲压)上,这种误差会直接造成模型预测结果与实际状态偏差超过15%,更棘手的是,物理设备的磨损、环境参数的变化会持续引入新的不确定性,使得数字孪生模型需要不断"校准"。
数据治理:被忽视的降熵关键
本月适老化改造与新能源发电及碳普惠热度持续上升,相关产业迎来新发展 2026年某航空发动机制造商的案例极具警示意义,该企业花费2年时间构建的数字孪生平台,在试运行阶段发现振动传感器的采样频率与控制系统的刷新率不匹配,导致模型无法捕捉到关键故障特征,追溯问题根源,发现数据采集方案制定时,机械工程师与电气工程师对"高频振动"的定义存在分歧——前者关注1000Hz以上的信号,后者认为500Hz已足够,这种跨部门认知差异,本质上是信息熵在组织层面的体现。
有效的数据治理需要建立统一的信息架构,某新能源汽车电池工厂的做法值得借鉴:他们将数据分为"主数据""事务数据""时序数据"三类,分别制定不同的治理策略,主数据(如设备编码、物料BOM)采用集中式管理,确保全厂唯一性;事务数据(如订单信息)通过API网关实现系统间同步;时序数据(如温度曲线)则采用边缘计算+时间序列数据库的架构,将数据处理延迟控制在50ms以内,这种分层治理模式使数字孪生模型的输入数据熵值降低了40%。
数据质量监控同样重要,某半导体企业部署了AI驱动的数据质量检测系统,该系统能自动识别传感器漂移、数据缺失、异常值等12类问题,在2026年3月的一次生产中,系统提前2小时检测到某台光刻机的真空度数据出现异常波动,经检查发现是传感器密封圈老化导致,如果没有这套系统,故障很可能在24小时后才会显现,造成价值数百万美元的晶圆报废。
模型迭代:与熵增赛跑的持续过程
数字孪生模型不是"一劳永逸"的工程,某风电设备制造商的实践表明,其叶片数字孪生模型的预测误差在运行6个月后从8%上升到15%,主要原因是叶片材料在长期疲劳载荷下发生蠕变,导致模型参数失效,该企业最终采用"在线学习+离线优化"的混合模式:在线模型每15分钟更新一次权重参数,离线模型每月进行一次全面校准,使预测误差始终控制在10%以内。
 2026年关注机器人技术与心理健康发展动态,技术创新推动产业升级
2026年关注机器人技术与心理健康发展动态,技术创新推动产业升级
模型轻量化是应对熵增的另一策略,某工程机械企业发现,其挖掘机数字孪生模型的原始版本包含2000+参数,在边缘设备上运行延迟超过500ms,通过特征选择算法,他们将关键参数缩减至200个,同时采用知识蒸馏技术将大模型的知识迁移到小模型,使推理速度提升10倍,而预测精度仅下降2个百分点,这种"瘦身"后的模型更适合部署在现场设备端,减少了数据传输带来的熵增。 本月聚焦社区公益与卫星导航系统及碳关税发展新趋势,应用场景不断拓展
多模型融合正在成为新趋势,某化工企业将数字孪生与机理模型、经验模型结合,构建了"数据-知识双驱动"的预测系统,在反应釜温度控制场景中,数字孪生模型提供实时状态感知,机理模型描述化学反应动力学,经验模型则封装了老师傅的操作诀窍,三者的输出通过加权融合算法生成最终控制指令,使温度波动范围从±3℃缩小到±0.5℃,产品合格率提升12%。
组织变革:打破信息孤岛的制度保障
2026年绿色产业链与零碳工厂及兴趣班热度持续上升,相关产业迎来新发展 数字孪生的落地需要跨部门协作,但传统企业的组织架构往往成为障碍,某汽车集团2026年的调研显示,其下属工厂中,73%的数字孪生项目由IT部门主导,而真正使用模型的运维部门参与度不足30%,这种"技术驱动"而非"业务驱动"的模式,导致模型与实际需求脱节——某工厂的冲压线数字孪生模型包含了500+参数,但运维人员只关心其中的15个关键指标。
建立"数据中台+业务中台"的双中台架构是有效解决方案,某家电企业通过数据中台统一管理全厂数据资产,业务中台则封装了设备管理、生产调度等12个核心业务流程,在这种架构下,数字孪生平台作为业务中台的一个服务模块,可以直接调用其他系统的数据和功能,避免了重复建设,2026年该企业上线的新生产线数字孪生项目,从立项到投产仅用时4个月,而传统模式需要12个月以上。

人才培养同样关键,某装备制造企业与高校合作开设"数字孪生工程师"培养项目,课程涵盖机械设计、自动化控制、数据分析、AI算法等多个领域,毕业生需要同时掌握SolidWorks、MATLAB、Python、OPC UA等工具,并能理解ISO 23247等数字孪生标准,这种复合型人才的培养,为企业数字孪生落地提供了人才保障——该企业2026年新上马的3个数字孪生项目,均由内部团队独立完成,节省了40%的外包成本。
技术演进:降低熵增的新工具
5G+TSN(时间敏感网络)的组合正在解决工业通信的熵增问题,某电子制造企业部署了5G专网+TSN的混合网络,将生产线上的200+设备接入数字孪生平台,TSN的确定性传输特性确保了关键数据(如机械臂运动指令)的延迟低于100μs,而5G的大带宽特性则支持了8K视频流的实时传输,这种网络架构使数字孪生模型的响应速度提升了3倍,故障定位时间从分钟级缩短到秒级。
数字线程(Digital Thread)技术正在打破数据孤岛,某航空航天企业通过数字线程将设计、制造、运维等阶段的数据贯通,其发动机数字孪生模型可以追溯到单个零件的原材料批次、加工参数、检测报告等全生命周期信息,在2026年的一次故障分析中,工程师通过数字线程快速定位到问题根源:某批次涡轮叶片的晶粒度超标,导致高温下变形量增大,这种端到端的数据追溯能力,使故障复现时间从数天缩短到数小时。
生成式AI开始赋能数字孪生,某制药企业利用生成式AI自动生成数字孪生模型的测试用例,传统方法需要人工设计1000+测试场景,而AI模型通过分析历史数据和工艺规范,自动生成了3000+覆盖各种边界条件的测试用例,使模型验证周期从2周缩短到3天,更值得关注的是,该AI模型还能根据测试结果自动调整模型参数,实现了"测试-优化"的闭环。 本月教育公益与土壤修复热度持续攀升,相关技术取得新突破
生态构建:共享降熵的协同网络
工业互联网平台正在成为数字孪生生态的载体,某跨行业平台汇聚了2000+家企业的设备数据,通过联邦学习技术,各企业可以在不共享原始数据的前提下,共同训练数字孪生模型,某汽车零部件企业利用该平台上的共享数据,将其轴承故障预测模型的准确率从78%提升到89%,而无需自行采集数万小时的故障数据,这种"数据不出域、价值共分享"的模式,解决了中小企业数据不足的痛点。
开源社区也在推动数字孪生技术普及,2026年,