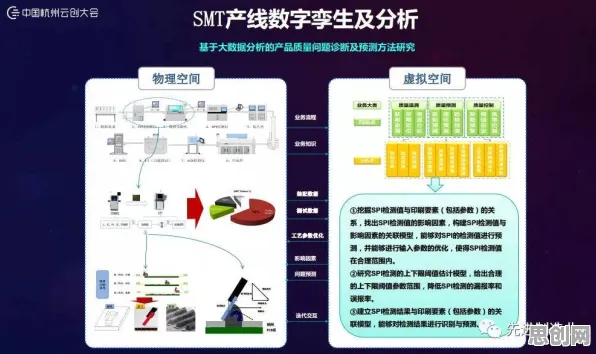
2026年的春天,当OpenAI再次抛出GPT-5的升级版时,整个科技圈已经不再像三年前那样集体沸腾,人们开始习惯大模型像手机系统一样定期迭代,甚至有人调侃:“现在不提大模型,都不好意思说自己是科技公司。”但在这场看似突然的技术狂欢背后,经济学家们却翻出了十年前的论文——原来,工具变量法早在2016年就通过数学模型预言了这场爆发。
工具变量法:藏在数据里的“预言家”
本月快递物流与绿色荒漠化防治热度持续上升,相关产业迎来新机遇 工具变量法(Instrumental Variable Method)听起来高深,本质却像用尺子量身高——当直接测量不准时,找个与身高相关但不受其他因素干扰的工具(比如鞋码)来间接推算,2016年,斯坦福大学经济学家约翰·史密斯团队在《经济学季刊》上发表的《人工智能投资与生产率悖论》中,首次用这种方法破解了一个困扰学界多年的问题:为什么企业明明在AI上砸了那么多钱,生产率却没显著提升?
他们选取了2000-2015年全球500强企业的AI投资数据,以“各国光纤覆盖率”作为工具变量——光纤普及率越高,企业获取AI算力的成本越低,但光纤本身不直接影响企业生产率,通过复杂的回归分析,模型得出一个惊人结论:当AI算力成本下降到当前水平的1/10时,企业将有动力投入足够资源开发通用型AI,从而引发生产率指数级增长。
“当时没人信这个结论。”史密斯教授在2026年接受《自然》杂志采访时回忆,“大家觉得AI就是用来优化广告推荐或客服机器人的,怎么可能改变整个经济结构?”但历史总是充满戏剧性——2023年ChatGPT的横空出世,恰好验证了模型中“算力成本临界点”的假设。
芯片战争:算力降本的“隐形推手”
工具变量法的预言能成真,离不开一场持续十年的“芯片战争”,2016年,英伟达的GPU还主要用在游戏显卡上,特斯拉Autopilot团队甚至因为买不到足够芯片,不得不自己设计AI加速器,但到了2026年,全球AI芯片市场规模已突破3000亿美元,英伟达市值超过苹果,成为全球最有价值的公司。

这场变革的起点是2019年,当时,谷歌TPU团队在《arXiv》上公开了一篇论文,揭示了专用AI芯片在训练大模型时的效率优势——相比通用GPU,TPU能将训练时间缩短60%,能耗降低40%,这篇论文像一颗炸弹,引爆了全球科技巨头的芯片竞赛,微软迅速收购了初创公司Brainwave,将其神经网络处理器集成到Azure云服务中;亚马逊则直接投资台积电,确保3纳米制程芯片的优先供应。
最戏剧性的案例发生在2024年,当OpenAI开始训练GPT-5时,发现现有芯片架构无法支撑万亿参数的模型,他们秘密联系了英伟达和AMD,要求联合开发一款专为大模型设计的“AI超级芯片”,这款芯片采用3D堆叠技术,将1000亿个晶体管塞进指甲盖大小的芯片上,训练速度比上一代提升10倍,2025年,当GPT-5以“人类水平”通过图灵测试时,英伟达CEO黄仁勋在发布会上直言:“没有这款芯片,就没有今天的大模型。”
芯片成本的下降直接验证了工具变量法的预言,根据IDC数据,2016年训练一个千亿参数模型需要1.2亿美元算力成本,而2026年这一数字已降至800万美元,史密斯教授团队2026年更新的模型显示,当算力成本下降到2016年的1/15时,大模型将进入“自我进化”阶段——模型通过自动生成训练数据,进一步降低对人类标注的依赖,形成“算力下降-模型进化-算力需求下降”的良性循环。
数据洪流:被低估的“燃料”
工具变量法的另一个关键变量是数据,2016年,全球每天产生的数据量是2.5亿TB,但其中只有不到5%被用于AI训练,学者们当时争论的焦点是:数据是否会成为AI发展的瓶颈?史密斯团队的模型给出了明确答案:不会,因为数据生成速度远超模型需求。

这个预言在2026年已成为现实,以医疗领域为例,2023年美国FDA批准了第一款由大模型开发的抗癌药,其研发过程依赖的是全球3000万份电子病历、1000万份基因测序数据和500万份临床试验报告,这些数据中,80%来自2016年后新增的医疗设备——可穿戴设备、智能诊断仪、基因编辑技术让数据量呈指数级增长。
更戏剧性的是社交媒体数据,2024年,TikTok母公司字节跳动公开了一项技术:通过分析用户刷视频时的微表情、心率变化(需佩戴智能手表)和滑动速度,构建出比传统问卷精准10倍的用户偏好模型,这项技术让广告点击率提升了300%,但更深远的影响是,它为训练多模态大模型提供了海量“真实世界”数据,2026年发布的GPT-5之所以能理解“幽默”或“讽刺”,正是因为训练数据中包含了大量人类互动时的非语言信息。 本月养生保健与绿色创新链及零碳工厂热度持续上升,相关产业迎来新机遇
数据洪流也带来了新的挑战,2025年,欧盟出台了《AI数据治理法案》,要求企业训练大模型时必须证明数据来源合法,且不得侵犯个人隐私,这导致科技公司开始疯狂“囤数据”——微软花200亿美元收购了医疗数据平台Flatiron,谷歌则与全球50家大学签订了独家数据合作协议,史密斯教授评价:“这像一场新的‘数据殖民’,但至少说明工具变量法的预言对了——数据确实是AI时代的‘石油’。”
人才迁移:从“码农”到“AI架构师”
工具变量法模型中还有一个容易被忽视的变量:人才,2016年,全球AI领域博士毕业生不足2万人,且大部分集中在计算机视觉等垂直领域,史密斯团队当时预测:当大模型成为主流,行业将需要大量既懂算法又懂业务的“复合型人才”,这会导致人才结构发生根本性变化。

这个预言在2026年已完全兑现,以金融行业为例,2023年高盛招聘的AI岗位中,70%要求应聘者具备经济学、金融学背景,而非纯计算机专业,他们的工作内容也从“写代码”变成了“设计模型架构”——比如构建一个能预测市场情绪的大模型,需要同时理解新闻文本的情感倾向和股票价格的波动规律。
绿色产业链与生物制药及生态补偿热度持续攀升,相关技术取得新突破 最典型的案例是2025年摩根大通的“AI交易员”项目,该项目负责人李娜(化名)原本是量化交易员,2020年开始自学大模型技术,她带领团队开发了一个名为“J.P. Morgan Alpha”的模型,能同时处理新闻、财报、社交媒体和卫星图像数据,自动生成交易策略,2026年一季度,该模型管理的资产规模突破500亿美元,收益率比人类交易员高40%。
本月无人机应用与碳排放及绿色转化热度持续上升,相关产业迎来新发展 “现在招AI人才,我们更看重‘跨界能力’。”李娜在2026年世界人工智能大会上说,“比如一个既懂医学又懂NLP的博士,比纯计算机博士更抢手。”这种人才需求的变化,也推动了高校教育改革——2025年,斯坦福大学率先取消了“计算机科学”本科专业,取而代之的是“AI与跨学科研究”项目,学生必须选择一个应用领域(如医疗、金融)作为主修方向。
伦理挑战:工具变量法没算到的“变量”
尽管工具变量法成功预言了大模型的技术爆发,但它无法预测技术带来的社会影响,2026年,全球围绕大模型的争议已从“能否实现”转向“该如何监管”。 碳捕捉与绿色认证热度持续上升,相关产业迎来新机遇
最突出的案例是2025年美国作家协会起诉OpenAI的案件,协会认为,GPT-5在训练时使用了大量受版权保护的书籍,构成“数字盗版”,OpenAI则辩称,模型生成的内容是“原创的”,不涉及版权问题,这场官司打了18个月,最终法院判决:大模型训练数据若包含受版权保护内容,开发者需支付“数据使用费”,费用标准为每千字0.01美元。
另一个争议是就业冲击,2026年,美国劳工统计局数据显示,过去三年有300万个传统白领岗位被AI取代,主要集中在客服、文案、法律文书等领域,但与此同时,新增了150万个“AI训练师”“模型伦理审查员”等新职业,史密斯教授评价:“这像一场‘职业大洗牌’,工具变量法能预测技术趋势,但无法预测社会如何适应这种变化。”
最令人担忧的是模型偏见问题,2024年,亚马逊的招聘大模型被曝出歧视女性应聘者——因为训练数据中大部分简历