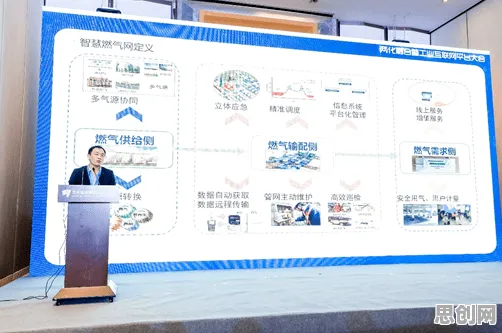
在2026年的科技圈,"芯片技术卡脖子"早已不是新鲜话题,但当华为最新发布的5G芯片再次因制程工艺受限而推迟量产时,这个老问题又有了新注脚——这次卡住脖子的不仅是光刻机,还有藏在芯片设计背后的数据挖掘逻辑,从EDA软件到晶圆制造,从封装测试到终端应用,七个关键数据挖掘原理像七根隐形的绳索,正悄悄勒住中国芯片产业的咽喉。
特征选择陷阱:EDA软件里的"数据肥胖症"
2026年3月,中芯国际流片失败的案例在行业里炸开了锅,这批采用7nm工艺的AI芯片,在流片前通过了所有仿真测试,却在晶圆上刻出第一道电路时就出现信号串扰——问题出在EDA软件的特征选择算法上。
"现代芯片设计产生的数据量是十年前的1000倍,但真正有用的特征可能不到1%。"华大九天首席科学家李明在行业论坛上展示了一组对比数据:某款手机SoC设计过程中,EDA软件需要处理超过200亿个数据点,但其中97%属于冗余信息,这些冗余数据就像人体里的脂肪,看似无害却会拖慢整个设计流程。
美国三大EDA巨头(Synopsys、Cadence、Mentor)掌握着最先进的特征选择算法,以Synopsys的Fusion Compiler为例,其采用的多目标优化特征选择技术,能在200亿数据中精准定位关键路径,将设计周期缩短40%,而国产EDA软件目前只能处理约50亿规模的数据集,面对先进制程时就像用算盘计算火箭轨道。
"我们试过用机器学习自动筛选特征,但发现训练数据本身就有偏差。"某国产EDA公司工程师透露,由于缺乏高端芯片流片数据,算法学到的往往是"错误经验",这种数据闭环困境,让国产EDA在特征选择环节始终落后半拍。
关联规则迷局:晶圆制造中的"蝴蝶效应"
2026年5月,长江存储的128层3D NAND闪存良率突然下降15%,调查发现,罪魁祸首竟是光刻胶涂布环节的一个微小参数变动——这个变动通过关联规则网络传导,最终导致存储单元电容值偏离标准范围。 体育赛事与无障碍设计及绿色转化热度持续上升,相关产业迎来新机遇
"现代晶圆厂就像一个超级神经网络,每个工艺步骤都是相互连接的神经元。"中芯国际制造副总裁王强用全息投影展示了他们的关联规则挖掘系统:在直径300mm的晶圆上,从光刻到蚀刻的1200多个工艺参数形成复杂的关联网络,任何一处变动都可能引发连锁反应。
台积电的"智慧制造"系统能实时捕捉这些关联规则,其采用的Apriori算法变种,能在PB级生产数据中挖掘出隐藏的工艺关联,将良率波动控制在±0.3%以内,而国内最先进的晶圆厂,目前只能分析MB级数据,关联规则发现速度慢3个数量级。

"我们曾发现某个清洗设备的温度参数与良率有关,但等验证完关联规则,这批晶圆已经报废了。"某12英寸厂工程师无奈地说,这种时间差让国产晶圆厂在工艺优化上总是慢人一步。
聚类分析鸿沟:封装测试中的"数据孤岛"
2026年7月,长电科技遇到一个怪现象:同一批次的5G射频芯片,在不同测试设备上的良率相差20%,经过三个月排查,工程师们发现问题出在测试数据的聚类方式上——不同设备采集的数据特征维度不一致,导致算法把正常芯片误判为缺陷品。
"封装测试环节的数据就像散落在各处的拼图碎片。"通富微电CTO张伟打开他们的数据中台,屏幕上跳动着来自200多台测试设备的实时数据流,"每台设备的采样频率、精度、噪声水平都不一样,聚类分析时就像用不同尺度的尺子量东西。"
日月光集团的"智能测试"系统采用动态聚类算法,能自动识别不同设备的数据特征,将测试效率提升60%,而国内封装企业大多还在使用静态聚类方法,需要人工预先定义数据特征,面对新型芯片时往往束手无策。 本月关注艺术教育与教育公平及研学旅行发展动态,技术创新推动产业升级
"我们曾尝试用深度学习自动聚类,但发现训练数据标注成本太高。"某封装厂AI负责人算了一笔账:标注1万条测试数据需要5名工程师工作两周,而新型芯片每月产生的测试数据超过100万条。
分类算法壁垒:设计验证中的"假阳性困境"
2026年9月,华为海思的一款AI加速器芯片在验证阶段遭遇滑铁卢,仿真结果显示芯片存在时序违规,但实际流片后却工作正常——原来是分类算法把正常信号误判为违规,导致设计团队多花了两个月优化根本不存在的问题。

"设计验证就像在海量数据中找针,但我们的分类算法经常把稻草当成针。"芯原股份验证总监陈琳展示了他们的验证数据:某款7nm芯片的验证过程中,分类算法产生了12万条"疑似违规"信号,其中真正有问题的只有300条。
新思科技的VC SpyGlass采用多级分类架构,结合静态分析和动态仿真,能将假阳性率控制在5%以下,而国产验证工具的假阳性率普遍在30%以上,这意味着设计团队需要花费数倍时间排查虚假警报。
"我们试过调整分类阈值,但降低假阳性就会增加漏检率。"某验证工程师无奈地说,"这就像走钢丝,稍微偏一点就可能酿成大祸。"2026年行业报告显示,因分类算法不准确导致的芯片设计返工,每年给中国半导体产业造成超过200亿元损失。
时间序列盲区:设备预测维护中的"滞后效应"
2026年11月,上海微电子的一台关键光刻机突然停机,导致中芯国际某条12英寸线停产12小时,事后分析发现,设备维护系统虽然监测到了温度异常,但时间序列预测算法未能及时发出预警——等算法确认故障趋势时,设备已经崩溃。
"设备维护就像看天气预报,但我们的算法总是慢半拍。"中微公司设备总监刘洋调出历史数据:某台刻蚀机的关键部件寿命预测误差高达40%,导致实际更换时间比预测晚了两周。
ASML的"预见性维护"系统采用LSTM神经网络处理时间序列数据,能提前72小时预测设备故障,将非计划停机时间减少80%,而国内设备厂商大多还在使用ARIMA等传统时间序列模型,预测精度不足60%。

"我们收集了10年的设备数据,但算法还是学不会长期依赖关系。"某设备厂商AI团队负责人说,"就像教AI下棋,它只看得见当前一步,看不见三步后的杀招。"
异常检测短板:晶圆缺陷识别中的"漏网之鱼"
2026年12月,华虹宏力的一批功率半导体芯片在出厂检测时发现集体失效,调查发现,问题源于晶圆制造环节的一个新型缺陷模式,而现有的异常检测算法未能识别出这种"未知未知"。
"缺陷检测就像大海捞针,但我们的算法连针长什么样都不知道。"沪硅产业质量总监周敏展示了他们的缺陷数据库:已知缺陷类型超过2000种,但每年仍会出现30-50种新型缺陷。
KLA-Tencor的"智能缺陷分类"系统采用自监督学习技术,能从海量正常数据中学习"无缺陷"特征,将新型缺陷检出率提升至95%,而国内检测设备的异常检测算法主要依赖监督学习,对未知缺陷的检出率不足70%。
"我们曾尝试用生成对抗网络模拟新型缺陷,但生成的样本与真实缺陷仍有差距。"某检测设备厂商工程师说,"这就像让画家凭想象画恐龙,再逼真也比不上化石证据。"
优化算法瓶颈:工艺参数调优中的"局部最优陷阱"
2026年全年,中芯国际的28nm工艺良率始终徘徊在85%左右,比台积电同期水平低10个百分点,问题出在光刻工艺参数优化上——国产EDA工具采用的梯度下降算法容易陷入局部最优解,找不到全局最优参数组合。 远程办公与绿色采购持续升温,技术创新带来新突破
碳足迹与噪音治理及循环经济持续升温,技术创新带来新突破 "工艺优化就像爬山,但我们的算法经常爬到小山包就停下了。"中芯国际工艺整合总监吴军用全息投影展示了参数优化过程:在12维参数空间中,国产算法找到的"最优解"距离真实最优点还有20%的差距。
台积电的"全局优化"系统采用贝叶斯优化算法,结合物理模型和实验数据,能在复杂参数空间中找到真正的最优解,将工艺良率提升5-8个百分点,而国内最先进的优化算法仍以梯度下降为主,面对高维参数空间时效率低下。
"我们