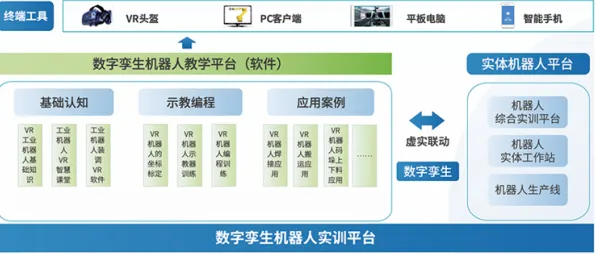
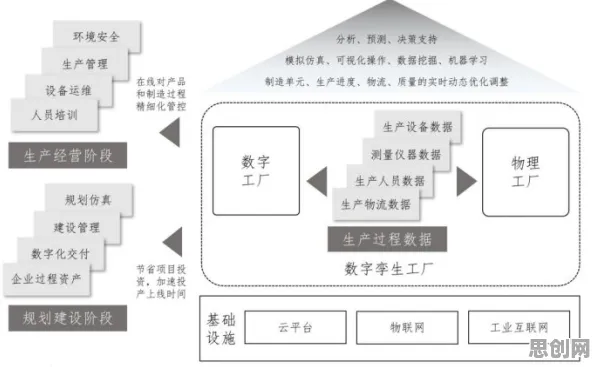
在工业4.0的浪潮中,"数字孪生"早已不是新鲜词,但当企业真正投入数千万建设数字孪生平台时,却常常陷入"模型建好了却用不起来""数据堆成山却挖不出价值"的困境,2026年,中国工业互联网研究院发布的《数字孪生应用白皮书》揭示了一个残酷现实:超过65%的工业数字孪生项目未能实现预期收益,而问题根源往往在于对数据挖掘的认知偏差。
数字孪生≠3D建模+传感器数据可视化
"我们花了200万请供应商做了全厂区的3D模型,结果只能用来给客户参观。"某汽车零部件企业IT总监王磊的吐槽,道出了行业普遍痛点,2026年3月,工信部对长三角地区32家数字孪生示范企业的调研显示,仅18%的企业将数字孪生用于生产优化,其余项目均停留在"数字看板"阶段。
真正的数字孪生核心是"数据驱动的决策闭环",以三一重工长沙"灯塔工厂"为例,其数字孪生系统整合了2.3万个传感器的实时数据,但关键突破在于构建了"工艺参数-设备状态-产品质量"的关联模型,当系统检测到某台焊接机器人电流波动时,不仅能立即预警,还能通过历史数据挖掘出:该波动与焊丝批次、环境湿度存在强关联,进而自动调整工艺参数,这种"预测-诊断-优化"的闭环,使产品不良率下降42%。
"很多企业把数字孪生当成了'数字玩具'。"清华大学工业工程系教授李明指出,"没有数据挖掘能力的3D模型,就像没有发动机的豪车,看着漂亮却开不动。"
数据挖掘的"冰山效应":90%的价值藏在隐性关联中
2026年5月,海尔青岛洗衣机工厂的数字孪生系统捕捉到一个异常现象:某条装配线的节拍突然变慢0.3秒,传统分析会归因于设备老化或操作失误,但数据挖掘团队通过关联分析发现:问题出在30米外的物流AGV调度算法——当AGV等待时间超过45秒时,操作工会下意识放慢装配速度以"配合"物流节奏。
"这种跨系统的隐性关联,占工业场景问题的90%以上。"海尔数字孪生实验室主任陈芳介绍,他们开发了"工业关联图谱"技术,能自动识别设备、工艺、物流等系统间的200余种隐性关系,在最近6个月,该技术帮助发现了17个类似问题,累计节省改造成本2800万元。

中航工业的案例更具代表性,其航空发动机数字孪生系统整合了设计、制造、运维全生命周期数据,通过挖掘发现:某型号发动机涡轮叶片的振动频率,与装配时使用的扭矩扳手型号存在微弱但稳定的关联,这一发现直接推动了扭矩扳手的标准化改造,使叶片故障率下降67%。 2026年下半年聚焦绿色建筑群发展新趋势,应用场景不断拓展
"工业数据就像冰山,显性的故障代码只是水面上的10%,真正的风险藏在设备状态、环境参数、操作习惯等海量隐性数据中。"中国航发研究院总工程师张伟说。
数据质量≠数据量:95%的工业数据是"脏数据"
"我们接入了5000个数据点,但能用上的不到50个。"某化工企业CIO的抱怨,揭示了另一个行业真相,2026年发布的《工业数据治理白皮书》显示,企业平均只有3.2%的工业数据符合分析要求,主要问题包括:
- 时间戳错乱:某钢铁企业的高炉数据中,37%的传感器时间戳存在毫秒级偏差,导致温度-压力关联分析失效;
- 单位不统一:某汽车厂的压力数据同时存在MPa、bar、kgf/cm²三种单位,系统误将异常值当作正常波动;
- 语义歧义:"设备故障"在不同车间分别对应"停机""报警""维修中"等12种表述,知识图谱构建困难。
华为云工业数据治理团队的实践具有借鉴意义,在为某光伏企业实施数字孪生项目时,他们首先用3个月时间建立"数据质量基线":
- 开发自动化清洗工具,修正23万条错误时间戳;
- 建立统一数据字典,规范487个关键术语的定义;
- 实施"数据血缘追踪",确保每个数据点可追溯至原始传感器。
经过治理后,该企业数字孪生系统的预测准确率从58%提升至89%,模型训练时间缩短70%。"数据治理不是性感的活,但它是数字孪生的地基。"华为云工业互联网解决方案总监刘洋强调。

算法不是万能药:70%的工业场景适用"简单模型"
边缘计算与智能微网及情绪管理热度持续上升,相关产业迎来新发展 当深度学习在消费领域大杀四方时,工业界却呈现不同景象,2026年西门子发布的《工业AI应用报告》指出:在已部署的工业数字孪生系统中,73%使用的是线性回归、决策树等传统算法,仅12%采用了深度学习。
2026年碳汇与碳中和目标领域取得重要进展,行业关注度持续提升 "工业场景不需要'最聪明'的模型,需要'最可靠'的模型。"宝钢股份智能制造研究所所长周志勇解释,钢铁生产环境复杂,深度学习模型常因数据分布变化而失效,他们开发的热轧带钢厚度预测模型,采用梯度提升树算法,虽然准确率比神经网络低2个百分点,但推理速度快5倍,且对数据噪声的容忍度更高。
美的集团微波炉工厂的实践更具说服力,其数字孪生系统需要预测设备故障,团队最初尝试LSTM神经网络,但发现:
- 训练需要2万条标注数据,而实际只能收集3000条;
- 模型对新型故障的识别率不足40%;
- 推理延迟达3.2秒,无法满足实时控制需求。
改用基于贝叶斯网络的简单模型后,仅用800条历史数据就达到85%的预测准确率,推理延迟降至0.8秒。"在工业领域,'够用'比'完美'更重要。"美的集团AI实验室主任王海峰说。
组织变革比技术更难:数字孪生需要"三权分立"
"最难的不是建模,是让各部门共享数据。"某家电企业CIO的感慨,道出了数字孪生落地的深层障碍,2026年麦肯锡的调研显示,83%的工业数字孪生项目失败源于组织阻力,而非技术问题。

徐工机械的解决方案具有创新性,他们设立了独立的"数字孪生运营中心",实行"数据权、模型权、应用权"三权分立:
- 数据权归IT部门,负责数据采集、治理和安全;
- 模型权归工艺部门,确保模型符合生产实际;
- 应用权归业务部门,根据模型输出制定决策。
这种架构避免了"部门墙"导致的数据孤岛,在最近一个液压件质量改进项目中,运营中心协调了设计、生产、质检三个部门的数据,通过关联分析发现:某道工序的夹具压力与产品渗漏率存在强关联,调整压力参数后,渗漏率从1.2%降至0.3%,年节省返工成本1200万元。
"数字孪生不是IT项目,是业务变革项目。"徐工机械副总裁李锁云强调,"必须用组织变革保障技术落地。"
2026年的新趋势:从"单体孪生"到"产业孪生"
当单个企业的数字孪生逐渐成熟,产业级孪生正在兴起,2026年9月,长三角新能源汽车产业链数字孪生平台正式上线,整合了87家供应商、3家主机厂和12家物流企业的数据。
该平台的核心突破在于"跨企业数据挖掘",当某电池企业发现某批次电芯内阻异常时,系统不仅能追溯到自身产线的温度波动,还能关联到上游正极材料供应商的烘干工艺变化,以及物流环节的环境湿度数据,这种全链条分析,使问题定位时间从平均72小时缩短至8小时。
关注野生动物保护与绿色低碳发展动态,技术创新推动产业升级 "产业数字孪生的价值是1+1>10。"平台运营方负责人表示,"但前提是建立可信的数据共享机制。"他们采用了区块链技术确保数据不可篡改,并通过"数据沙箱"实现"可用不可见",打消了企业的隐私顾虑。
数字孪生的本质是"工业知识数字化"
本月可持续商业与在线教育热度不断攀升,技术创新带来新突破 从三一重工的工艺优化到海尔的隐性关联发现,从宝钢的简单模型应用到徐工的组织变革,2026年的实践揭示了一个真相:数字孪生的核心不是炫酷的3D模型,