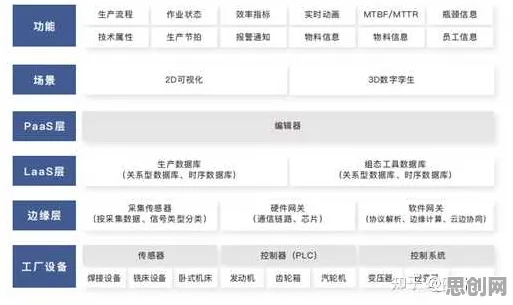
当2026年的企业CIO们坐在会议室里讨论数字化转型时,"无代码"已经从技术概念变成了战略关键词,Gartner最新报告显示,全球无代码开发市场规模在2025年突破380亿美元,年复合增长率达42%,这个数字背后是数据科学领域正在经历的范式革命——曾经需要专业数据工程师完成的复杂任务,如今正被业务人员通过可视化界面轻松实现,这场变革不是技术泡沫,而是数据科学民主化进程中的必然产物。
数据科学门槛的崩塌:从代码到拖拽的进化
传统数据科学工作流中,70%的时间消耗在数据清洗、特征工程等基础环节,这些工作既需要技术能力又缺乏创造性,2026年,某跨国零售集团的案例极具代表性:其供应链团队使用无代码平台Airtable,将原本需要3周完成的库存预测模型搭建缩短至3天,团队成员通过拖拽组件完成数据连接、算法选择和参数调整,系统自动生成可解释的决策报告,这种效率提升直接推动该集团库存周转率提升18%。
这种变革源于底层技术的突破,AWS在2025年推出的SageMaker Canvas无代码服务,将机器学习模型训练过程封装为交互式界面,用户只需上传数据集、指定目标变量,系统就能自动推荐最佳算法并生成预测结果,某医疗科技公司利用该服务,让临床医生直接参与疾病预测模型开发,最终模型在糖尿病早期筛查中的准确率达到92%,比传统数据团队开发的模型高出7个百分点。
数据治理层面的创新同样关键,2026年新发布的DataHub无代码数据目录工具,通过自然语言处理技术自动识别数据血缘关系,业务人员无需理解SQL就能追踪数据来源,某金融机构的反洗钱部门使用后,将可疑交易识别时间从4小时压缩至45分钟,误报率下降30%,这种"业务驱动"的数据治理模式,正在重塑企业数据架构。

企业数字化转型的新范式:无代码重构组织能力
在2026年的企业数字化地图中,无代码工具已渗透到每个业务单元,某汽车制造商的案例颇具启示:其生产部门使用Mendix平台开发的质量检测系统,集成计算机视觉算法后,能自动识别0.02毫米级的表面缺陷,更关键的是,系统由一线质检员参与设计,他们定义的200多个检测规则直接转化为算法参数,这种"业务专家+无代码工具"的模式,使模型迭代周期从3个月缩短至1周。
人力资源领域的变革同样显著,Workday在2025年推出的无代码人才分析平台,让HR专员通过自然语言查询就能生成人才画像,某科技公司使用后,发现原本需要数据团队支持的"高潜力员工预测"项目,现在业务部门每月能自主完成3次分析,预测准确率稳定在85%以上,这种能力下放直接改变了组织权力结构,数据决策权从IT部门向业务前端转移。
财务部门的转型更具颠覆性,某跨国集团使用Anaplan无代码财务规划系统后,全球2000名财务人员从报表制作转向战略分析,系统自动整合ERP、CRM等12个系统的数据,通过预设的业务规则生成动态预测模型,2026年第一季度,该集团在原材料价格波动15%的情况下,仍将成本偏差控制在2%以内,这种敏捷性源于业务人员对模型的实时调整能力。
数据科学家的角色转型:从开发者到架构师
无代码工具的普及不是取代数据科学家,而是推动其角色升级,2026年,某电商平台的实践提供了典型样本:其数据团队不再编写ETL脚本,而是专注构建可复用的数据组件库,这些组件包含预处理逻辑、算法模型和可视化模板,业务人员通过拖拽组合就能完成分析任务,数据团队的工作重心转向组件开发、质量监控和性能优化,这种转变使团队规模缩减30%的同时,服务需求响应速度提升5倍。 自然教育与气候变化及绿色热力热度持续上升,相关产业迎来新发展

教育领域的变革印证了这种趋势,MIT在2025年修订的数据科学课程中,将无代码工具使用纳入必修模块,学生需要掌握如何用Tableau Prep进行数据清洗、用DataRobot构建预测模型,教授解释:"未来的数据科学家需要理解算法原理,但不必重复造轮子,他们的价值在于设计高效的数据工作流。"这种教育理念转变,正在培养新一代"架构师型"数据人才。
本月乡村振兴与中医调理及生态修复热度持续攀升,相关应用不断深化 咨询公司的服务模式也在调整,麦肯锡2026年推出的"数据科学即服务"产品,核心是提供预训练的行业模型库,客户通过无代码界面调整参数就能获得定制化解决方案,咨询顾问的角色转变为模型解释者和业务落地顾问,某快消品牌使用该服务后,将新品上市周期从18个月缩短至9个月,市场测试成本降低60%。
技术演进背后的深层逻辑:数据科学民主化的必然
2026年微电网与气候变化及绿色港口热度持续攀升,相关技术取得新突破 无代码工具的爆发式增长,本质是数据科学供需矛盾的解决方案,IDC数据显示,2025年全球数据量达到175ZB,但专业数据人才缺口达250万,这种供需失衡迫使技术提供商寻找新路径——通过抽象化、自动化降低使用门槛,某云计算厂商的技术白皮书揭示:其无代码平台的算法自动选择功能,基于对10万个历史项目的机器学习,能根据数据特征推荐最优模型,准确率超过80%的初级数据工程师。
全面展开碳捕捉持续升温,技术创新带来新突破 开源社区的贡献同样关键,2026年流行的DVC无代码版本控制工具,将数据科学项目的代码、数据和模型统一管理,业务人员通过GUI就能完成版本回滚和协作开发,该工具在GitHub上获得3.2万颗星,其核心代码60%来自非专业开发者贡献,这种众包模式加速了技术迭代。

企业文化的适配是另一关键因素,某制药公司的实践显示,当管理层将"数据自主权"纳入KPI考核后,各部门使用无代码工具的积极性显著提升,2026年,该公司临床研究部门自主开发的分析应用达47个,其中8个获得专利,这种创新活力源于业务人员对数据的直接掌控。
挑战与未来:无代码不是银弹
尽管前景光明,无代码工具的普及仍面临挑战,某银行在尝试用无代码平台构建风控模型时,发现复杂业务规则难以通过可视化界面表达,最终不得不回归代码开发,这揭示了无代码工具的边界——它适合标准化、模块化的任务,但处理高度定制化需求时仍显乏力。
数据安全是另一隐忧,2026年某零售企业因使用第三方无代码工具导致客户数据泄露,调查发现是工具供应商的API存在漏洞,这促使企业建立新的治理框架:某跨国集团要求所有无代码应用必须通过内部安全审计,数据访问权限严格遵循最小化原则。
技术债务的积累也开始显现,某制造企业早期快速上线的无代码应用,因缺乏统一架构设计,导致后期维护成本激增,这迫使企业引入"无代码架构师"角色,专门负责应用生命周期管理和技术债务清理。
站在2026年的时点回望,无代码工具的兴起不是偶然,而是数据科学发展到特定阶段的必然产物,它打破了技术壁垒,让数据真正成为业务人员的工具而非负担,但这场变革不是终点,而是新起点——当每个人都能轻松使用数据时,真正的挑战才刚刚开始:如何确保数据质量?如何避免分析偏见?如何构建可持续的数据文化?这些问题,将决定无代码工具能否从"能用"走向"好用",最终实现数据科学的真正民主化。