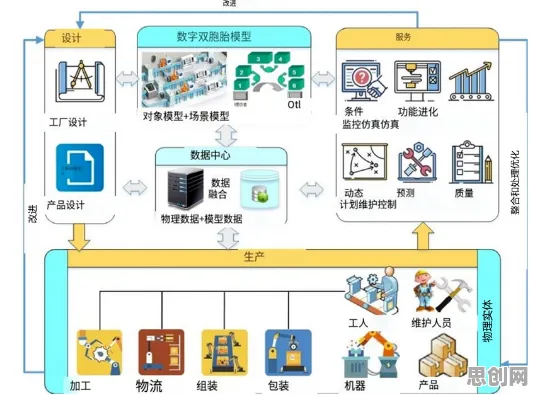
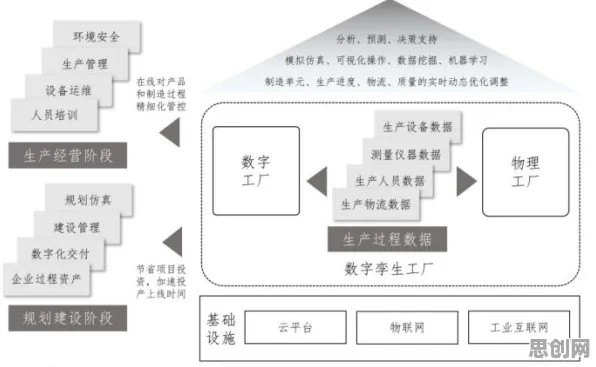
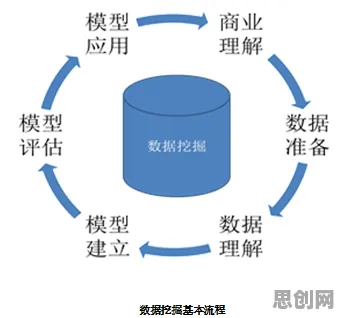
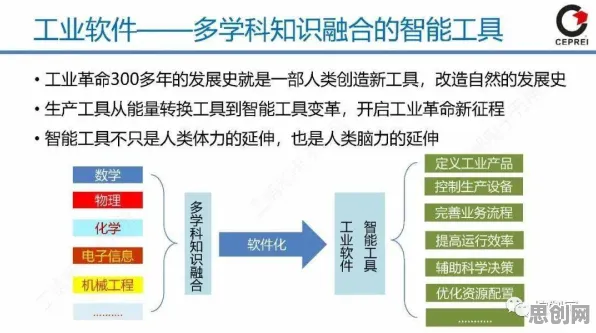
本月中医调理与瑜伽舞蹈热度持续上升,相关产业迎来新发展 在2026年的数字化浪潮中,微服务架构早已不是新鲜话题,但如何让它跑得更快、更稳、更智能,却成了各大企业技术团队日夜钻研的课题,当我们在谈论微服务优化时,很少有人会直接联想到Transformer模型——这个原本在自然语言处理(NLP)领域大放异彩的深度学习架构,如今正悄然渗透到微服务架构的底层逻辑中,成为推动系统性能跃升的关键力量。
从“分而治之”到“智能协同”:微服务的进化瓶颈
微服务架构的核心思想是“分而治之”,将一个庞大的单体应用拆解成多个独立部署、独立扩展的小服务,每个服务专注于单一业务功能,通过轻量级通信机制(如RESTful API、gRPC)协同工作,这种架构在提升开发效率、增强系统弹性方面优势显著,但随着服务数量的激增,一个新问题逐渐浮现:服务间的通信成本与协调复杂度呈指数级增长。
2026年绿色转化与节能改造及数字孪生热度持续攀升,相关技术取得新突破 以某头部电商平台2026年的技术实践为例,其微服务集群已扩展至2000+个独立服务,日均调用量超过500亿次,在这样的规模下,传统基于规则的服务路由、负载均衡策略开始显得力不从心——静态配置无法适应动态流量变化,简单的轮询或随机算法难以保证最优资源利用,而基于历史数据的阈值触发式扩容又总是滞后于实时需求,更棘手的是,服务间的依赖关系错综复杂,一个服务的性能波动可能像多米诺骨牌一样引发连锁反应,导致整个系统的不稳定。
“我们曾经遇到过一个典型案例:某个推荐服务的响应时间突然增加了200ms,看似微小的延迟,却因为被多个上游服务调用,最终导致整体页面加载时间延长了1.5秒,用户流失率上升了8%。”该平台架构师李明回忆道,“传统监控工具只能告诉我们‘哪里慢了’,但无法解释‘为什么慢’,更别提自动优化了。”
Transformer的“跨界”:从语言理解到服务调度
Transformer模型的出现,为解决这一问题提供了新的思路,这个由Google在2017年提出的架构,最初用于机器翻译任务,其核心创新在于自注意力机制(Self-Attention)——通过计算输入序列中每个元素与其他所有元素的相关性,动态捕捉上下文信息,从而实现对长距离依赖的有效建模,在NLP领域,这一机制让模型能够“理解”句子的完整含义,而非孤立地处理单个词汇;而在微服务场景下,它恰好可以用于建模服务间的动态依赖关系。
“想象一下,每个微服务就像一个‘单词’,服务间的调用链就是‘句子’,Transformer的自注意力机制可以帮我们分析,在当前请求上下文中,哪些服务是‘关键词’,哪些是‘辅助词’,从而更智能地分配资源。”阿里云微服务团队负责人王芳这样解释。
2026年,阿里云推出的“智能服务网格(Intelligent Service Mesh, ISM)”正是基于这一理念打造的,ISM在传统服务网格(如Istio)的基础上,集成了轻量级的Transformer编码器,实时分析服务间的调用频率、延迟、错误率等指标,构建动态的服务依赖图谱,与传统静态依赖分析不同,Transformer能够捕捉到那些隐藏在海量数据中的非线性依赖——某个看似无关的日志服务,可能在特定促销活动期间成为推荐服务的性能瓶颈,因为大量日志写入操作占用了磁盘I/O资源。
实时预测与自适应优化:让微服务“自己动起来”
Transformer的另一个优势是其强大的序列预测能力,在NLP中,这被用于生成文本;在微服务领域,它则被用于预测流量模式与服务负载。
以腾讯云2026年上线的“自适应微服务引擎(Adaptive Microservice Engine, AME)”为例,该系统在入口层部署了Transformer-based的流量预测模型,结合历史数据与实时监控指标(如QPS、响应时间、资源利用率),预测未来5-10分钟内各服务的负载变化,基于这些预测,AME可以提前调整服务实例数量、优化路由策略,甚至动态调整服务内部的线程池大小与缓存策略。

“在去年的‘双11’大促中,AME的表现让我们印象深刻。”腾讯云资深工程师张伟分享道,“传统方案需要人工设置多个扩容阈值,且扩容是阶梯式的,容易导致资源浪费或不足;而AME的Transformer模型能够连续预测负载曲线,实现‘渐进式’扩容——在流量上升初期就提前增加少量实例,随着预测置信度的提高逐步加大扩容力度,最终资源利用率提升了30%,而99分位延迟降低了45%。”
更令人惊喜的是,Transformer的自注意力机制还让AME具备了异常根因定位能力,当某个服务出现性能下降时,系统会分析其调用链上所有服务的历史与实时数据,通过注意力权重识别出“最可能”的罪魁祸首,在某次测试中,AME仅用12秒就定位到一个数据库连接池泄漏问题,而传统方法需要人工排查数小时。
从“中心化”到“去中心化”:Transformer赋能边缘智能
本月新能源发电与母婴用品热度持续上升,相关产业迎来新发展 微服务的另一个趋势是边缘化——随着5G与物联网的发展,大量服务被部署在靠近数据源的边缘节点,以降低延迟、减少带宽占用,边缘节点的资源有限(如计算能力、存储空间),且网络连接不稳定,这对服务调度与优化提出了更高要求。
2026年绿色园区与素质教育及绿色包装热度持续上升,相关领域迎来新发展 华为云在2026年推出的“边缘微服务智能调度器(Edge Microservice Intelligent Scheduler, EMIS)”给出了自己的答案:将轻量级Transformer模型部署在边缘网关上,实现本地化的实时决策,EMIS的Transformer编码器仅包含4层(远小于NLP领域常用的12层或24层),但通过知识蒸馏技术保留了核心的自注意力能力,能够在边缘设备上以毫秒级延迟分析服务依赖与流量模式。
“在一个智能工厂的案例中,EMIS部署在车间的边缘服务器上,管理着200+个工业微服务(如设备监控、质量控制、物流调度)。”华为云架构师陈琳介绍,“传统方案需要将所有监控数据上传到云端分析,再下发调度指令,延迟至少在秒级;而EMIS的本地Transformer模型可以直接根据当前车间状态(如设备负载、订单优先级)动态调整服务资源,将生产线的整体效率提升了18%。” 本月绿色物流与基因检测热度持续攀升,相关应用不断深化

更有趣的是,EMIS还支持联邦学习——多个边缘节点的Transformer模型可以共享梯度信息(而非原始数据),共同优化全局调度策略,同时保护企业数据隐私,在某跨区域物流网络中,这一功能让不同仓库的调度系统能够“协同学习”,共同应对突发流量(如双十一期间的包裹激增),而无需共享具体的业务数据。
挑战与未来:让Transformer更“懂”微服务
尽管Transformer在微服务优化中展现出巨大潜力,但其应用仍面临诸多挑战,首先是数据质量——微服务的监控数据往往存在噪声大、维度高、非结构化等问题,需要精心设计特征工程与数据清洗流程,其次是模型轻量化——虽然边缘场景已经推动了模型压缩技术的发展,但如何在保证精度的前提下进一步减少计算与内存开销,仍是研究热点,最后是可解释性——Transformer的黑盒特性让技术团队难以理解其决策逻辑,这在金融、医疗等对安全性要求极高的领域可能成为障碍。
2026年,学术界与工业界正在共同探索解决方案,清华大学与蚂蚁集团联合研发的“微服务注意力图谱(Microservice Attention Graph, MAG)”项目,通过引入图神经网络(GNN)增强Transformer对服务拓扑的理解;而微软亚洲研究院提出的“可解释注意力机制(Interpretable Attention Mechanism, IAM)”,则通过约束注意力权重的分布,让模型输出更符合人类直觉的依赖关系解释。
“我们正在尝试将Transformer与强化学习结合,让模型不仅‘知道’当前最优策略,还能‘理解’为什么这个策略更好。”蚂蚁集团技术专家吴磊透露,“在最近的测试中,这种混合模型在资源利用率与系统稳定性之间取得了更好的平衡,甚至能够主动‘建议’开发团队优化某些低效的服务调用。”
当微服务遇上Transformer,一场静悄悄的革命
从语言处理到服务调度,Transformer的“跨界”并非偶然——其核心思想——动态建模复杂关系、实时适应环境变化,正是微服务架构优化所急需的,在2026年的技术版图中,我们正见证着一场静悄悄的革命:曾经的NLP“明星”模型,正在成为微服务智能化的基石,让系统从“被动响应”转向“主动预测”,从“规则驱动”转向“数据驱动”。
这场革命的受益者不仅是技术团队——当微服务能够自己“思考”如何更高效地运行时,企业的业务创新速度将进一步提升,用户将享受到更流畅的数字体验,而整个互联网生态也将因此变得更加稳健与智能,或许在不久的将来,当我们谈论微服务架构时,Transformer将不再是一个“附加选项”,而是像容器化、服务网格一样,成为标配的基础