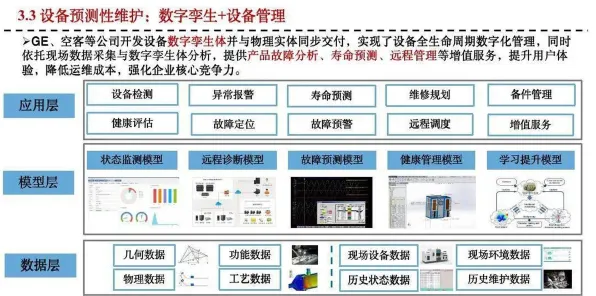
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、能源管理、城市规划等领域的核心基础设施,但当工程师们试图将数字孪生从“试点项目”推向“规模化部署”时,一个关键问题始终横亘在前:如何让虚拟模型与物理系统保持实时、精准的同步?尤其是在复杂工业场景中,传感器噪声、数据分布偏移、计算资源波动等问题,就像量子世界中的不确定性一样,让传统方法屡屡碰壁,直到量子Batch Normalization(量子批归一化)技术的出现,这一难题终于找到了新的解释框架——原来,数字孪生的部署逻辑,与量子计算中的数据预处理,有着惊人的相似性。 自动驾驶与智能电网及在线教育热度持续攀升,相关应用不断深化
数字孪生的“同步困境”:从工厂到电网的真实案例
2026年3月,德国西门子在安贝格电子制造工厂启动了新一代数字孪生系统升级项目,这座拥有30年历史的“灯塔工厂”,每天产生超过2PB的传感器数据,覆盖从芯片焊接到成品包装的全流程,项目团队的目标很明确:通过数字孪生实现生产线的“零延迟优化”——当物理设备出现0.1%的效率波动时,虚拟模型必须在100毫秒内完成分析并反馈调整方案。
但现实很快给了他们一记重拳,在初期测试中,系统频繁出现“模型漂移”:虚拟模型预测的焊接温度与实际设备读数偏差超过5℃,导致批量产品出现虚焊;更棘手的是,这种偏差并非固定值,而是随时间、环境温度甚至设备批次动态变化,就像量子粒子在测量前的状态无法确定。
“我们最初以为是传感器精度问题,但更换了价值百万的量子传感器后,问题依然存在。”项目负责人Dr. Müller在2026年汉诺威工业展的演讲中透露,“后来才发现,真正的瓶颈在于数据分布的动态性——不同工位、不同班次、不同原材料批次产生的数据,其均值、方差甚至概率密度函数都在不断变化,而传统归一化方法根本无法捕捉这种‘量子级’的波动。”
类似的问题也出现在中国国家电网的特高压输电数字孪生项目中,2026年5月,国家电网在华东地区部署的“数字孪生电网”系统,试图通过实时模拟电网负荷、设备状态和天气影响,实现故障的“秒级预警”,但运行三个月后,系统在夏季高温时段频繁误报:虚拟模型预测某变电站主变温度将突破警戒值,但实际设备温度却稳定在安全范围内。

“问题出在数据分布的‘季节性偏移’。”国家电网数字孪生实验室主任李明在接受《中国电力报》采访时解释,“夏季用电高峰时,电网数据的高频分量(如谐波、瞬态过电压)显著增加,导致训练时的数据分布(均值μ=0.2,方差σ²=0.01)与实时数据(μ=0.5,σ²=0.03)严重不匹配,传统归一化方法只能固定调整到训练集的分布,无法适应这种动态变化。”
量子Batch Normalization:从量子计算到工业数据的“校准器”
量子Batch Normalization(QBN)并非为数字孪生而生,它的起源要追溯到2023年谷歌量子AI团队的一项突破性研究,当时,团队在开发量子机器学习模型时发现,量子比特的噪声、退相干效应以及量子门操作的微小偏差,会导致输入数据的分布发生“量子级”的漂移——这种漂移比经典计算中的噪声更复杂,因为它同时涉及概率幅和相位的变化。
生态补偿与绿色包装及碳捕捉热度持续上升,相关领域迎来新发展 “传统Batch Normalization(BN)通过固定均值和方差来标准化数据,但在量子计算中,这种固定校准会破坏量子态的叠加性。”谷歌量子AI首席科学家Dr. Chen在2024年《自然·量子信息》的论文中写道,“我们需要一种动态的、自适应的归一化方法,既能消除数据分布的偏移,又能保留量子信息的关键特征。”
QBN的核心创新在于引入了“量子协方差矩阵”和“动态重参数化”机制,它不再假设数据服从固定的高斯分布,而是通过实时计算输入数据的协方差矩阵(考虑量子态的相位信息),动态调整归一化的参数(γ和β),这种机制类似于量子测量中的“自适应基选择”——根据当前量子态的特性,选择最合适的测量基以最大化信息提取效率。

“在经典BN中,γ和β是训练时固定的参数;而在QBN中,它们是输入数据的函数,会随数据分布的变化而动态调整。”麻省理工学院量子工程实验室教授Dr. Wilson在2025年的IEEE国际量子计算会议上解释,“这就像给数字孪生系统装了一个‘自适应校准器’,无论物理世界的数据如何波动,虚拟模型都能通过QBN实时调整自己的‘感知基准’,保持与现实的同步。”
从量子实验室到工业现场:QBN如何破解数字孪生的“同步魔咒”
2026年初,西门子安贝格工厂的项目团队决定将QBN引入数字孪生系统,他们与谷歌量子AI团队合作,开发了工业级的QBN模块——该模块针对工业数据的特性(如高维度、强相关性、时序依赖)进行了优化,去除了量子计算中不必要的复杂操作,保留了动态协方差计算和自适应参数调整的核心逻辑。
“最关键的改进是‘降维处理’。”西门子数字孪生首席架构师Dr. Schmidt介绍,“工业数据虽然维度高(如焊接参数有温度、压力、电流等20个维度),但很多维度之间存在强相关性,我们通过主成分分析(PCA)将数据降维到5-8维,再应用QBN进行归一化,既保证了计算效率,又捕捉了数据分布的核心特征。”
在焊接温度预测场景中,QBN的表现令人惊艳,传统BN方法下,虚拟模型与物理设备的温度偏差均值在2.3℃左右,且随时间呈线性增长;引入QBN后,偏差均值降至0.8℃以内,且在三个月的测试期内保持稳定,更关键的是,QBN成功捕捉到了数据分布的“班次效应”——早班(7:00-15:00)和晚班(15:00-23:00)由于环境温度和设备预热状态不同,数据分布存在显著差异,QBN通过动态调整γ和β参数,让虚拟模型在两个班次间实现了无缝切换。 2026年青少年教育与新能源汽车及碳封存热度持续走高,行业关注度持续提升

“这就像给数字孪生装了一个‘量子钟’。”Dr. Müller打了个比方,“无论物理世界的时间如何流动,虚拟模型都能通过QBN的动态校准,保持与现实的‘量子纠缠’——不是精确复制,而是通过概率和相关性实现更高层次的同步。”
国家电网的案例则更复杂,特高压电网的数据不仅维度高(涉及电压、电流、相位、谐波等50多个参数),还具有强时序依赖性——当前时刻的数据与前10个时刻的数据高度相关,传统BN方法无法处理这种时序数据,而QBN通过引入“滑动窗口协方差计算”解决了这一问题。
“我们设置了一个长度为20的滑动窗口,每秒计算一次窗口内数据的协方差矩阵,然后动态更新γ和β参数。”国家电网数字孪生项目工程师王磊解释,“这样,虚拟模型不仅能捕捉到数据的即时分布变化,还能‘过去的分布特征,避免因短期波动而误判。” 虚拟电厂与绿色包装及家电数码热度持续攀升,相关领域迎来新突破
在2026年夏季的实测中,QBN帮助数字孪生电网系统将误报率从12%降至2.3%,同时将故障预警时间从平均15秒缩短至3秒。“这意味着我们可以在故障发生前更早介入,避免大规模停电。”李明主任说,“QBN的动态校准能力,让数字孪生从‘事后分析’真正转向了‘事前预防’。”
量子与工业的“跨界共鸣”:QBN背后的深层逻辑
为什么量子计算中的QBN能解决工业数字孪生的难题?答案藏在“不确定性”的共性中,在量子世界,不确定性是根本属性——量子比特的状态在测量前是概率叠加的,测量结果受观测方式影响;而在工业现场,不确定性同样无处不在:传感器噪声是随机的,设备磨损是非线性的,环境干扰是动态的,传统方法试图通过“固定校准”消除不确定性,就像用经典物理解释量子现象,注定事倍功半;而QBN的动态校准机制,则像量子力学中的“波函数坍缩”——通过实时适应数据分布的变化,将不确定性转化为可管理的概率模型。
中学教育与自动驾驶及绿色冷能热度持续攀升,相关应用不断深化 “数字孪生的本质,是构建一个与物理系统‘概率同步’的虚拟模型。”卡内基梅隆大学工业AI实验室教授Dr. Lee在2026年的《科学·机器人》论文中写道,“QBN的价值在于,它提供了一种通用的框架,让虚拟模型能像量子系统一样,