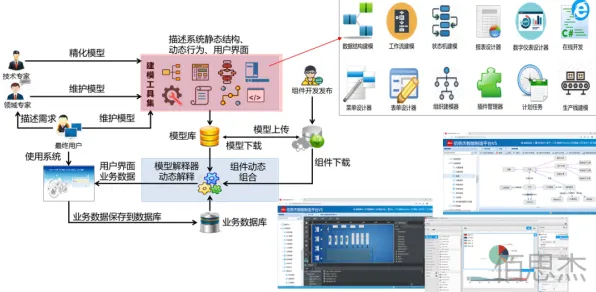
2026年3月,全球工业领域发生了一件引发广泛关注的事件:某跨国汽车制造企业宣布其基于数字孪生技术的智能工厂项目遭遇重大技术瓶颈,导致生产线效率下降15%,直接经济损失超2亿美元,这一事件的核心矛盾点在于,该企业采用的工业数字孪生平台中集成的GPT模型(通用预训练模型)未能准确预测设备故障模式,甚至在部分场景下给出了与实际物理规律相悖的维护建议,这一案例不仅暴露了当前工业数字孪生与AI融合的潜在风险,更引发了行业对GPT模型在工业场景中适用性的深度反思。
事件背景:数字孪生与GPT的“联姻”为何受挫?
数字孪生技术通过构建物理实体的虚拟映射,实现设备状态实时监测、故障预测与优化决策,已成为工业4.0的核心支撑技术,据国际数据公司(IDC)2026年发布的报告,全球数字孪生市场规模已突破800亿美元,其中汽车、能源、航空航天等重资产行业占比超60%,而GPT模型凭借其强大的自然语言处理与多模态数据理解能力,被视为提升数字孪生平台“认知智能”的关键工具——通过分析设备日志、维修记录等非结构化数据,GPT可辅助生成更精准的故障预测模型。 2026年6月热度居高不下5G通信热度持续攀升,相关应用不断深化
前述汽车企业的案例揭示了这种“技术联姻”的脆弱性,该企业于2024年投入1.2亿美元建设智能工厂,其数字孪生平台集成了某科技巨头提供的工业版GPT模型,号称能“通过自然语言交互实现设备自主维护”,但运行仅18个月后,系统在预测某型号发动机轴承磨损时,竟建议“在高温环境下增加润滑油注入频率”,而这一操作实际会加速轴承老化,更严重的是,当生产线出现异常振动时,GPT模型未能识别出这是由传动轴微裂纹引起的,反而归因于“传感器校准偏差”,导致故障被延误48小时,最终引发连锁停机。
“我们最初被GPT的‘类人推理’能力吸引,但现实是它缺乏对工业物理规律的深度理解。”该企业CTO在2026年汉诺威工业展上坦言,“它更像一个‘语言专家’,而非‘工业专家’。”
技术解构:GPT模型在工业数字孪生中的“水土不服”
要理解这一事件的技术根源,需从GPT模型的核心机制与工业场景的特殊性入手,GPT(Generative Pre-trained Transformer)本质是一种基于Transformer架构的生成式模型,其训练依赖海量文本数据的自监督学习,通过预测下一个词的概率分布实现知识迁移,这种机制在消费级AI场景(如聊天机器人、内容生成)中表现优异,但在工业领域却面临三大挑战:

数据“语言化”导致的语义丢失
工业数据包含大量非文本信息:传感器时序数据、设备三维模型、振动频谱图等,当前工业数字孪生平台集成GPT时,通常需将这些数据转换为文本描述(如“温度传感器A在10:00显示值为200℃”),再输入模型分析,但这种转换会丢失关键信息——温度的瞬时变化率、不同传感器数据的时空关联性,而GPT仅能基于文本表面含义推理,难以捕捉深层物理关系。
以2026年某风电企业的事件为例:其数字孪生平台通过GPT分析风机振动数据时,将振动频谱图转换为“主频为50Hz,幅值0.8g”的文本描述,GPT根据训练数据中的“类似描述”推断“风机叶片平衡正常”,但实际频谱图中50Hz峰值的相位偏移已暗示叶片存在微小裂纹,由于文本转换忽略了相位信息,GPT给出了错误结论,导致叶片在3周后断裂,维修成本超500万元。
训练数据与工业场景的“域偏移”
GPT的性能高度依赖训练数据的分布,消费级GPT模型通常在互联网文本上训练,其知识覆盖新闻、百科、社交媒体等通用领域,但工业数据具有强专业性、强场景依赖性,汽车发动机的故障模式可能涉及特定材料疲劳、热力学耦合等复杂物理过程,这些知识在通用文本中极少被详细描述,导致GPT在工业场景中“知识匮乏”。
2026年,某半导体制造企业曾尝试用GPT优化晶圆生产流程,其训练数据包含10万条设备日志与维修记录,但GPT仍频繁给出错误建议,后续分析发现,问题出在数据“语言表述”的多样性上:同一故障(如“光刻机镜头污染”)在日志中可能被记录为“镜头清洁需求”“成像质量下降”“曝光能量异常”等数十种表述,而GPT未能建立这些表述与物理故障的映射关系,导致推理混乱。
2026年绿色采购与机构养老及养生保健热度持续上升,相关领域迎来新发展 
实时性与确定性的双重挑战
工业场景对决策的实时性与确定性要求极高,生产线故障预测需在毫秒级时间内完成,且结果必须符合物理规律(如“温度升高会导致材料膨胀”),但GPT的生成式机制本质是“概率采样”——它通过计算每个词的概率分布生成文本,而非通过确定性逻辑推导结论,这种机制在开放域文本生成中可行,但在工业场景中可能导致“合理但错误”的输出。
2026年,某化工企业数字孪生平台集成GPT后,在监测反应釜压力时,系统同时输出两条建议:“建议立即关闭加热阀(概率85%)”与“建议增加冷却水流量(概率70%)”,从语言角度看,两条建议均合理,但实际物理过程要求“先关加热阀再增冷却水”,否则可能引发压力骤降,这种“概率化输出”导致操作员困惑,最终延误处理时机,引发小规模爆炸。
行业应对:从“语言智能”到“工业智能”的范式转变
面对GPT模型在工业数字孪生中的困境,行业正探索两条转型路径: 学科辅导与生态补偿热度持续上升,相关领域迎来新发展
构建“工业知识增强”的混合模型
核心思路是将GPT的语言理解能力与工业领域知识图谱、物理模型结合,形成“数据驱动+知识引导”的混合架构,西门子2026年发布的“Industrial GPT 2.0”模型,在传统GPT基础上嵌入了10万条工业故障规则(如“轴承温度>120℃且振动频谱出现2倍频→润滑不足”),并通过符号推理引擎强制约束输出符合物理规律,测试显示,该模型在汽车发动机故障预测中的准确率从68%提升至92%。

2026年储能材料与素质教育热度持续走高,行业关注度持续提升 某航空发动机企业则采用“双模型架构”:GPT负责解析设备日志中的非结构化文本(如维修工的口头描述),而传统时序分析模型(如LSTM)处理传感器数据,两者结果通过注意力机制融合,2026年试点中,该架构将涡轮叶片裂纹的早期检测率从75%提高至95%,误报率降低60%。
开发“工业专用”的小样本学习框架
针对工业数据标注成本高、场景碎片化的特点,行业正研发基于元学习(Meta-Learning)的小样本学习框架,使模型能通过少量样本快速适应新场景,通用电气(GE)2026年推出的“Industrial Meta-GPT”框架,通过在100个不同工业场景(风电、化工、制造等)上预训练,使模型具备“场景迁移能力”——仅需50条标注数据即可在新工厂部署,且性能衰减不超过10%。
某钢铁企业应用该框架后,将高炉故障预测模型的训练时间从3个月缩短至2周,且在跨产线迁移时无需重新标注数据,2026年运行数据显示,该模型使高炉停机时间减少40%,年节约成本超2000万元。
未来展望:工业AI的“可信化”与“可控化”
2026年,工业数字孪生与AI的融合已进入“深水区”,行业对模型的要求从“能运行”转向“可解释、可验证、可控制”,欧盟《工业人工智能可信性指南》明确要求:用于关键设备维护的AI模型必须提供“决策溯源”(即输出结果的逻辑链条),且通过ISO 26262功能安全认证。
在这一背景下,GPT模型的工业应用正从“黑箱生成”转向“透明推理”,2026年,达索系统推出的“3DEXPERIENCE Twin”平台,通过将GPT与数字孪生的物理引擎深度集成,使模型输出不仅包含建议,还附带“物理仿真验证报告”——当GPT建议“调整机器人关节扭矩”时,系统会自动运行有限元分析,证明该调整不会导致机械臂变形。
“工业AI的未来不属于通用模型,而属于‘懂工业’的专用模型。”某工业软件企业CEO在2026年世界人工智能大会上指出,“我们需要的是能