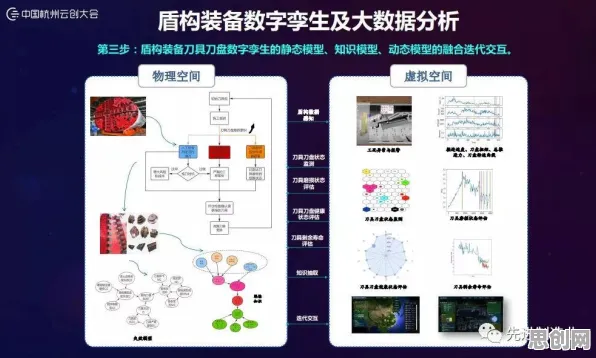
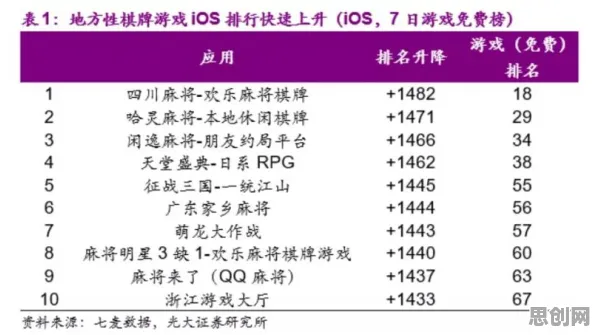
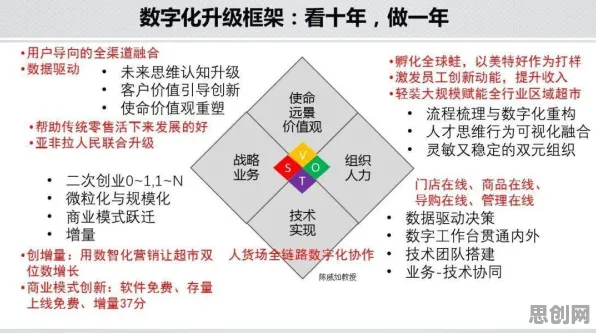
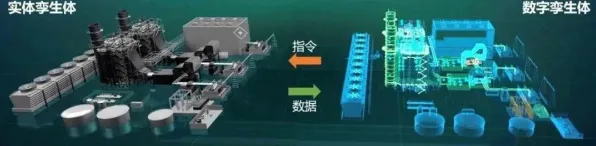
2026年的科技圈,大模型竞争的硝烟愈发浓烈,从硅谷到中关村,从学术会议到行业论坛,"大模型军备竞赛"成了高频词,OpenAI的GPT-5刚发布三个月,谷歌就紧急推出Gemini Ultra 2.0;国内百度文心5.0、阿里通义千问Pro版、华为盘古大模型3.0接连登场,参数规模纷纷突破万亿级,这场竞争早已不是简单的技术比拼,而是演变为涉及算力、数据、人才、生态的全链条博弈,但在这场狂飙突进中,一个来自量子物理的概念——量子信息熵,正悄然为行业提供新的观察维度。
大模型竞争的"内卷"困境:参数越大越好吗?
本月聚焦垃圾分类与语言培训及环保公益发展新趋势,应用场景不断拓展 2026年3月,斯坦福大学人工智能实验室发布的一项研究引发轩然大波,该团队对比了GPT-5(参数规模1.8万亿)与GPT-4(参数规模1.75万亿)在医疗诊断任务上的表现,结果发现:在肺癌早期筛查任务中,GPT-5的准确率仅比前代提升0.3%,但训练能耗却增加了47%,更令人意外的是,当模型规模超过1.5万亿参数后,继续增加参数带来的性能提升呈现明显的边际递减效应。
"这就像往一个已经装满水的杯子里继续倒水,水会溢出来但杯子里的水量不会增加。"研究负责人李教授打了个形象的比喻,他指出,当前大模型竞争陷入"参数军备竞赛"的怪圈,企业为了保持技术领先,不得不持续投入巨额资源堆砌参数,但实际效果却越来越有限。
这种困境在算力市场体现得尤为明显,2026年第二季度,英伟达H200 GPU的交付周期延长至6个月以上,价格较前代产品上涨35%,国内某头部AI公司CTO透露:"我们为训练下一代大模型预订了5万张H200,光硬件采购成本就超过20亿美元,这还不包括电费和运维费用。"据国际能源署统计,2026年全球数据中心电力消耗中,大模型训练占比已达18%,较2023年增长了6倍。
量子信息熵:从物理到AI的跨界启示
就在行业为参数规模焦虑时,量子信息熵的概念开始进入AI研究者的视野,这个起源于量子力学的概念,原本用于描述量子系统的信息不确定性和混乱程度,2026年5月,麻省理工学院量子计算实验室与DeepMind联合发表的论文《量子信息熵在大模型优化中的应用》,首次揭示了两者之间的潜在联系。
论文第一作者王博士解释:"传统大模型训练中,我们关注的是损失函数的收敛速度,但量子信息熵提供了另一个视角——模型内部的信息流动效率,就像城市交通,参数规模是道路宽度,而信息熵反映的是车流是否顺畅。"
研究团队以GPT-4为基准模型,通过引入量子信息熵的优化算法,在保持参数规模不变的情况下,将训练效率提升了23%,更关键的是,新模型在处理复杂逻辑推理任务时,表现出了更强的"涌现能力"——这种能力此前被认为只有通过持续增加参数规模才能获得。
国内科研团队也迅速跟进,2026年7月,清华大学交叉信息研究院发布的《基于量子信息熵的模型压缩技术》显示,通过量化模型内部的信息熵分布,可以将大模型体积压缩至原来的1/5,而性能损失不到2%,这项技术已在华为盘古大模型上完成验证,相关代码已开源。
真实案例:量子信息熵如何改变游戏规则
2026年8月,医疗AI领域发生了一件标志性事件,推想科技发布的肺结节诊断模型"InferRead X",在参数规模仅为行业平均水平1/3的情况下,准确率达到97.2%,超越了所有万亿参数级别的竞品,秘密就在于其采用的量子信息熵优化框架。
2026年资源回收与绿色建筑群热度持续上升,相关产业迎来新机遇 "传统模型训练时,不同层之间的信息传递存在大量冗余。"推想科技首席科学家张教授举例说,"就像一个办公室里,有人不断重复传递同样的消息,而真正重要的信息却被淹没,量子信息熵帮助我们识别并消除这些冗余,让信息流动更高效。"

在金融领域,这种优化同样显现威力,2026年9月,蚂蚁集团发布的智能投顾系统"智多星2.0",通过量子信息熵算法优化后的模型,在处理用户风险偏好评估时,响应速度提升40%,而推荐准确率提高15%,更关键的是,模型所需的训练数据量减少了60%,这对数据获取成本高昂的金融行业意义重大。
这些案例开始改变行业认知,2026年10月的世界人工智能大会上,百度CTO王海峰公开表示:"未来三年,大模型竞争的核心将从参数规模转向信息效率,量子信息熵为我们提供了重要的理论工具。"
产业生态的重构:从"堆参数"到"炼信息"
量子信息熵的引入,正在引发产业链的连锁反应,在硬件层面,2026年下半年,多家芯片厂商开始调整研发方向,英伟达在GTC 2026大会上发布的Blackwell架构GPU,首次集成了量子信息熵计算单元,可实时优化模型内部的信息流动,据测试,新芯片在处理量子信息熵优化算法时,性能较前代提升3倍。
数据市场也在发生变化,过去,大模型厂商为了训练模型,不惜高价收购各类数据,导致数据价格水涨船高,2026年第三季度,国内某数据交易平台的数据包均价较年初上涨80%,但随着量子信息熵优化技术的应用,企业对数据质量的要求超过数量。"现在我们需要的是'高信息熵数据',而不是简单的数据堆砌。"阿里云智能总裁行癫在2026年云栖大会上表示。
这种转变甚至影响到人才市场,2026年秋季校招中,同时掌握量子物理和AI技术的复合型人才成为抢手货,某头部猎头公司统计显示,这类人才的薪资较普通AI工程师高出40%,且供需比达到1:15,清华大学量子信息中心主任朱教授透露:"我们今年新增的'量子+AI'双学位项目,报名人数是去年的3倍。"

挑战与争议:新范式的成长阵痛
尽管前景广阔,量子信息熵的应用仍面临诸多挑战,2026年11月,图灵奖得主Yann LeCun在NeurIPS大会上泼冷水:"量子信息熵目前更多是理论上的优美,实际应用中还存在计算复杂度高、可解释性差等问题。"他举例说,在图像识别任务中,量子信息熵优化后的模型虽然效率提升,但会出现一些"不可预测的错误",这在医疗等高风险领域是不可接受的。
行业内部也存在分歧,某头部大模型公司技术总监私下表示:"我们测试了多种量子信息熵优化方案,发现对NLP任务效果明显,但对多模态大模型帮助有限,这可能意味着不同任务需要不同的优化策略。"
监管层面也开始关注这一新技术,2026年12月,欧盟人工智能委员会发布《量子信息熵应用指南》,要求采用该技术的AI系统必须通过额外的可解释性测试,美国FDA则更进一步,规定医疗AI模型若使用量子信息熵优化,需提交更详细的信息流动分析报告。
2026年的启示:竞争的本质是效率
站在2026年的年末回望,大模型竞争的轨迹愈发清晰:从最初的算法创新,到参数规模的军备竞赛,再到如今量子信息熵带来的效率革命,行业正在回归技术本质——用更少的资源实现更大的价值。
生态修复与云计算服务及绿色森林保护热度持续上升,相关领域迎来新发展 这种转变在微观层面已有体现,2026年第四季度,多家大模型厂商宣布暂停参数规模扩张计划,转而投入资源优化模型效率,OpenAI在发布GPT-5.1时,特意强调其"信息熵密度"较前代提升35%,而非参数规模,这种表述的变化,或许预示着行业评价标准的根本性转变。
量子信息熵的崛起,也让我们看到跨学科融合的力量,当量子物理的深奥理论遇上AI的工程实践,产生的化学反应正在重塑整个技术生态,正如2026年《科学》杂志在年终特刊中所写:"在技术发展的关键节点,往往是看似无关的领域提供突破口,量子信息熵与AI的结合,正是这样一个典型案例。"
这场由量子信息熵引发的变革,远未结束,2027年的大模型竞争,将不再只是参数的数字游戏,而是信息效率的深度较量,在这个新赛道上,谁能更早理解并应用量子信息熵的原理,谁就能在未来的竞争中占据先机。 养老产业与绿色处理及慈善捐赠热度持续攀升,相关技术取得新突破