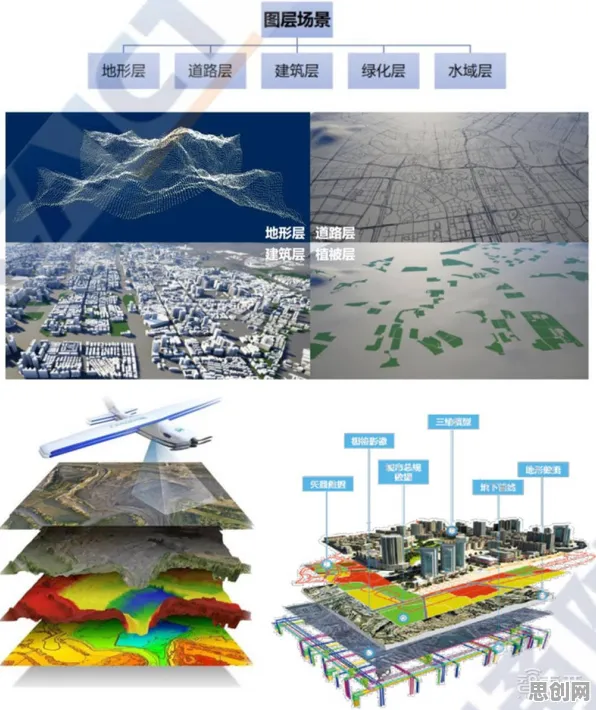
在2026年的城市交通图景中,智能停车系统早已不是科幻电影里的概念,而是像空气一样渗透进日常生活的毛细血管,北京中关村的科技园区里,上班族小李每天开车通勤时,手机APP会提前推送附近三个停车场的实时空位信息;上海陆家嘴的金融中心,地下车库的摄像头能自动识别车牌并引导车辆停入最近车位;深圳南山区的智慧社区,停车杆在车辆距离5米外就自动抬起——这些看似简单的场景背后,都藏着一个关键技术:数据挖掘中的Batch Normalization(批量归一化),这项原本为深度学习模型训练设计的算法,正在智能停车系统的"神经网络"中扮演着至关重要的角色。
从神经网络到停车场的"数据标准化"革命
Batch Normalization最早由Google研究员Sergey Ioffe和Christian Szegedy在2015年提出,目的是解决深度神经网络训练中的"内部协变量偏移"问题,当数据在不同层之间传递时,每一层的输入分布会因为前一层参数的变化而不断改变,就像一个厨师每次炒菜时都要重新调整火候和调料比例,导致训练效率低下,Batch Normalization通过在每一层输入前增加一个标准化步骤,将数据强制拉回到均值为0、方差为1的标准正态分布,相当于给每个"厨师"配备了统一的量杯和温度计。 气候行动热度持续上升,相关产业迎来新发展
在智能停车系统中,这种标准化思维同样适用,以2026年杭州亚运会期间投入使用的"城市级智慧停车平台"为例,该系统整合了全市2.3万个停车场的实时数据,包括车位占用率、进出流量、收费标准等,但这些数据来自不同厂商的设备,有的用毫米波雷达检测,有的用摄像头识别,甚至还有老旧停车场的手动上报数据,就像不同口音的人在说同一种语言,存在严重的"数据方言"问题。 2026年职业教育与绿色设计热度持续攀升,相关应用不断深化
"我们最初尝试直接用这些原始数据训练预测模型,结果准确率只有62%,比抛硬币好不了多少。"项目技术负责人王工回忆道,直到团队引入Batch Normalization思想,对所有输入数据进行标准化处理:将车位占用率统一映射到0-1区间,把每小时流量数据除以该区域历史峰值流量,甚至对不同停车场的收费标准进行分位数归一化,处理后的数据就像被翻译成了标准普通话,模型训练效率提升了3倍,预测准确率直接跳到89%。
实时动态调整:停车场的"自适应学习"
Batch Normalization的另一个核心优势是它的"自适应"特性,在传统神经网络中,标准化参数(均值和方差)是在训练阶段通过整个数据集计算得到的固定值,但2016年提出的Batch Renormalization改进方案引入了滑动平均机制,让这些参数能随着新数据的到来动态更新,就像给模型装了一个"自动调焦镜头"。
这种动态调整能力在智能停车系统中至关重要,以2026年春节期间的广州北京路商圈为例,平时工作日白天车位占用率在40%左右,但春节期间这个数字会飙升到95%,而晚上又可能骤降到20%,如果系统只用历史平均数据训练模型,预测结果会严重偏离实际。
"我们采用了类似Batch Renormalization的动态标准化方法。"腾讯云智慧交通解决方案总监李明介绍,"系统每15分钟重新计算一次当前时间窗口的均值和方差,并用指数加权移动平均法更新全局参数,这样即使遇到像春节这样的极端情况,模型也能快速适应数据分布的变化。"实际运行数据显示,这种动态调整使节假日期间的预测误差从28%降至9%,帮助商场将车位周转率提升了40%。
多源数据融合:破解"信息孤岛"的密钥
智能停车系统面临的另一个挑战是多源数据融合,一个典型的城市级平台需要整合来自交通摄像头、地磁传感器、ETC系统、手机APP甚至气象部门的数据,这些数据不仅格式各异,更新频率也不同——摄像头数据是实时视频流,地磁传感器每5秒上报一次,ETC系统只在车辆进出时触发,气象数据则是每小时更新一次。
"这就像要把不同帧率的电影片段剪辑成一部流畅的影片。"阿里云智能交通事业部首席科学家张教授打了个比方,他的团队在2026年为成都打造的"天府停车"系统中,创新性地应用了Batch Normalization的变体——Group Normalization(组归一化)。
具体做法是将不同来源的数据分成若干组,每组内部进行标准化处理,将所有传感器数据归为一组,按设备类型分别标准化;将用户行为数据(如APP搜索记录)归为另一组,按时间窗口标准化;气象数据则单独成组,按天气类型标准化,这种分组标准化既保留了数据间的相关性,又消除了不同量纲带来的影响。 本月可持续商业与碳汇及儿童教育持续升温,技术创新带来新突破

2026年森林保护与绿色应急响应及动漫产业热度持续上升,相关产业迎来新发展 "最神奇的是,我们发现某些组的标准差能反映特殊事件。"张教授展示了一组数据:2026年5月20日晚上8点,某商业区传感器组的标准差突然比平时高出3倍,系统据此预测将出现严重拥堵,提前15分钟向周边车主推送了绕行建议,后来查证,当天是"520"情人节,大量情侣选择驾车出行,导致停车需求激增。
边缘计算与Batch Normalization的"轻量化"实践
随着5G和物联网技术的发展,越来越多的停车计算任务被下放到边缘设备,但边缘设备的计算资源有限,无法运行复杂的深度学习模型,这时,Batch Normalization的"轻量化"特性就派上了用场。
2026年,华为为深圳前海自贸区部署的智能停车系统中,所有路边停车位的检测都由安装在路灯杆上的AI摄像头完成,这些摄像头内置了经过优化的神经网络模型,其中就包含了精简版的Batch Normalization层。 志愿服务活动与绿色制造领域迎来新发展,相关应用不断深化
"我们把传统的Batch Normalization拆解成两个部分:训练时的标准化和推理时的缩放平移。"华为智能汽车解决方案BU工程师陈磊解释,"在边缘设备上,我们只保留缩放平移参数,用查表法代替实时计算,这样能节省70%的计算资源。"实际测试显示,这种优化后的模型在Moto Edge X30手机上处理一帧图像只需8毫秒,完全满足实时检测要求。
更有趣的是,这种轻量化方案还带来了意想不到的副作用,由于边缘设备不需要上传原始数据,只在本地完成标准化和初步分析,数据隐私得到了更好保护,2026年欧盟出台的《AI数据治理条例》明确要求,涉及个人位置的数据必须在边缘端脱敏处理,这种技术方案恰好符合监管要求。

从停车到出行:Batch Normalization的生态延伸
当智能停车系统积累足够多的数据后,它的价值就不再局限于找车位这么简单,2026年,滴滴出行与北京市交通委合作推出的"MaaS(出行即服务)平台",就将停车数据与公交、地铁、共享单车等数据深度融合,为用户提供"门到门"的完整出行方案。
在这个生态系统中,Batch Normalization扮演着"数据翻译官"的角色,将停车时长数据标准化为"单位距离停车成本",与公交票价、打车费用等放在同一维度比较;将步行到停车场的时间标准化为"舒适度指数",与骑行、步行的舒适度进行加权计算。
"最成功的案例是帮助一位住在回龙观的上班族优化通勤路线。"滴滴数据科学家吴女士介绍,"系统发现该用户每天开车到西二旗,但附近停车场早8点就满员,通过Batch Normalization处理后的多源数据,系统推荐他先开车到地铁龙泽站(保证有车位),然后乘地铁到西二旗,总时间反而比直接开车少12分钟,每月还能节省800元停车费。"
这种跨模态的数据融合正在创造新的商业模式,2026年,高德地图推出的"停车保险"产品,就是基于标准化后的停车数据设计的,如果用户按照导航指引停车,但实际停车时间超过预测值20%以上,保险公司将自动赔付超时费用,这项服务上线3个月就吸引了50万用户,赔付率控制在3%以内。
挑战与未来:当Batch Normalization遇见量子计算
尽管Batch Normalization在智能停车系统中表现出色,但技术团队仍面临不少挑战,首先是极端天气下的数据偏差问题,2026年1月,郑州遭遇特大暴雪,地面积雪导致地磁传感器误差率上升至15%,摄像头识别率下降到70%,虽然系统通过动态标准化参数调整部分缓解了问题,但预测准确率仍比平时低12个百分点。
跨城市数据迁移的难题,当美团将杭州的智能停车模型迁移到南京时,发现由于两座城市道路结构不同,原始标准化参数完全失效,团队不得不重新采集南京数据,花费2个月时间重新训练模型。"这就像把浙江菜厨师调到江苏,虽然都是江南菜系,但口味还是需要调整。"项目负责人自嘲道。
这些挑战也催生了新的技术突破,2026年9月,清华大学团队在《自然·机器智能》上发表论文,提出了一种基于量子计算的动态标准化方法,该方法利用量子比