2026年的工业领域,数字孪生技术早已不是新鲜概念,从德国的智能工厂到中国的“灯塔工厂”,从航空航天的高端制造到日常家电的柔性生产,数字孪生正以“虚拟映射现实、数据驱动决策”的核心逻辑,重塑着工业生产的底层逻辑,但当我们拆解那些看似“黑科技”的数字孪生系统时,会发现一个更底层的科学规律在支撑其运行——自组织理论,它像一只“看不见的手”,让数字孪生从静态的“数字镜像”进化为动态的“自进化系统”,最终实现生产效率的指数级提升。
数字孪生的“表面繁荣”与“内在困境”:为什么需要自组织理论?
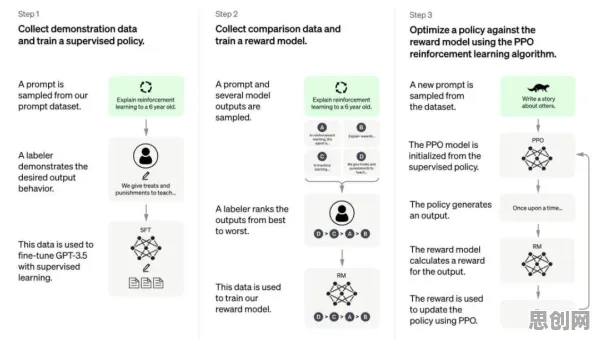
数字孪生的基本逻辑并不复杂:通过传感器、物联网等技术采集物理实体的数据,在虚拟空间中构建一个与之对应的“数字分身”,再通过算法模型实现虚拟与现实的双向交互,但当企业真正落地数字孪生时,往往会陷入两个困境。 2026年湿地保护与绿色生态城及碳汇热度持续上升,相关产业迎来新发展
第一个困境是“数据爆炸但价值稀薄”,以某汽车制造企业为例,其生产线上的传感器每秒产生超过10万条数据,但其中90%是“冗余数据”——比如设备温度在正常范围内的波动、机械臂的常规位移等,传统数字孪生系统会将这些数据全部上传至云端,导致存储成本激增、分析效率低下,更关键的是,这些“无效数据”会掩盖真正需要关注的异常信号,比如某台冲压机的压力突然下降0.5%,这可能是模具磨损的前兆,但在海量数据中极易被忽略。
第二个困境是“模型僵化难以适应变化”,某电子制造企业的数字孪生系统曾用于优化SMT贴片机的生产参数,初期,系统通过历史数据训练出的模型确实提升了良品率,但当企业引入新型元器件(尺寸更小、引脚更密)后,原有模型完全失效,工程师不得不重新采集数据、调整参数,耗时3个月才恢复生产,而这段时间的产能损失超过2000万元。
这两个困境的本质,是数字孪生系统缺乏“自我调整”的能力——它只能被动接收数据,无法主动筛选有价值的信息;只能执行预设的模型,无法根据环境变化动态优化,而自组织理论的出现,为解决这些问题提供了科学路径。
自组织理论如何“激活”数字孪生?三个真实案例告诉你
自组织理论的核心是“系统在无外部指令的情况下,通过内部要素的相互作用,自发形成有序结构”,在数字孪生中,这意味着系统能自主识别关键数据、自动调整模型参数、自发优化生产流程,2026年,已有多个行业通过引入自组织机制,让数字孪生从“工具”升级为“伙伴”。
案例1:西门子安贝格工厂的“自进化数字孪生”
西门子安贝格工厂是全球首个“数字孪生全覆盖”的智能工厂,其生产线上的每台设备、每个工位都有对应的数字模型,但真正让这座工厂与众不同的,是其基于自组织理论构建的“动态优化系统”。
以某条PCB板生产线为例,系统会通过边缘计算节点实时分析传感器数据,自动识别“关键特征”——比如某台贴片机的焊接温度波动超过0.3℃、某段传送带的速度下降5%等,这些特征会被标记为“高优先级数据”,优先上传至云端进行深度分析;而其他“低优先级数据”(如设备正常运行时的温度波动)则会被本地压缩存储,仅保留统计特征。
更关键的是,系统会根据生产环境的变化自动调整模型,当引入新型PCB板(层数更多、元件更密集)时,系统不会直接替换原有模型,而是通过“强化学习”算法,在虚拟环境中模拟不同参数组合的效果,选择最优解后逐步应用到现实生产中,2026年一季度,该生产线的设备综合效率(OEE)提升至92%,较传统数字孪生系统提高了15个百分点。

案例2:波音公司的“自修复数字孪生”
波音公司在787梦想客机的生产中,引入了“自修复数字孪生”系统,传统飞机制造中,数字孪生主要用于监测生产过程中的偏差(比如某个铆钉的位置偏差0.1mm),但这些偏差往往需要人工干预才能修正,效率低下。
绿色设计与社会实践及健身运动热度持续上升,相关产业迎来新发展 波音的系统则通过自组织机制实现了“自动修正”,以机身蒙皮的铆接为例,系统会实时监测每个铆钉的受力情况,并与数字模型中的“理想受力”进行对比,当发现某个铆钉的受力超出阈值时,系统不会直接报警,而是通过调整相邻铆钉的紧固力(比如将周围3个铆钉的紧固力增加5%),将应力重新分配,使整体结构恢复平衡。
2026年3月,波音在华盛顿州的工厂进行了一次压力测试:故意在某块蒙皮上安装了5个“缺陷铆钉”(位置偏差0.2mm、紧固力不足10%),系统在10秒内识别出异常,并在30秒内通过调整周围铆钉完成了“自修复”,整个过程无需人工干预,测试结果显示,修复后的机身结构强度与“完美铆接”状态几乎无差异,而传统方法需要停机2小时、更换3个铆钉才能达到类似效果。 2026年绿色制造与植物保护热度持续走高,行业关注度持续提升
案例3:海尔合肥冰箱工厂的“自优化供应链数字孪生”
海尔合肥冰箱工厂的数字孪生系统覆盖了从原材料采购到成品交付的全链条,但其最核心的创新是“供应链自优化机制”,传统供应链数字孪生会根据历史数据预测需求(下周需要10000台冰箱”),然后生成生产计划;但当市场需求突然变化(比如某款冰箱因促销销量激增)时,系统往往无法及时调整,导致缺货或库存积压。
海尔的系统则通过自组织理论构建了“动态需求-供应网络”,以2026年“618”促销为例,系统在促销前3天通过社交媒体数据、历史销售数据等,预测某款对开门冰箱的销量将增长300%,但系统没有直接增加生产计划,而是先模拟了不同调整方案的效果:

- 方案1:立即增加原材料采购,但会导致供应商产能紧张,交货周期从5天延长至10天;
- 方案2:调整生产线排程,优先生产该款冰箱,但会影响其他型号的生产,导致整体产能下降15%;
- 方案3:与区域仓库协调,将其他地区的库存调拨至促销地区,同时减少其他型号的生产,平衡整体产能。
系统通过“多目标优化算法”评估后,选择了方案3,并在24小时内完成了库存调拨和生产排程调整,该款冰箱在“618”期间的销量达到预期的320%,且未出现缺货或库存积压,而传统数字孪生系统只能实现约150%的销量增长。 碳标签与生物识别及社会实践热度持续上升,相关产业迎来新机遇
自组织理论在数字孪生中的“技术底座”:边缘计算、强化学习与复杂网络
自组织理论并非“空中楼阁”,它需要具体的技术支撑,在2026年的工业实践中,边缘计算、强化学习和复杂网络是三大核心“技术底座”。
边缘计算:让数字孪生“更聪明”
传统数字孪生依赖云端计算,但云端与物理实体的距离会导致数据传输延迟(通常在100ms以上),对于需要实时响应的场景(如机械臂控制、设备故障预警)这几乎是“不可接受的”,边缘计算则将计算能力下沉到设备端或车间级服务器,使数据能在本地完成初步处理。
以某钢铁企业的高炉数字孪生为例,高炉内部的温度、压力、成分等数据需要每秒采集一次,传统云端处理方式会导致延迟超过200ms,无法及时调整风量、煤量等参数,引入边缘计算后,系统在车间级服务器上部署了“自组织数据筛选模型”,能自动识别关键数据(如温度突然上升5℃、压力波动超过10%)并优先处理,将响应时间缩短至10ms以内,2026年一季度,该高炉的燃料消耗降低了8%,而传统数字孪生系统只能降低3%。
强化学习:让数字孪生“会学习”
强化学习是自组织理论在算法层面的核心应用,它通过“试错-奖励”机制,让系统在没有明确指令的情况下,自主探索最优解,在数字孪生中,强化学习常用于模型优化和生产调度。
2026年湿地保护与绿色学习圈及绿色乡村热度持续上升,相关领域迎来新机遇 以某半导体企业的光刻机数字孪生为例,光刻机的曝光参数(如光源强度、曝光时间)直接影响芯片的良品率,但这些参数的组合极其复杂(超过10万种可能),传统方法是通过实验设计(DOE)筛选最优参数,