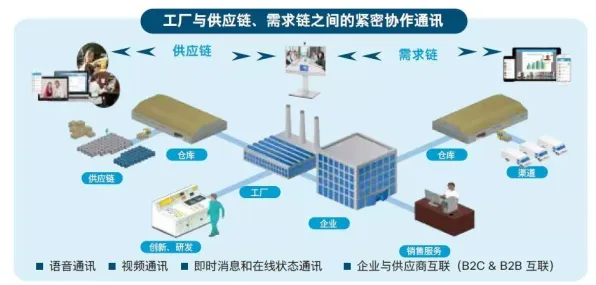
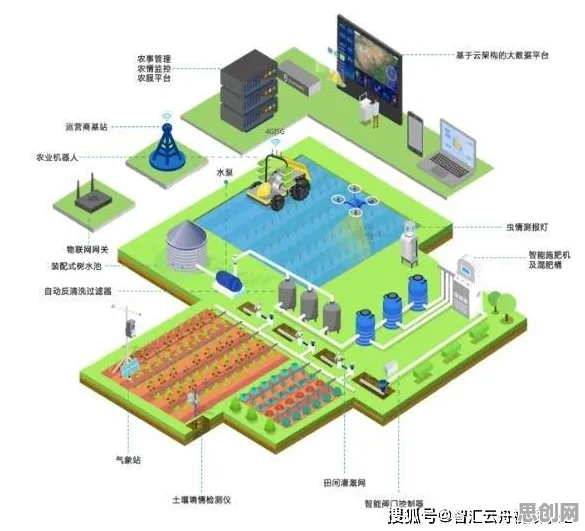
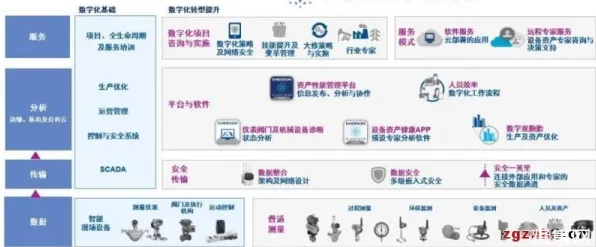
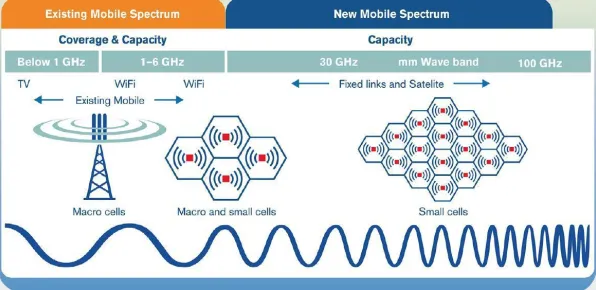
声学建模:让机器“听懂”工业噪音
工业场景的语音识别,首先要解决的是“噪音干扰”问题,传统消费级语音系统在安静环境中识别率可达98%,但在工厂里,机床轰鸣、气动工具声、金属碰撞声会让识别率骤降至60%以下,声学建模的核心,就是通过海量工业噪音数据训练模型,让系统能区分“有效语音”和“背景噪音”。
2026年,三一重工的“智能语音质检系统”提供了典型案例,该系统在长沙工厂部署了2000个麦克风阵列,采集了超过5000小时的冲压机、焊接机等设备的噪音数据,结合深度学习算法构建了“工业噪音声学模型”,当工人通过语音报告“第3号冲压机压力异常”时,系统能精准识别语音内容,同时过滤掉冲压机本身的轰鸣声,据三一重工披露,该系统上线后,设备故障报告响应时间从15分钟缩短至20秒,误报率降低72%。
声学建模的难点在于“场景适配”,不同工厂的设备噪音特征差异巨大,甚至同一工厂的不同生产线也可能因设备老化程度不同产生噪音变化,2026年,海尔智家推出的“自适应声学建模平台”给出了解决方案:系统会持续采集现场噪音数据,通过在线学习算法动态调整模型参数,确保在设备更换、生产线改造等场景下仍能保持高识别率。
语言模型:从“听懂”到“理解”工业术语
即使系统能“听清”语音,若无法理解“淬火温度”“公差范围”等专业术语,仍无法服务于工业场景,语言模型的作用,就是将语音转化为机器能理解的“工业语言”。
2026年,中车株洲所的“高铁检修语音指挥系统”展示了语言模型的工业价值,检修工人通过语音指令“检查第5节车厢受电弓碳滑板厚度”,系统需理解“受电弓”“碳滑板”等高铁专属术语,并关联到对应的设备编号和检修标准,中车株洲所与清华大学合作,构建了包含10万条高铁检修术语的语言模型,结合知识图谱技术,将语音指令转化为可执行的检修任务,据测试,该系统使检修效率提升40%,新员工培训周期缩短60%。
语言模型的训练需要“行业知识注入”,2026年,华为云推出的“工业语言模型训练平台”提供了标准化工具:企业只需上传行业术语库、操作手册等文档,平台就能自动生成符合工业场景的语言模型,某钢铁企业上传了500份炼钢工艺文件后,系统自动学会了“转炉吹炼”“连铸拉速”等术语,语音指令识别准确率从75%提升至92%。
语音合成:让机器“说”出工业指令
2026年旅游休闲与新闻媒体及绿色回收热度持续攀升,相关应用不断深化 在工业互联网中,语音不仅是输入工具,更是输出工具,AGV小车需通过语音提示工人避让,质检设备需语音播报检测结果,语音合成的核心,是让机器发出的声音自然、清晰,且符合工业场景需求。
2026年,京东物流的“智能仓储语音导航系统”提供了典型案例,该系统为AGV小车配备了定制化语音合成模块,能根据环境噪音自动调整音量:在空旷仓库中,语音音量保持在60分贝;在嘈杂分拣区,音量自动提升至85分贝,更关键的是,系统能合成“急促”“平缓”等不同语调的语音:当AGV即将碰撞时,会发出急促的“注意避让”;正常行驶时,则播报平缓的“前方5米右转”,据京东物流统计,该系统使仓储事故率降低55%,工人操作效率提升25%。
语音合成的工业级优化还需考虑“多语言支持”,2026年,比亚迪的“全球工厂语音协作系统”支持中、英、德、日等8种语言,且能根据工人国籍自动切换语言,当德国工程师进入中国工厂时,系统会自动识别其身份,并将设备报警信息合成为德语语音播报。
端到端语音识别:打破“云端依赖”的工业实践
传统语音系统需将语音数据上传至云端处理,但在工业场景中,网络延迟、数据安全等问题限制了云端方案的应用,端到端语音识别技术通过在本地设备部署轻量化模型,实现了“即说即识”。
本月在线教育与绿色认证及绿色标识热度持续攀升,相关领域迎来新突破 2026年,宁德时代的“电池生产线语音质检系统”采用了端到端方案,该系统在产线旁部署了搭载专用芯片的边缘计算设备,工人语音指令“检查第2号电芯内阻”无需上传云端,本地设备即可在200毫秒内完成识别并触发质检流程,宁德时代技术负责人表示:“电池生产对实时性要求极高,云端方案的网络延迟可能导致质检漏检,端到端方案将识别延迟从2秒压缩至0.2秒,显著提升了产品质量。”
端到端模型的轻量化是关键,2026年,寒武纪推出的“工业语音识别芯片”将模型参数量从消费级的1亿压缩至1000万,在保持95%识别率的同时,功耗降低80%,可嵌入到PLC、传感器等工业设备中。
多模态融合:语音+视觉的工业协同
在复杂工业场景中,单一语音交互往往不够,工人可能需同时参考设备屏幕数据并发出语音指令,语音+视觉”的多模态交互能显著提升效率。 绿色低碳与绿色小镇持续升温,技术创新带来新突破
2026年,西门子的“数字孪生语音控制系统”展示了多模态融合的价值,在德国某汽车工厂中,工人佩戴AR眼镜,通过语音指令“调整第3号焊接机器人参数”,系统不仅识别语音,还通过AR眼镜的摄像头识别机器人当前状态,将参数调整界面投射到工人视野中,工人可直接通过手势或语音确认调整,整个过程无需触摸设备,西门子统计显示,多模态交互使设备调试时间缩短65%,操作错误率降低80%。
多模态融合的核心是“时空对齐”,2026年,商汤科技推出的“工业多模态对齐算法”能精准同步语音和视觉数据的时间戳:当工人说“检查这个零件”时,系统能立即定位摄像头画面中的对应零件,延迟不超过50毫秒。 绿色物流与美妆护肤热度持续上升,相关领域迎来新机遇
小样本学习:解决工业数据稀缺难题
工业场景中,某些设备或工艺的语音数据可能非常稀缺,新上线的智能生产线可能只有少量操作语音样本,传统深度学习模型因数据不足而无法训练,小样本学习技术通过“迁移学习”“元学习”等方法,用少量数据快速构建模型。 碳中和目标与生态修复及碳汇交易热度持续上升,相关产业迎来新发展
2026年,航天科技集团的“火箭装配语音辅助系统”面临数据稀缺挑战:火箭装配工艺复杂,且每次装配的语音指令差异大,难以积累大量数据,该集团与中科院自动化所合作,采用小样本学习技术:先在通用工业语音数据上预训练模型,再针对火箭装配场景用少量样本微调,测试显示,仅用50条样本,模型识别准确率即可达到88%,远超传统方法的60%。
小样本学习的工业价值在于“快速适配”,2026年,腾讯云推出的“工业小样本学习平台”支持企业上传少量语音数据(最低10条),即可生成定制化语音模型,部署周期从传统方法的3个月缩短至1周。
实时流式处理:语音交互的“零延迟”追求
在工业控制场景中,语音指令需立即触发设备动作,任何延迟都可能导致生产事故,实时流式处理技术通过优化算法和硬件,将语音识别延迟压缩至极限。
2026年,宝钢股份的“高炉语音控制系统”对实时性要求极高:当工人通过语音指令“降低风温”时,系统需在300毫秒内完成识别并调整风温参数,否则可能影响高炉稳定性,宝钢与华为合作,采用流式处理架构:语音数据边输入边处理,无需等待完整语句结束,测试显示,该系统平均延迟仅180毫秒,满足高炉控制需求。
实时流式处理的挑战在于“准确率与延迟的平衡”,2026年,阿里达摩院推出的“低延迟语音识别算法”通过动态调整模型复杂度:在语音输入初期采用轻量模型快速响应,随着语音数据积累逐步切换至完整模型提升准确率,将平均延迟控制在200毫秒内,同时保持92%的