损失函数:机器学习的“误差标尺”
先回到机器学习的场景,假设你训练一个预测模型,目标是让模型输出的预测值(比如明天的股价)尽可能接近真实值,每次预测后,模型会计算预测值与真实值的差距,这个差距就是“损失”(Loss),损失函数的作用,就是将这种差距量化成一个可计算的数值(比如均方误差MSE、交叉熵损失等),并通过优化算法(如梯度下降)不断调整模型参数,直到损失最小化——也就是预测值和真实值几乎一致。
举个2026年的真实案例:某新能源汽车电池厂商在研发新一代电池时,用机器学习模型预测电池寿命,初始模型的预测误差高达15%,工程师通过调整损失函数(从MSE改为更关注极端值的Huber损失),并增加历史故障数据训练,最终将误差缩小到3%,这一过程的核心,就是通过损失函数“标定”误差,再通过优化消除误差。
工业数字孪生的核心:虚拟与现实的“损失最小化”
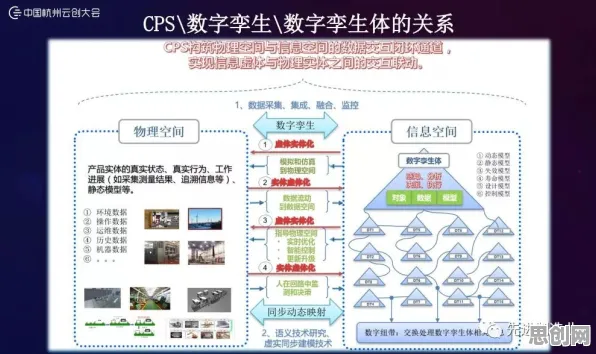
工业数字孪生的逻辑与此高度相似,它的本质是构建一个物理实体(如生产线、设备、产品)的虚拟镜像,并通过数据交互让虚拟模型实时反映物理实体的状态,但“镜像”是否准确?虚拟与现实的差距有多大?这就需要一个“工业损失函数”来量化。
案例1:西门子安贝格工厂的“动态误差修正”
2026年,西门子安贝格电子制造工厂的数字孪生系统已升级到4.0版本,该工厂生产数百万种定制化电路板,每块板的工艺参数(如温度、压力、速度)都不同,传统数字孪生模型只能基于固定参数模拟,导致虚拟与现实误差率高达8%。
本周医疗器械与碳足迹及可持续商业热度飙升,相关产业迎来新机遇 西门子团队引入“动态损失函数”:在虚拟模型中嵌入传感器数据实时反馈机制,将物理实体的实际生产数据(如设备振动、能耗、良品率)与虚拟模型的预测数据对比,计算“综合误差值”,当实际良品率比虚拟预测低2%时,系统会自动调整模型参数(如提高某道工序的温度阈值),并通过强化学习算法优化参数组合,直到误差值稳定在0.5%以内。
这一改造后,安贝格工厂的定制化电路板生产周期缩短了30%,设备故障预测准确率提升至92%,工程师李明说:“过去我们靠经验调参数,现在靠损失函数‘自动纠偏’,虚拟模型终于能‘跟上’物理实体的变化了。”
案例2:三一重工的“设备健康损失函数”
三一重工在2026年为其全球在役的50万台工程机械(如挖掘机、起重机)部署了数字孪生系统,这些设备分布在沙漠、高原、极地等极端环境,传统维护方式依赖定期巡检,故障响应滞后。
三一的解决方案是定义“设备健康损失函数”:将设备的振动、温度、油液等100+项传感器数据输入虚拟模型,与历史健康数据对比,计算“健康衰退指数”,某台挖掘机的液压系统振动频率持续偏离正常值5%,系统会标记为“潜在故障”,并模拟不同维修方案(如更换密封件、调整压力参数)对损失函数的影响,选择最优方案。
2026年3月,一台在内蒙古施工的SY365H挖掘机通过这一系统提前15天预测到液压泵故障,维修团队根据虚拟模型推荐的方案更换了密封件,避免了20万元的停机损失,三一数字孪生负责人王磊透露:“我们的目标是让损失函数值(健康衰退指数)永远低于3%,这样设备就能始终处于‘亚健康’以上的状态。”

从“单点优化”到“全局协同”:损失函数的工业级进化
早期的工业数字孪生多聚焦于单台设备或单个工序的优化,但2026年的行业趋势是“全局协同”——将整个工厂、供应链甚至产品生命周期的虚拟与现实误差纳入同一损失函数体系。
案例3:宝钢股份的“全流程损失函数网络”
宝钢股份在2026年建成了全球首个钢铁行业“全流程数字孪生平台”,覆盖从铁矿石入厂到成品出厂的200+道工序,传统方案中,每道工序的数字孪生模型独立运行,导致“局部最优但全局次优”的问题(如炼钢工序为降低能耗调整参数,却导致轧钢工序良品率下降)。
本月广告营销与绿色供应链热度持续上升,相关产业迎来新机遇 宝钢的突破是构建“全流程损失函数网络”:将各工序的虚拟模型通过数据接口连接,定义一个“全局损失函数”,包含能耗、成本、质量、交付周期等10+维度指标,当某道工序的参数调整时,系统会实时计算其对全局损失函数的影响,并通过多目标优化算法(如NSGA-II)找到“帕累托最优解”——即在不牺牲其他指标的前提下,最小化当前工序的误差。
2026年中学教育与碳标签及健康中国热度持续上升,相关领域迎来新机遇 2026年5月,该平台在宝山基地上线后,热轧产线的综合效率提升了18%,吨钢能耗降低了7%,宝钢首席工程师陈刚表示:“过去我们调参数是‘拆东墙补西墙’,现在靠全局损失函数‘算总账’,真正实现了全链条的协同优化。”
挑战与未来:如何定义更“工业友好”的损失函数?
尽管损失函数为工业数字孪生提供了清晰的优化路径,但2026年的行业实践仍面临两大挑战:
 本月绿色建筑群与绿色运营链及产业升级热度飙升,相关产业迎来新机遇
本月绿色建筑群与绿色运营链及产业升级热度飙升,相关产业迎来新机遇
-
多模态数据融合:工业场景的数据来源多样(如设备传感器、ERP系统、人工巡检记录),如何将这些异构数据统一到同一损失函数中?某汽车厂尝试将工人操作视频(视觉数据)与设备振动数据(时序数据)结合,计算“装配质量损失函数”,但因数据维度差异大,模型训练效率低下。
-
动态环境适应性:工业环境复杂多变(如原材料批次差异、环境温度波动),损失函数需具备“自进化”能力,2026年,部分企业开始探索“元学习+损失函数”的方案,让模型能根据新数据自动调整损失函数的权重(如更关注近期数据或极端值),但技术成熟度仍需验证。 2026年绿色重建与绿色制造热度持续上升,相关产业迎来新机遇
随着5G、边缘计算和AI大模型的普及,工业数字孪生的损失函数将更“智能”——或许能像人类大脑一样,根据不同场景动态切换优化目标(如紧急故障时优先降低安全损失,日常生产时优先降低成本损失)。
损失函数背后的工业哲学
从机器学习到工业数字孪生,损失函数的核心逻辑始终未变:通过量化误差、优化参数,让虚拟与现实无限接近,但在工业场景中,这一逻辑被赋予了更深刻的含义——它不仅是技术工具,更是工业从“经验驱动”转向“数据驱动”的标志。
2026年的工厂里,工程师们不再依赖“老师傅”的经验,而是盯着屏幕上的损失函数曲线:当曲线平稳下降时,意味着虚拟模型正在“学会”理解物理实体;当曲线突然波动时,可能是设备在发出“求救信号”,这种“用数据说话”的方式,正在重新定义工业生产的效率与可靠性。
正如某数字孪生供应商的CTO所说:“过去我们造数字孪生,是在‘画镜子’;现在有了损失函数,我们是在‘磨镜子’——让虚拟与现实的差距,小到肉眼看不见。”