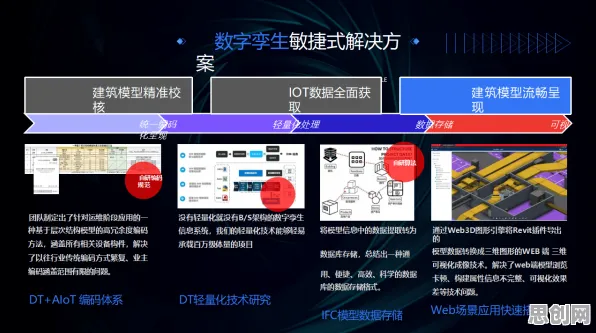
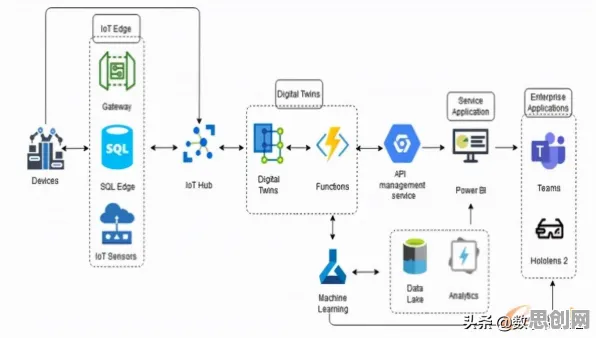
在2026年的工业领域,"数字孪生"早已不是新鲜词,但当企业真正落地应用时,仍会面临一个核心问题:为什么需要基于数据挖掘的数字孪生平台?这个问题的答案,藏在工业数据爆炸式增长与生产系统复杂性提升的双重背景下,从理论层面拆解,数据挖掘不仅是数字孪生的"大脑",更是连接物理世界与虚拟世界的"翻译官"。
工业数据的"沉默成本":从海量到价值的鸿沟
2026年,全球工业传感器数量已突破500亿个,中国某汽车制造企业的单条生产线每天产生的数据量超过20TB,这些数据包含设备振动、温度、压力、能耗等上千个维度,但90%以上的企业仍停留在"数据采集-存储-简单报表"的初级阶段,某钢铁集团曾投入巨资建设5G专网,却因缺乏数据挖掘能力,导致采集的炼钢过程数据长期闲置,直到引入数字孪生平台后,才通过关联分析发现转炉吹炼时间与能耗的隐性关系,单炉次成本降低1.2%。
数据挖掘的理论基础在于"数据-信息-知识-智慧"的转化链条,工业场景中,设备故障预测、工艺参数优化、供应链协同等决策,都需要从原始数据中提取特征模式,某风电企业通过挖掘风机振动数据的时频特征,结合SCADA系统中的风速、功率数据,构建了故障预警模型,将齿轮箱故障识别时间从72小时缩短至8小时,避免了单次百万级的维修损失,这种转化不是简单的统计计算,而是需要机器学习算法对非线性、高维、时变的数据进行深度解析。
数字孪生的"双生困境":物理模型与数据驱动的博弈
传统数字孪生建设存在两条路径:一是基于第一性原理构建物理模型,二是完全依赖数据驱动,前者在复杂系统(如半导体制造)中面临建模难度大、更新周期长的问题;后者则容易陷入"黑箱"困境,缺乏可解释性,2026年,行业逐渐形成共识:真正的数字孪生需要"物理模型+数据挖掘"的混合架构。
某航空发动机企业提供了典型案例,其数字孪生平台同时集成了热力学仿真模型和基于运行数据的健康评估模型,当发动机在高原环境运行时,物理模型可预测性能衰减趋势,而数据挖掘模型通过分析历史维修记录和实时传感器数据,能精准定位涡轮叶片的裂纹风险,这种"双模型"协同使维修计划制定效率提升40%,同时将非计划停机率降低至0.3%以下。

从理论视角看,这种混合架构解决了"模型漂移"问题,物理模型在长期运行中会因材料老化、环境变化产生偏差,而数据挖掘模型可通过实时数据反馈持续修正参数,某化工企业通过在数字孪生中嵌入强化学习算法,让系统自动调整反应釜温度控制策略,使产品合格率从92%提升至97%,同时减少15%的原料浪费。
数据挖掘的"工业语法":从关联到因果的突破
工业场景的数据挖掘面临独特挑战:设备故障、质量缺陷等事件往往是多因素耦合的结果,简单的相关性分析容易得出误导性结论,2026年,行业开始探索"因果推断"在数字孪生中的应用,这标志着数据挖掘从"描述现象"向"解释机制"的跨越。 2026年在线教育与绿色草原保护热度不断攀升,技术创新带来新突破
某半导体制造企业的案例颇具代表性,其光刻机在特定工艺节点频繁出现晶圆缺陷,传统数据挖掘发现缺陷率与腔体温度呈正相关,但调整温度后问题依旧,通过引入因果发现算法,系统识别出真正根源是冷却系统压力波动导致的温度瞬变,基于这一发现,数字孪生平台模拟了压力控制策略的优化方案,使缺陷率下降82%。 热度持续火爆关注智能制造发展动态,技术创新推动产业升级
这种突破依赖于贝叶斯网络、结构方程模型等因果分析工具,在某汽车焊接生产线中,数据挖掘团队构建了包含200多个变量的因果图,揭示了机器人轨迹偏差、电极帽磨损、板材厚度波动之间的传导路径,数字孪生平台据此开发了动态补偿算法,使焊接强度标准差缩小35%,避免了每年数百万的返工成本。

实时性的"生死时速":边缘计算与流式挖掘的融合
工业场景对实时性的要求远超其他领域,2026年,随着5G+TSN(时间敏感网络)的普及,数据采集的时延已降至毫秒级,但数据挖掘的响应速度仍是企业痛点,某电子装配厂曾因视觉检测系统的分析延迟,导致每小时损失3000个元件,直到引入边缘计算与流式挖掘的融合方案。
该方案在产线部署了搭载AI加速芯片的边缘节点,对摄像头采集的图像进行实时特征提取,采用增量学习算法对流式数据进行在线建模,当检测到元件偏移趋势时,立即触发机械臂调整,这种架构使缺陷识别时延从200ms降至15ms,产线效率提升18%。
从理论层面,流式挖掘突破了传统批处理的局限,其核心在于"滑动窗口"机制和"概念漂移"检测,某食品包装企业通过在数字孪生中嵌入流式挖掘模块,实时监测灌装机的液位控制信号,当检测到波动频率超出阈值时,系统自动切换至备用泵,避免了整条生产线的停机,这种动态适应能力,正是传统离线分析无法比拟的。
数据治理的"隐形战场":从脏数据到黄金矿脉
2026年家电数码与森林保护及可再生能源热度持续攀升,相关应用不断深化 工业数据的质量问题长期制约着数字孪生的效果,2026年,某能源企业的调研显示,其风电场SCADA数据中,32%的传感器存在校准偏差,15%的数据存在缺失值,这些"脏数据"会导致挖掘模型产生系统性偏差,某光伏企业曾因未处理温度传感器的漂移数据,导致数字孪生预测的发电量偏差高达25%。

数据治理的理论框架包含数据清洗、特征工程、元数据管理等环节,某工程机械企业建立了"数据质量看板",对关键参数进行实时监控,当液压系统压力数据的波动范围超过历史均值3倍标准差时,系统自动触发校验流程,并标记可疑数据段,通过这种机制,其数字孪生平台的预测准确率从78%提升至91%。
更前沿的探索在于"主动学习"技术,某制药企业让数字孪生平台根据数据不确定性自动生成采集任务,例如当反应釜温度模型的预测误差超过阈值时,系统会指令增加该时段的采样频率,这种"数据-模型"的闭环优化,使工艺开发周期缩短40%,同时减少30%的无效实验。
人机协同的"最后一公里":从算法到决策的转化
数据挖掘的终极价值在于支持决策,但工业场景的复杂性常使模型输出难以直接应用,2026年,行业开始强调"可解释AI"在数字孪生中的落地,某核电站的案例具有代表性:其数字孪生平台采用SHAP(Shapley Additive exPlanations)算法,对设备故障预测模型进行解释,将原本黑箱的神经网络输出转化为"温度异常贡献度42%、振动异常贡献度35%"等可理解指标,帮助工程师快速定位问题。
这种转化需要理论创新,某研究团队提出了"工业决策知识图谱"概念,将数据挖掘结果与领域知识结合,在某钢铁企业的热连轧生产线中,数字孪生平台不仅输出带钢厚度偏差的预测值,还通过知识图谱关联到"轧辊磨损量>0.5mm时需更换"等操作规则,直接生成维修工单,这种"算法-知识-行动"的链条,使产线综合效率提升12%。
安全性的"达摩克利斯之剑":数据挖掘的防御与攻击
随着数字孪生与工业互联网的深度融合,数据安全成为不可忽视的挑战,2026年,某汽车制造商的数字孪生平台遭遇攻击,黑客通过篡改焊接机器人参数数据,导致批量车身出现裂纹,这一事件促使行业重新审视数据挖掘的安全边界。 需求响应与绿色乡村及全民健身热度持续上升,相关产业迎来新机遇
防御层面,联邦学习等隐私计算技术开始应用,某跨国制造企业构建了跨工厂的数字孪生网络,各工厂在本地训练模型,仅共享梯度信息而非原始数据,既实现了知识迁移,又避免了数据泄露,攻击检测方面,某电网企业采用对抗样本训练方法,让数字孪生平台能识别被篡改的传感器数据,将虚假报警率降低至0.1%以下。
从理论视角,这涉及"数据完整性"与"模型鲁棒性"的双重保障,某研究团队提出的"工业数据免疫系统"概念,通过在数字孪生中嵌入异常检测模块,实时监测数据分布