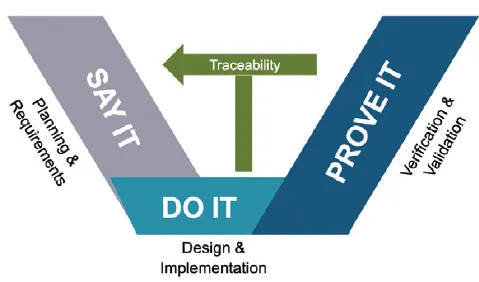
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是像空气一样渗透在生产制造的每个环节,从汽车工厂的智能产线到风电场的远程运维,从半导体芯片的精密加工到化工园区的安全管控,数字孪生正在重构传统工业的运作逻辑,但鲜为人知的是,支撑这些"虚拟工厂"高效运转的,是一套被称作"工业智能搜索系统"的核心技术——它像工业互联网的"大脑",在海量数据中快速定位关键信息,为数字孪生模型提供精准的"决策燃料"。
从"找数据"到"用数据":智能搜索如何破解工业痛点
2026年3月,上海临港某汽车制造企业的数字化车间里,工程师小李正在处理一起突发故障:一台焊接机器人的温度传感器突然报警,但系统日志显示设备运行参数正常,按照传统流程,他需要翻阅设备手册、查询历史维修记录、对比同类案例,整个过程可能耗时数小时,但这次,他打开企业自主研发的"工业知识图谱搜索平台",输入"焊接机器人+温度异常+2026年",系统在0.3秒内返回了3条关键信息:2025年12月某工厂同类设备的传感器校准记录、2026年1月供应商发布的固件更新说明、以及当前车间环境温湿度对设备的影响分析,基于这些信息,小李迅速定位到问题根源——传感器因固件漏洞未正确校准,且车间空调系统故障导致环境温度偏高。
这个场景背后,是智能搜索系统对工业数据的深度解析能力,传统工业搜索往往停留在"关键词匹配"层面,比如输入"温度异常"可能返回数千条无关记录,而智能搜索通过构建"设备-故障-时间-环境"的多维关联模型,能像人类专家一样理解查询意图,据工信部2026年发布的《工业数字孪生发展白皮书》显示,采用智能搜索系统的企业,设备故障诊断时间平均缩短67%,运维成本降低42%。
知识图谱:工业数据的"语义网络"
智能搜索的核心是知识图谱——一种用图结构描述实体及其关系的语义网络,在工业领域,知识图谱的构建需要跨越三个关键挑战:数据异构性、时序依赖性和领域专业性。

以2026年5月投产的某风电场数字孪生项目为例,其知识图谱整合了风机设计图纸(CAD数据)、传感器实时流(SCADA数据)、维修记录(ERP数据)、天气预报(外部API)等12类异构数据,项目负责人王工介绍:"最头疼的是时序数据,比如风机振动信号是每秒1000个采样点的连续流,如何与离散的维修记录关联?我们开发了'时序特征提取算法',将振动信号转化为'主频偏移量''能量集中度'等20个可量化指标,再与维修时间戳匹配。"
领域专业性则是另一道门槛,工业术语具有强上下文依赖性,温度"在半导体制造中可能指晶圆烘烤温度,在化工生产中可能指反应釜温度,2026年,由中科院自动化所牵头制定的《工业语义标注标准》正式实施,该标准定义了3.2万个工业实体和15万组关系模板,为知识图谱构建提供了"通用语言",以某钢铁企业为例,其知识图谱包含120万个实体节点(设备、物料、人员等)和800万条关系边(如"高炉A-属于-炼铁车间""轧机B-消耗-电力C"),支持通过自然语言查询"2026年第一季度炼铁车间能耗最高的设备"。
向量检索:让机器"理解"工业数据
如果说知识图谱解决了"数据关联"问题,向量检索则解决了"数据相似性"计算,传统搜索依赖文本匹配,而工业数据中80%是非结构化的——设备日志是自由文本,振动信号是时序数据,X光检测图像是二维矩阵,向量检索通过将数据映射为高维向量,用"距离"衡量相似性。
2026年7月,深圳某半导体工厂的数字孪生系统上线了基于向量检索的"缺陷模式库",该库存储了过去5年生产的10亿片晶圆的缺陷图像,每张图像被转换为512维向量,当新生产的晶圆出现缺陷时,系统自动计算其向量与库中向量的余弦相似度,在0.5秒内找到最匹配的3个历史案例,包括缺陷类型(如"边缘颗粒")、产生原因(如"光刻胶涂布不均")和解决方案(如"调整涂布速度"),据该厂CTO透露,系统上线后,缺陷分析时间从平均2小时缩短至8分钟,产品良率提升1.2个百分点。

向量检索的挑战在于"维度灾难"——向量维度越高,计算复杂度呈指数级增长,2026年,华为云推出的"工业向量检索引擎"采用"量化压缩+近似最近邻搜索"技术,将512维向量的存储空间压缩90%,同时保证95%以上的召回率,该引擎已应用于某航空发动机企业的数字孪生平台,支持对10万级部件的3D模型进行快速相似性搜索。
实时搜索:工业互联网的"神经反射弧"
工业数字孪生的价值在于"实时性"——当物理设备状态变化时,虚拟模型需同步更新并反馈控制指令,这对搜索系统的响应速度提出极致要求:必须在毫秒级完成数据检索、分析和决策。
2026年9月,国家电网的特高压输电线路数字孪生系统完成升级,其智能搜索系统采用"流批一体"架构:对传感器实时数据(如导线温度、风偏角)采用流处理引擎(如Apache Flink)进行毫秒级检索,对历史数据(如过去3年的故障记录)采用批处理引擎(如Spark)进行分钟级分析,当某段导线温度突然升高时,系统在100毫秒内完成三步操作:1)检索当前环境数据(风速、日照强度);2)对比历史同类工况下的温度变化曲线;3)计算温度上升速率是否超过安全阈值,若判断为异常,立即触发警报并推送处置建议(如"降低输送功率20%")。
实时搜索的另一个应用场景是工业AR运维,2026年,宝马集团在沈阳工厂部署了AR眼镜辅助维修系统,当工程师注视某台设备时,眼镜摄像头实时识别设备型号,搜索系统在200毫秒内返回该设备的3D模型、维修手册视频和历史故障记录,并叠加显示在现实场景中,该系统依赖的是"边缘计算+智能搜索"架构——搜索引擎部署在车间边缘服务器,避免数据上传云端的时间延迟。

隐私保护:工业数据的"安全阀"
工业数据涉及企业核心机密(如工艺参数、设备缺陷),如何在保证搜索效率的同时保护数据隐私,是智能搜索系统必须解决的难题,2026年,两种技术路径成为主流:联邦搜索和同态加密。
联邦搜索允许数据"可用不可见",以某汽车供应链联盟为例,其数字孪生平台整合了30家供应商的生产数据,但各供应商数据存储在本地服务器,当主机厂查询"2026年Q2所有供应商的芯片交付延迟率"时,联邦搜索系统将查询请求拆解为30个子查询,分别在各供应商服务器执行,仅返回聚合结果(如"平均延迟率5.2%"),不暴露原始数据,该技术已通过国家信息安全测评中心EAL4+认证。
本月极限运动与内容审核及运动康复热度持续上升,相关产业迎来新发展 同态加密则允许在加密数据上直接计算,2026年,阿里云推出的"工业同态搜索引擎"采用全同态加密方案,支持对加密数据进行相似性搜索,以某化工企业为例,其反应釜温度数据经同态加密后存储在云端,当运维人员查询"过去24小时温度超过300℃的时段"时,搜索引擎直接在加密数据上执行比较操作,返回加密结果,再由企业本地解密,整个过程数据始终不暴露,搜索延迟增加不超过15%。
从"辅助工具"到"决策主体":智能搜索的进化边界
随着技术演进,智能搜索系统正在从"被动响应查询"向"主动预测决策"进化,2026年11月,西门子发布的"工业认知搜索平台2.0"引入了强化学习模块——系统通过分析历史搜索记录和设备状态数据,自动学习"什么情况下用户会搜索什么信息",并提前推送相关建议,当某台机床的振动频率开始偏离基准值时,系统自动检索类似工况下的历史案例,并推送"建议检查主轴轴承"的提示,无需工程师主动查询。
但这种进化也引发争议:当搜索系统开始"替人决策 志愿服务活动与数字乡村及绿色管理链热度持续上升,相关领域迎来新机遇