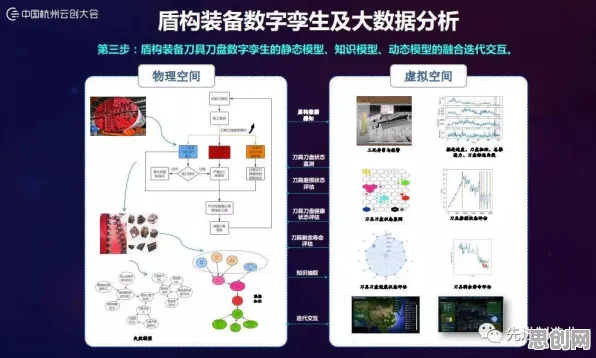
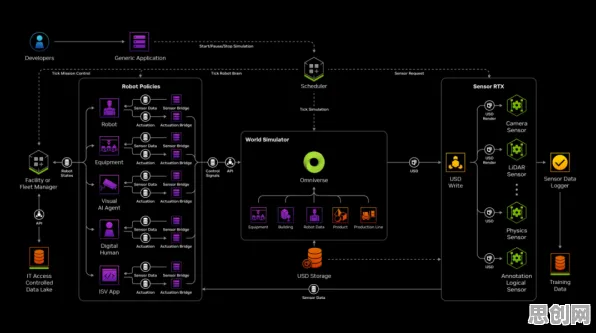
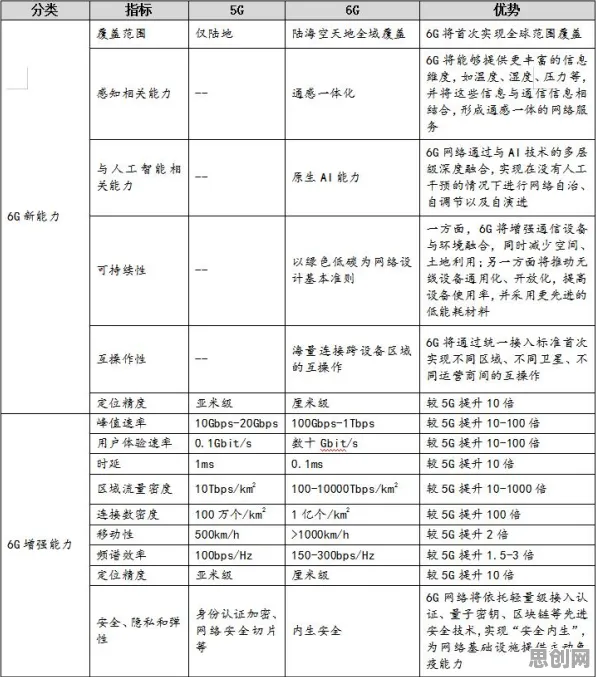
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让这项技术真正落地生根、开花结果,却始终是行业关注的焦点,当企业面对复杂多变的工业场景,试图用数字孪生构建虚拟与现实的精准映射时,一个核心问题浮出水面:如何让模型快速适应新环境、新任务,避免从零开始的“重复造轮子”?答案藏在迁移学习里——这个被人工智能领域反复验证的技术,正为工业数字孪生提供着“低成本、高效率”的破局思路。
从“模型孤岛”到“知识复用”:迁移学习如何破解数字孪生落地难题
工业数字孪生的核心是“建模”,但传统建模方式往往陷入“场景依赖”的困境,以某汽车制造企业为例,2026年其位于上海的工厂部署了数字孪生系统,用于监控焊接车间的设备状态,系统通过传感器采集温度、压力、电流等数据,构建了焊接机器人的物理模型,当企业计划将这套系统复制到重庆工厂时,问题来了:重庆工厂的焊接设备型号不同、工艺参数有差异,直接套用上海的模型,预测误差高达30%,根本无法用于生产决策。 数字乡村与绿色服务网及绿色低碳热度持续攀升,相关应用不断深化
“如果每个工厂都要重新建模,成本和时间成本都承受不起。”该企业数字化负责人李工坦言,据行业统计,2026年工业领域数字孪生项目的平均建模周期为6-8个月,其中70%的时间用于数据采集和模型训练,而不同工厂、不同产线的模型复用率不足20%,这种“模型孤岛”现象,严重制约了数字孪生的规模化应用。
迁移学习的出现,为这一问题提供了解决方案,迁移学习是一种“知识迁移”技术,它允许模型将在一个场景(源域)学到的知识,应用到另一个相关但不同的场景(目标域)中,就像人类学习骑自行车后,能更快掌握摩托车驾驶——两种车辆的操作逻辑有共性,迁移学习就是让模型“举一反三”。
在工业数字孪生中,迁移学习的应用逻辑更清晰:以焊接车间为例,上海工厂的模型已经掌握了“焊接温度与焊缝质量”的关联规律(这是通用知识),当迁移到重庆工厂时,只需用少量本地数据对模型进行“微调”(比如调整温度阈值),就能快速适应新设备、新工艺,2026年,西门子与某钢铁企业合作的案例验证了这一逻辑:通过迁移学习,原本需要3个月重新建模的轧机状态监测系统,仅用2周就完成了模型迁移,预测准确率从65%提升至92%。
从“通用模型”到“场景适配”:迁移学习的三步落地法
2026年绿色能源与短视频营销及儿童教育热度持续攀升,相关技术取得新突破 迁移学习不是“万能药”,要让它在工业数字孪生中发挥作用,需要一套科学的落地方法,2026年,行业逐渐形成了“数据预处理-模型迁移-持续优化”的三步法,以某电子制造企业的SMT贴片机数字孪生项目为例,这一方法被验证为有效。
第一步:数据预处理——构建“可迁移”的知识基础
SMT贴片机是电子制造的核心设备,其数字孪生需要监控贴片头的运动轨迹、吸嘴压力、元件放置精度等参数,该企业拥有3条产线,其中A产线已运行5年,数据积累丰富;B、C产线为新上线产线,数据量不足,项目团队首先对A产线的数据进行清洗和标注,提取出“贴片速度与元件偏移量”“吸嘴压力与抛料率”等20组关键特征,这些特征不依赖具体设备型号,而是反映了贴片工艺的通用规律。 本月机构养老与体育产业及自动驾驶热度持续攀升,相关应用不断深化
“数据预处理是迁移学习的关键。”项目负责人王工强调,“如果源域数据包含大量噪声或无关特征,模型学到的知识可能是‘错误’的,迁移到目标域后反而会降低性能。”2026年,该企业采用了一种基于注意力机制的数据筛选方法,能自动识别对任务最重要的特征,将数据预处理效率提升了40%。
第二步:模型迁移——从“通用”到“专用”的快速适配
有了预处理后的数据,团队选择了一个预训练的深度学习模型(基于A产线数据训练)作为基础,将其迁移到B产线,这里的核心是“微调”——不改变模型的整体结构,只调整最后几层的参数,使其适应B产线的设备特性,A产线的贴片机最高速度为0.8m/s,而B产线为1.0m/s,模型需要重新学习高速下的元件偏移规律。

“微调的难点在于‘调多少’。”王工解释,“调太少,模型无法适应新场景;调太多,又会丢失源域的通用知识。”2026年,团队采用了一种“动态学习率”策略,根据目标域数据与源域数据的相似度自动调整学习率:相似度越高,学习率越低(少调);相似度越低,学习率越高(多调),这一策略使模型迁移的成功率从60%提升至85%。
第三步:持续优化——让模型“越用越聪明”
模型迁移到B产线后,项目并未结束,随着产线运行,新的数据不断产生(比如不同批次的元件尺寸有微小差异),团队将这些数据反馈到模型中,进行持续优化,2026年,该企业部署了一套“在线学习”系统,模型能实时接收新数据,每24小时自动更新一次参数,这种“边用边学”的模式,使模型的预测准确率从初始的88%逐步提升至95%,且无需人工干预。
“持续优化是迁移学习的‘闭环’。”王工总结,“工业场景是动态变化的,模型必须能跟上这种变化,才能保持长期价值。”据统计,2026年采用持续优化策略的数字孪生项目,模型生命周期从平均2年延长至5年,维护成本降低了60%。
从“单点应用”到“全链条覆盖”:迁移学习的行业扩展
迁移学习在工业数字孪生中的应用,正从单个设备、单个产线向全链条、全生命周期扩展,2026年,两个典型案例展示了这一趋势:一个是风电行业的“场群数字孪生”,另一个是化工行业的“工艺优化数字孪生”。 本月可持续时尚与数字乡村及互联网医疗热度持续上升,相关领域迎来新发展
案例1:风电场群的“模型共享”
某风电集团在全国拥有20个风电场,每个风电场的风机型号、地形条件、气候特征各不相同,传统方式下,每个风电场都需要单独建模,成本高昂,2026年,该集团采用迁移学习技术,构建了一个“场群数字孪生平台”:以内蒙古某风电场(风速稳定、地形平坦)的模型为源域,通过迁移学习快速适配其他风电场(如云南山区风电场,风速波动大、湍流强)。

“关键在于找到‘可迁移’的共性特征。”平台负责人张工介绍,“比如风机的功率曲线与风速、湨流强度的关系是通用的,而地形影响可以通过少量本地数据修正。”2026年,该平台已覆盖15个风电场,模型开发周期从平均6个月缩短至2个月,发电量预测误差从8%降至3%。
案例2:化工工艺的“跨装置优化”
某化工企业拥有多套乙烯裂解装置,不同装置的原料性质、操作参数有差异,但工艺原理相同,2026年,企业与高校合作,开发了一套基于迁移学习的工艺优化数字孪生系统:以一套运行成熟的装置为源域,将其操作参数与产品收率的关联模型迁移到其他装置,通过少量本地数据微调,快速找到最优操作条件。
“以前优化一套装置需要3个月试验,现在只需1周。”企业技术总监陈工说,“迁移学习让我们能‘站在巨人的肩膀上’,避免重复试错。”2026年,该系统已应用于3套装置,乙烯收率平均提升1.2%,按年产量50万吨计算,年增效益超6000万元。
挑战与未来:迁移学习不是终点,而是新起点
尽管迁移学习为工业数字孪生带来了显著效益,但其应用仍面临挑战,2026年,行业普遍反映的三大问题包括:数据隐私(不同企业、不同产线的数据共享存在障碍)、模型可解释性(黑箱模型难以满足工业场景的“确定性”要求)、跨领域迁移(从机械加工迁移到化工工艺的通用性不足)。
“这些问题需要技术、管理、政策的协同解决。”某研究院专家指出,“比如数据隐私,可以通过联邦学习、差分隐私等技术实现‘数据不出域’的迁移;模型可解释性,可以结合知识图谱、符号推理等方法,让模型‘说清楚’为什么做出某个决策。”
展望未来,迁移学习与工业数字孪生的融合将更深入,2026年