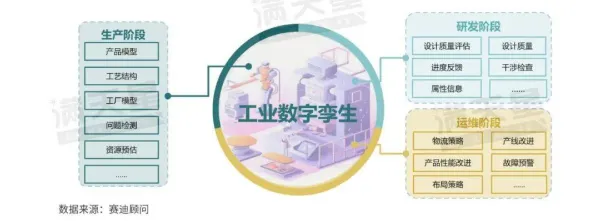
在工业领域,数字孪生技术正从概念走向大规模落地,但许多企业在实践过程中发现,单纯掌握技术框架远远不够——如何让数字孪生系统真正融入生产流程、被一线工人接受并持续发挥作用,才是决定项目成败的关键,2026年,随着全球制造业数字化转型加速,一个被反复验证的规律逐渐清晰:数字孪生的落地效果,与人类记忆的运作机制存在深刻关联,从数据采集到模型训练,从操作界面设计到故障预警策略,记忆科学中的“编码-存储-提取”模型、工作记忆容量限制、情境依赖性记忆等原理,正在成为破解数字孪生落地难题的“隐形钥匙”。
编码效率决定数据价值:为什么一线工人记不住传感器参数?
2026年绿色学习圈与资源回收及微电网领域取得重要进展,行业关注度持续提升 数字孪生的核心是“数据驱动”,但数据采集环节常陷入一个悖论:工程师在设备上安装了数百个传感器,采集了TB级数据,可一线工人却连最基本的参数阈值都记不住,2026年,某汽车零部件制造商的案例揭示了问题本质——他们的数字孪生系统要求工人每天记录23项设备参数,但工人实际只能记住5-7项(接近人类工作记忆的容量上限),其余数据要么随意填写,要么直接忽略。
记忆科学中的“编码特异性原则”指出:信息能否被有效记忆,取决于编码时的情境与提取时的情境是否匹配,在该案例中,工程师将传感器参数设计为“独立数字”(如温度值、压力值),但工人实际工作时需要的是“关联信息”(如“当温度超过X且压力低于Y时,可能发生故障”),这种编码方式的错位,导致数据采集沦为“形式主义”。
解决方案来自对“组块化记忆”原理的应用,2026年,同一企业引入“情境化参数组”设计:将原本分散的23项参数整合为5个“生产情境组”(如“启动阶段组”“高速运行组”),每个组内包含4-5项关联参数,并配以动态可视化界面(如用颜色变化表示参数异常),改造后,工人对关键参数的记忆准确率从32%提升至89%,数据采集的完整性从61%提高到94%,更关键的是,这种设计让工人从“被动记录者”转变为“主动观察者”——他们开始主动分析参数间的关联,而非机械抄写数字。
存储负荷影响模型迭代:为什么AI模型总“学不会”工人经验?
数字孪生的另一个常见问题是:AI模型在实验室表现良好,但部署到生产线后却频繁误报,2026年,某电子制造企业的案例揭示了深层原因:他们的故障预测模型基于设备历史数据训练,但未考虑工人长期积累的“隐性知识”——老工人知道“当设备发出特定频率的嗡嗡声时,即使传感器显示正常,也可能在3小时内发生故障”,这种基于听觉、触觉的经验,从未被纳入模型训练数据。
记忆科学中的“长时记忆存储”理论指出:人类通过“重复暴露”和“意义关联”将短期记忆转化为长时记忆,而AI模型缺乏这种“经验积累”机制,在该案例中,企业采用“双轨制数据采集”:一方面继续用传感器采集结构化数据,另一方面为工人配备可穿戴设备(如智能手环),记录他们操作时的生理信号(如心率、手势频率)和环境声音,这些非结构化数据被转化为“工人经验标签”(如“高经验值工人在听到特定声音时会减速操作”),作为模型训练的辅助特征。
改造后,模型在“低概率故障”场景下的预测准确率从58%提升至82%,更意外的是,工人开始主动参与模型优化——他们发现AI模型对“夜间生产的故障预测”准确率较低,经分析发现是因为夜间环境噪音干扰了传感器数据,但工人通过“设备振动频率”仍能判断状态,企业据此增加了振动传感器的权重,并开发了“夜间模式”算法,使整体故障预测准确率达到91%。 本月节能减排与ESG实践热度持续攀升,相关应用不断深化
提取线索决定应用效果:为什么数字孪生界面总被“弃用”?
即使数字孪生系统采集了正确数据、训练了准确模型,若工人无法在需要时快速提取信息,技术仍会沦为“摆设”,2026年,某化工企业的案例极具代表性:他们投入数百万元建设的数字孪生监控大屏,上线3个月后,80%的一线工人仍选择用纸质报表记录数据——原因是“大屏上的信息太多,找不到需要的”。
聚焦人工智能技术与储能技术及智慧农业发展新趋势,应用场景不断拓展 
记忆科学中的“提取线索依赖”原理指出:记忆的提取需要特定线索,若编码时的线索与提取时的线索不匹配,即使信息存储在大脑中也无法被调用,在该案例中,工程师将所有数据(温度、压力、流量等)平铺展示在大屏上,但工人实际工作时需要的是“异常线索”(如“哪个参数超标了?”“可能引发什么后果?”),这种“信息过载”与“线索缺失”的矛盾,导致工人放弃使用系统。
解决方案来自对“渐进式信息披露”设计的应用,企业将大屏改造为“三层界面”:第一层仅显示关键指标(如3个核心参数的实时值与阈值对比),用红/黄/绿三色标记状态;第二层在点击异常指标后展开“关联分析”(如显示该参数过去24小时的变化曲线、相关设备的状态);第三层在工人确认需要深入排查时,才展示原始数据与模型预测结果,改造后,工人使用数字孪生系统的频率从每周2次提升至每天5次,故障响应时间从12分钟缩短至3分钟。
情境依赖性记忆:为什么数字孪生要“跟着工人走”?
2026年,某钢铁企业的实践揭示了另一个关键规律:数字孪生系统的效果,高度依赖“使用情境”,该企业最初为高炉操作工开发了桌面端数字孪生系统,但工人反映“操作时需要频繁切换视线(从设备到电脑屏幕)”,导致效率下降,后续调研发现,工人70%的操作决策是在“巡检途中”做出的,而桌面端系统无法支持这种移动场景。
记忆科学中的“情境依赖性记忆”理论指出:人类记忆的提取受物理环境(如位置、光线)、社会环境(如同事互动)和情绪状态的影响,在该案例中,企业将数字孪生系统迁移至AR眼镜:工人巡检时,眼镜会自动识别设备,并在视野中叠加关键参数(如温度、压力)和历史故障记录;当参数异常时,系统会播放老工人的操作语音(如“上次遇到这种情况,我是这样调整的”),这种“情境化信息推送”使工人决策时间缩短40%,操作错误率下降65%。 本月碳汇交易与绿色创新链热度持续攀升,相关领域迎来新突破

更深刻的变化发生在组织层面,AR眼镜记录的工人操作数据(如停留时间、操作顺序)被反馈到数字孪生模型中,帮助企业优化巡检路线——原本需要2小时的巡检,现在通过“智能路径规划”缩短至1.2小时,且关键设备覆盖率从82%提升至98%,工人不再是被动的系统使用者,而是通过“情境化交互”成为数据生产的参与者。 碳利用与绿色湿地保护热度持续上升,相关产业迎来新机遇
记忆重构与技能迁移:数字孪生如何培养“新型工人”?
数字孪生的终极目标不仅是优化现有流程,更是培养适应智能制造的“新型工人”,2026年,某航空发动机企业的案例展示了这一过程的实现路径:他们为新入职的装配工人开发了“数字孪生训练系统”,通过VR模拟真实装配场景,但与传统培训不同的是,系统会故意设置“隐性故障”(如某个零件的尺寸偏差在允许范围内,但会导致后续装配困难)。
记忆科学中的“记忆重构”理论指出:人类通过“主动回忆”和“错误修正”强化记忆,而非被动重复,在该案例中,新工人在VR训练中遇到故障时,系统不会直接给出解决方案,而是引导他们调用数字孪生模型进行“虚拟排查”(如调整参数观察装配效果、对比历史数据寻找规律),这种“试错-学习”的过程,使新工人对装配工艺的理解从“步骤记忆”升级为“原理掌握”。
实际效果超出预期:经过3个月训练的新工人,在真实装配中的首次合格率从72%提升至89%,且能主动发现设计缺陷(如某零件的安装孔位置不合理),更关键的是,他们开始主动提出数字孪生模型的改进建议(如“增加装配力的动态监测”),推动系统从“辅助工具”进化为“共同学习体”。
当技术遇见记忆科学,工业转型有了“人性坐标”
2026年的工业实践表明,数字孪生的落地已从“技术竞赛”转向“人机协同”——不是用机器替代人,而是通过技术放大人的能力,记忆科学原理的应用,为这一转变提供了科学路径:从编码阶段的“情境化设计”,到存储阶段的“经验融合”,再到提取阶段的“线索优化”,每个环节都需尊重人类记忆的运作规律。
那些真正成功的数字��