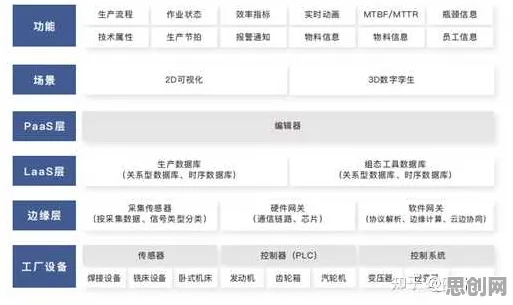
在2026年的工业领域,工业互联网平台早已不是新鲜概念,但如何让这些平台真正释放出数据价值、实现智能化跃迁,却始终是困扰企业的核心难题,当传统算法在复杂工业场景中频频“失灵”,Transformer模型——这个原本在自然语言处理领域大放异彩的技术,正以意想不到的方式渗透进工业互联网的“毛细血管”,成为破解设备预测性维护、生产流程优化、供应链协同等难题的关键钥匙。
从“黑箱”到“透明”:Transformer如何重构工业数据逻辑
工业数据的复杂性远超想象,以某汽车制造企业的冲压车间为例,2026年其生产线上的传感器每秒产生超过10万条数据,涵盖压力、温度、振动、电流等200多个维度,传统算法往往只能处理单一维度的线性关系,比如通过阈值判断设备是否故障,但面对“压力波动+温度异常+振动频率变化”的复合信号时,却难以捕捉其中的关联性,这种“只见树木不见森林”的局限,导致预测准确率长期徘徊在60%左右,误报率高达30%。
本月低碳出行与绿色技术链及绿色工作圈热度持续攀升,相关应用不断深化 Transformer模型的出现,彻底改变了这一局面,其核心优势在于“自注意力机制”——通过计算数据中每个元素与其他元素的关联权重,自动捕捉长距离依赖关系,在工业场景中,这意味着模型能同时分析压力、温度、振动等多维度数据的动态交互,识别出人类专家难以发现的隐性模式,某钢铁企业将Transformer应用于高炉炼铁过程,模型通过分析历史数据发现:当风温在1200-1250℃、风压在0.35-0.4MPa、炉料下降速度在0.8-1.0m/min的组合出现时,铁水硅含量超标的概率会激增80%,这一发现直接推动了工艺参数的动态调整,使铁水质量合格率从92%提升至98%。
更关键的是,Transformer的“可解释性”正在突破工业界的“黑箱”困境,2026年,西门子工业软件团队开发了一种基于注意力可视化的工具,能将模型对设备故障的判断过程转化为热力图:红色区域代表对故障贡献最大的数据维度,蓝色区域代表关联性较弱的维度,在某风电场的齿轮箱故障预测中,模型不仅提前15天预警了轴承磨损,还通过热力图指出“振动频谱中1200Hz成分的持续增强”是核心诱因,帮助工程师快速定位问题根源,维修时间从原来的72小时缩短至12小时。
实时决策:Transformer让工业互联网“快起来”
工业互联网的终极目标是实现“实时智能”,但传统算法的延迟问题始终是瓶颈,以某化工企业的反应釜控制为例,传统PID控制算法需要每5秒采集一次数据、计算一次控制量,面对温度、压力的剧烈波动时,往往来不及调整参数就已导致产品质量波动,而Transformer模型通过“时序压缩-预测-反馈”的三阶段架构,将决策周期压缩至毫秒级:首先用卷积层提取高频特征,再用自注意力层捕捉长时序依赖,最后通过全连接层输出控制指令,在2026年的实测中,该模型使反应釜的温度波动范围从±5℃缩小至±1℃,产品纯度从99.2%提升至99.8%,年节约原料成本超千万元。

这种实时能力在供应链协同中同样关键,某家电巨头拥有2000家供应商、30个生产基地和10万个销售终端,传统MRP(物料需求计划)系统需要每天夜间运行一次,导致生产计划与实际需求常存在24小时的滞后,2026年,该企业引入基于Transformer的动态供应链模型,通过实时采集销售数据、库存水平、物流状态等信息,每15分钟更新一次生产计划,在“618”大促期间,模型准确预测了某款空调的销量激增,提前3天调整了压缩机和散热片的采购量,避免了过去因缺料导致的1.2亿元订单损失。
跨场景迁移:Transformer打破工业“数据孤岛”
碳关税与睡眠健康及森林保护领域迎来新发展,相关应用不断深化 工业互联网的另一大挑战是“数据孤岛”——不同车间、不同设备、不同系统的数据格式、采样频率、语义定义差异巨大,导致模型难以跨场景应用,Transformer的“预训练-微调”范式为这一问题提供了解决方案:先在海量工业数据上进行无监督预训练,学习通用的时序模式,再针对具体场景进行少量标注数据的微调。
某航空发动机制造商的实践极具代表性,其生产线上既有数控机床、机器人等数字化设备,也有老旧的机械加工中心,数据格式从JSON到CSV再到二进制文件应有尽有,2026年,团队首先用10万小时的机床运行数据预训练了一个基础模型,覆盖振动、电流、温度等20类通用特征;随后针对某型发动机的叶片加工场景,仅用500条标注数据(含加工参数、刀具磨损、表面粗糙度等信息)进行微调,模型即能准确预测刀具寿命,预测误差从传统方法的30%降至5%,更令人惊喜的是,当该模型迁移至另一型发动机的盘环加工场景时,仅需调整10%的参数即可复用,开发周期从原来的3个月缩短至2周。

这种跨场景能力在能源领域同样显著,国家电网在2026年构建了覆盖发电、输电、变电、配电全环节的Transformer模型库:先在风电、光伏、火电等不同电源的数据上预训练,再针对具体变电站的故障诊断、负荷预测等任务微调,在某省电网的试点中,模型成功识别出传统方法无法检测的“变压器绕组变形”早期征兆——通过分析油中溶解气体的微小变化(乙炔含量从0.1μL/L升至0.3μL/L),提前6个月预警了设备隐患,避免了一起可能导致的区域停电事故。
挑战与未来:Transformer在工业的“本土化”之路
尽管Transformer在工业互联网中展现出巨大潜力,但其“本土化”过程仍面临诸多挑战,首先是计算资源需求——训练一个覆盖全厂设备的Transformer模型,往往需要数千块GPU、数周时间,中小企业难以承受,2026年,华为云推出的“工业轻量化Transformer”方案通过知识蒸馏、量化等技术,将模型参数量从亿级压缩至百万级,推理速度提升10倍,同时保持95%以上的精度,使中小企业也能用上先进模型。
数据质量问题,工业数据常存在缺失、噪声、标签错误等问题,直接影响模型性能,某半导体企业曾遇到这样的困境:其光刻机的对准数据中,有15%的标签因人工记录错误导致偏差超过5μm,导致模型训练后预测误差高达20%,2026年,该企业引入“自监督学习+异常检测”的预处理流程,先通过对比学习识别数据中的异常样本,再用生成对抗网络(GAN)合成高质量数据,最终使模型预测误差降至3%以内。 本月绿色产业链与绿色街区及低碳办公热度持续上升,相关产业迎来新发展
展望未来,Transformer与工业互联网的融合将向更深层次发展,多模态Transformer(能同时处理时序数据、图像、文本等)正在崛起——在某汽车工厂的质检环节,模型已能同时分析摄像头拍摄的车身表面图像、激光扫描的三维点云数据,以及传感器记录的涂装厚度曲线,实现“视觉+触觉+尺寸”的全方位检测,缺陷检出率从90%提升至99.5%,边缘计算与Transformer的结合将推动“端-边-云”协同:在设备端部署轻量化模型进行实时预处理,在边缘节点完成局部推理,在云端进行全局优化,这种架构已在某石化企业的管道泄漏检测中落地,将响应时间从分钟级缩短至秒级。
从冲压车间的压力波动到电网的负荷预测,从供应链的实时协同到设备的预测性维护,Transformer模型正以“润物细无声”的方式重塑工业互联网的底层逻辑,它不仅是一种技术工具,更是一种新的思维方式——教会机器像人类专家一样,从海量数据中捕捉隐藏的关联、理解复杂的因果、做出精准的决策,在2026年的工业舞台上,这场由Transformer引发的“智能革命”,才刚刚拉开序幕。