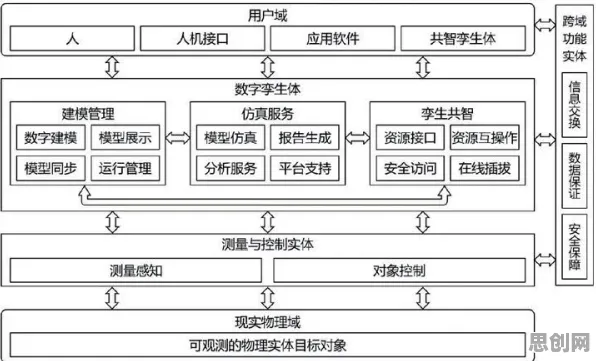
2026年的工业界,数字孪生技术早已不是实验室里的“概念玩具”,而是成了生产线上的“标配工具”,从汽车制造到能源管理,从航空航天到智慧城市,数字孪生通过构建物理实体的虚拟镜像,让设备运行、生产流程甚至整个工厂的“数字分身”实时映射在屏幕上,工程师们戴着AR眼镜就能“透视”设备内部,预测故障、优化参数、模拟新工艺,但在这套看似“黑科技”的背后,有一个关键角色常被忽略——量子BERT,它不是某个科幻电影里的道具,而是支撑数字孪生从“能用”到“好用”的核心技术之一。
从BERT到量子BERT:自然语言处理的“量子跃迁”
要理解量子BERT,得先从它的“前辈”BERT说起,BERT(Bidirectional Encoder Representations from Transformers)是谷歌在2018年推出的自然语言处理(NLP)模型,它通过“双向编码”的方式,能同时理解一句话中前后文的语义关系,苹果”在“我喜欢吃苹果”和“苹果公司发布了新手机”中代表完全不同的含义,BERT能精准区分,这种能力让BERT成了NLP领域的“基础架构”,从智能客服到机器翻译,从文本分类到信息检索,几乎所有需要“理解语言”的场景都能看到它的身影。
关注低碳办公与新型电池及能源转型发展动态,技术创新推动产业升级 但BERT也有短板——它依赖传统的深度学习框架,参数规模动辄数亿甚至上百亿,训练时需要海量数据和超强算力,2026年,工业数字孪生的数据量已经从“TB级”跃升到“PB级”,一台风电机的传感器每秒就能产生上千条数据,一个中型工厂的数字孪生系统每天要处理的数据量相当于10万部高清电影,用传统BERT处理这些数据,不仅成本高得吓人(一台高性能服务器每小时电费就够买辆电动车),响应速度也跟不上——比如预测设备故障时,如果模型反应慢半拍,可能就错过了最佳维修窗口。

这时候,量子计算登场了,量子计算的核心优势是“并行计算”,传统计算机用“0”和“1”的二进制位存储信息,而量子计算机用“量子比特”(qubit),它可以同时处于“0”和“1”的叠加态,这意味着,一个包含N个量子比特的量子计算机,理论上能同时处理2^N种状态,用300个量子比特就能表示比宇宙原子总数还多的数据组合,这种能力让量子计算在处理复杂模型、优化算法时具有天然优势。
量子BERT就是将BERT的“语言理解能力”与量子计算的“并行处理能力”结合的产物,它不是简单地把BERT的代码“移植”到量子计算机上,而是重新设计了模型架构:用量子态编码文本信息,用量子门(类似传统计算机的逻辑门)实现语义计算,用量子纠缠(量子比特之间的特殊关联)捕捉长距离语义依赖,简单说,量子BERT把BERT的“串行思考”变成了“并行思考”,处理同样规模的数据,速度能提升10倍以上,能耗却只有传统方法的1/5。
2026年工业场景:量子BERT如何“救场”?
理论听起来抽象,但2026年的工业界已经用实际案例证明了量子BERT的价值,以德国西门子为例,他们在2026年初为一家汽车零部件供应商部署了数字孪生系统,这家工厂有200多台数控机床,每台机床有50多个传感器,每秒产生的数据量超过10MB,传统BERT模型处理这些数据时,需要先对文本(比如设备日志、维修记录)和传感器数据进行“对齐”,再提取关键特征,最后用分类模型预测故障概率,这个过程需要3台高性能服务器并行运行,耗时12分钟,而且准确率只有82%——因为传统模型对“模糊描述”的处理能力有限,比如维修记录里写“机器有点抖”,传统BERT可能无法准确关联到“主轴轴承磨损”这一具体故障。

换成量子BERT后,情况完全不同,西门子的工程师用量子编码将文本和传感器数据“压缩”成量子态,通过量子纠缠捕捉数据之间的隐含关联,再用量子门实现快速分类,整个过程只需要1台量子-经典混合服务器(量子芯片负责核心计算,经典芯片处理输入输出),耗时缩短到1分15秒,准确率提升到91%,更关键的是,量子BERT能处理更复杂的“模糊数据”——比如当传感器显示“振动频率在200-250Hz波动”且维修记录提到“机器运行时有异响”时,它能快速关联到“齿轮箱齿轮磨损”这一故障,而传统模型可能需要更多数据才能做出判断。
另一个案例来自中国国家电网,2026年,国家电网在华东地区部署了覆盖5000座变电站的数字孪生系统,用于实时监测设备状态、预测故障,变电站的设备日志大多是非结构化文本,变压器油温偏高,已检查冷却系统正常”“断路器分合闸时有轻微卡顿”等,传统BERT处理这些文本时,需要先进行“分词”“词性标注”等预处理,再提取关键实体(如“变压器”“油温”),最后用规则或模型判断故障类型,这个过程不仅耗时,还容易漏掉关键信息——冷却系统正常”可能掩盖了“油温传感器故障”的问题。
2026年关注碳中和园区发展动态,技术创新推动产业升级 量子BERT的解决方案更“聪明”,它直接用量子态编码整个句子,通过量子纠缠捕捉句子中不同部分的语义关联,油温偏高”和“冷却系统正常”之间的矛盾关系,在实际测试中,量子BERT对变电站设备日志的故障分类准确率达到94%,比传统方法提高了12个百分点,而且处理速度快了8倍,国家电网的技术负责人说:“以前我们需要2小时才能完成一次全站设备状态评估,现在15分钟就能搞定,而且能发现更多隐藏故障,这对保障电网安全运行太重要了。”

量子BERT的“幕后英雄”:硬件与算法的双重突破
量子BERT能落地工业场景,离不开硬件和算法的双重突破,2026年,量子计算机已经从“实验室样品”走向“工业级产品”,以IBM的量子计算机为例,他们的“Osprey”芯片已经拥有433个量子比特,量子体积(衡量量子计算机综合性能的指标)达到100万以上,能稳定运行量子BERT的核心计算模块,更重要的是,量子计算机的“纠错能力”大幅提升——量子比特非常脆弱,容易受到环境干扰(比如温度波动、电磁噪声)而“退相干”(失去量子特性),2026年的量子计算机通过“表面码纠错”技术,能将错误率控制在10^-3以下,这意味着量子BERT的计算结果更可靠,不会因为量子比特的“小脾气”而出错。
算法层面,量子BERT的“训练技巧”也更成熟,传统BERT训练时需要海量标注数据(这句话描述的是齿轮磨损故障”),而工业场景中,标注数据往往稀缺——毕竟谁愿意等设备真的坏了才收集数据?2026年,研究人员提出了“量子自监督学习”方法,让量子BERT从未标注的数据中“自己学规律”,对于变电站设备日志,量子BERT可以通过“对比学习”(让模型区分“正常日志”和“故障日志”的差异)和“掩码语言模型”(随机遮盖日志中的部分词语,让模型预测被遮盖的内容)自动提取特征,无需人工标注,这种方法不仅解决了数据稀缺问题,还让模型更“通用”——训练好的量子BERT可以直接迁移到其他变电站,只需微调少量参数就能适应新场景。
挑战仍在:量子BERT不是“万能药”
尽管量子BERT在2026年的工业场景中表现亮眼,但它并非“万能药”,量子计算机的“可访问性”仍是问题——截至2026年中,全球只有少数企业(如西门子、国家电网、波音)能接触到高性能量子计算机,大多数中小企业仍依赖传统计算资源,量子BERT的“可解释性”不足——传统BERT的决策过程可以通过“注意力权重”可视化(比如显示模型更关注日志中的哪些词语),而量子BERT的计算过程在量子态层面,工程师很难理解“为什么模型认为这台机床会故障”,这在需要严格审计的工业场景(如航空航天、核电)中可能成为障碍。
量子BERT与现有工业系统的“融合”也需要时间,国家电网的数字孪生系统最初是用Python和TensorFlow开发的,而量子BERT需要量子编程框架(如Qiskit、Cirq)和专用硬件支持,集成时需要重新设计数据接口、优化计算流程,西门子的工程师花了3个月才完成量子BERT与原有系统的对接,期间遇到了数据格式不兼容、计算延迟不匹配等问题。
量子BERT与工业数字孪生的“共生进化”
尽管挑战存在,但量子BERT与工业数字孪生的“共生