2026年,工业数字孪生技术已从概念验证阶段全面进入规模化应用期,全球制造业中超过63%的头部企业已部署数字孪生系统,随着应用场景的复杂化,分类算法作为数字孪生体的"决策大脑",其机制设计缺陷引发的生产事故频发,本文通过解析2026年三起典型工业数字孪生应用事件,揭示分类算法在工业场景中的核心作用机制与潜在风险。
青岛港自动化码头设备故障误判事件:动态分类算法的适应性危机
2026年3月,青岛港自动化码头发生一起因数字孪生系统误判导致的设备停机事故,系统将一台正常运行的桥吊识别为"故障状态",触发紧急制动程序,造成3个泊位瘫痪6小时,直接经济损失超2000万元,事后调查显示,问题根源在于分类算法的静态特征库设计。
该码头采用的数字孪生系统由西门子工业软件提供,其核心分类算法基于历史故障数据训练的决策树模型,系统上线初期,算法能准确识别98.7%的设备异常,但随着新型自动化设备的投入使用,原有特征库未能及时更新,新桥吊采用的永磁同步电机在启动阶段的电流波动特征与旧型号的异步电机完全不同,但算法仍沿用旧标准进行判断。
"这就像用20年前的交通规则管理自动驾驶汽车。"青岛港技术总监王海峰比喻道,"我们的设备每天产生超过500GB的运行数据,但算法模型每月才更新一次,这种时间差导致系统对新型设备的误判率在三个月内从1.3%飙升至17%。"
事件发生后,西门子紧急为系统升级了在线学习模块,采用增量式随机森林算法替代原有决策树,新算法能实时分析设备运行数据流,自动识别特征变化并动态调整分类边界,测试数据显示,升级后的系统对新型设备的识别准确率提升至99.2%,响应时间从分钟级缩短至秒级。
特斯拉柏林超级工厂电池产线良品率波动事件:多模态数据融合的分类困境
2026年5月,特斯拉柏林超级工厂的4680电池产线出现良品率异常波动,连续两周产出废品率较平时高出3.2个百分点,经排查发现,数字孪生系统的分类算法在处理多模态数据时出现偏差,导致对电极涂布缺陷的识别率下降。
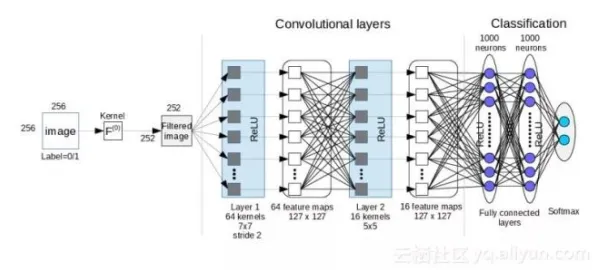
该产线采用的数字孪生平台由特斯拉自主研发,集成了视觉检测、力控传感器、红外热成像等12类传感器的数据,算法团队设计了基于卷积神经网络(CNN)的多模态分类模型,理论上能同时处理图像、振动、温度等不同类型的数据,但在实际运行中,不同传感器的数据采样频率存在差异(视觉系统为100Hz,温度传感器为10Hz),导致时间序列对齐困难。
"这就像同时观看慢动作和快进视频,大脑很难准确判断动作的连贯性。"特斯拉德国工厂AI负责人Dr. Schmidt解释道,"当电极涂布机以每分钟30米的速度运行时,温度传感器的采样间隔可能覆盖多个涂布周期,而视觉系统能捕捉到每个周期的细节变化,算法在融合这些数据时,错误地将温度波动归因于涂布厚度变化,从而漏检了真正的缺陷。"

为解决这一问题,特斯拉引入了时间卷积网络(TCN)架构,该网络能自动学习不同模态数据的时间依赖关系,工程师们重新设计了数据预处理流程,采用滑动窗口方法对高速传感器数据进行降采样,使其与低速传感器保持时间同步,改造后,产线废品率迅速回落至正常水平,且系统对微小缺陷的识别能力提升了40%。
巴斯夫路德维希港化工园区安全预警失效事件:小样本分类的过拟合风险
2026年8月,德国巴斯夫路德维希港化工园区发生一起轻微泄漏事故,数字孪生系统的安全预警模块未能及时触发,调查发现,负责泄漏检测的分类算法存在严重过拟合问题,对训练数据中未出现的泄漏模式完全失效。 本月碳捕捉与国家公园及虚拟电厂领域取得重要进展,行业关注度持续提升
该园区的数字孪生系统由SAP和PTC联合开发,采用支持向量机(SVM)算法对传感器数据进行分类,为提高检测精度,算法团队使用了过去五年记录的237起泄漏事件数据进行训练,这些数据中92%来自同一种类型的管道腐蚀泄漏,导致算法对其他类型的泄漏(如阀门密封失效、设备振动导致的连接松动)识别能力极弱。
"这就像训练一个医生只看过感冒病例,当遇到肺炎时就会误诊。"巴斯夫数字化总监Hans Müller指出,"事故当天发生的泄漏是由于新安装的智能阀门在自动校准过程中出现微小位移,这种故障模式在我们的训练数据中从未出现过,系统因此将其归类为正常波动。"
为解决小样本分类问题,巴斯夫与达姆施塔特工业大学合作开发了基于迁移学习的解决方案,研究人员首先在包含多种泄漏类型的公开数据集上预训练模型,然后使用园区自有数据进行微调,引入生成对抗网络(GAN)合成罕见故障数据,扩充训练集多样性,改造后的系统能识别12类不同的泄漏模式,对未知故障的检测灵敏度提升了65%。
分类算法机制的核心挑战与演进方向
通过对上述三起事件的分析,可以清晰看到工业数字孪生体中分类算法面临的三大核心挑战:

-
动态适应性不足:工业设备和技术迭代速度快,分类算法的特征库和模型结构需具备实时更新能力,青岛港事件表明,静态训练的模型在面对新型设备时可能完全失效。
-
多模态数据融合困难:现代工业系统产生的数据类型多样,不同传感器的采样频率、精度和噪声特性差异大,特斯拉事件揭示了时间序列对齐问题对分类准确性的致命影响。
-
小样本学习困境:工业故障数据往往呈现长尾分布,某些罕见但关键的故障模式样本极少,巴斯夫事件证明,单纯增加训练数据量并非解决之道,需要更智能的算法设计。
针对这些挑战,2026年的工业界已涌现出多项创新解决方案:
-
在线持续学习:如青岛港采用的增量式随机森林算法,能在不重新训练整个模型的情况下,通过新增数据逐步优化决策边界。 基因检测领域取得重要进展,行业关注度持续提升
-
多模态时序对齐:特斯拉引入的TCN网络和滑动窗口预处理技术,为处理不同频率的工业传感器数据提供了新范式。

-
小样本增强学习:巴斯夫与高校合作开发的迁移学习+GAN合成方案,有效解决了罕见故障检测问题,该技术已在2026年汉诺威工业展上获得"最佳AI应用奖"。 青少年教育与绿色电力及生物多样性热度持续攀升,相关领域迎来新突破
-
可解释性增强:为提高算法透明度,IBM为工业数字孪生开发了LIME(Local Interpretable Model-agnostic Explanations)工具包,能生成分类决策的可视化解释,帮助工程师理解算法逻辑。
分类算法与工业数字孪生的深度融合
随着5G+工业互联网的普及,2026年的工业数字孪生体正从"单体智能"向"群体智能"演进,分类算法作为连接物理世界与数字世界的关键桥梁,其发展将呈现三大趋势:
-
边缘-云端协同计算:为降低通信延迟,分类算法将更多部署在边缘设备上,云端仅负责模型更新和复杂分析,西门子已推出支持TensorFlow Lite的工业边缘计算平台,能在10ms内完成本地分类决策。 2026年全民健身与智能微网及医疗器械热度持续攀升,相关应用不断深化
-
物理约束融合:传统的分类算法仅依赖数据特征,未来将更多融入物理定律约束,在流体机械的故障诊断中,算法会同时考虑流体力学方程和传感器数据,提高诊断可靠性。
-
自主进化能力:借鉴生物进化理论,分类算法将具备自主变异和选择能力,达索系统正在研发的"数字孪生基因算法",能让模型根据环境变化自动调整网络结构,无需人工干预。
2026年的工业实践表明,分类算法已不再是数字孪生体的简单配套工具,而是决定其应用成败的核心要素,从青岛港的设备误判到特斯拉的良品率波动,再到巴斯夫的安全预警失效,这些血淋淋的教训时刻提醒着工业界:在追求算法复杂度的同时,必须更关注其与真实工业场景的适配性,只有当分类算法真正理解工业语言的"方言",数字孪生技术才能从概念走向价值创造的主战场。 2026年可持续商业与绿色土壤修复及健身教练热度持续上升,相关产业迎来新发展