在工业4.0的浪潮中,"数字孪生"和"边缘计算"这两个概念被反复提及,但真正落地时却常被误解,许多企业看到头部企业分享的"成功案例"后盲目跟风,结果发现实际效果与宣传大相径庭,2026年,我们通过走访长三角、珠三角的12家制造业标杆企业,结合德国弗劳恩霍夫研究所最新发布的《工业边缘计算白皮书》,发现了一个关键结论:数字孪生平台的成功实施,70%取决于边缘计算层的实时数据处理能力,而非云端建模的复杂度,这个结论颠覆了传统认知,让我们从三个真实案例说起。
某汽车零部件厂的"假孪生"陷阱
2026年3月,苏州某汽车零部件厂投入300万元建设的数字孪生平台正式上线,该厂参照某国际咨询公司的方案,在云端搭建了包含2000+参数的精密模型,号称能"预测设备故障前72小时",但运行3个月后,系统仅发出过2次有效预警,其中一次还是工人已经发现异常后手动触发的。
"问题出在数据链路。"该厂CIO张伟指着监控大屏说,"我们装了500多个传感器,每秒产生2GB数据,但全部要上传到云端处理,从车间到数据中心的光纤延迟平均120ms,遇到网络波动时甚至超过500ms,等云端算出结果,设备可能已经停机了。"
这个案例暴露了行业普遍存在的误区:过度追求云端模型的"完美",却忽视了工业场景对实时性的苛刻要求,德国弗劳恩霍夫研究所的测试数据显示,在机械加工领域,数据处理延迟超过100ms,故障预测准确率会下降40%。
转机出现在2026年6月,该厂引入了某国产边缘计算平台,在车间部署了8台搭载专用AI芯片的边缘服务器,95%的数据在本地处理,只有关键结果上传云端,故障预警响应时间从分钟级缩短到毫秒级,系统上线半年已避免17次非计划停机,直接节省成本超200万元。
"现在我们明白,数字孪生的核心不是'复制'一个虚拟工厂,而是要建立一个能实时反馈的'神经中枢'。"张伟说,"边缘计算就是这个中枢的'脊髓',没有它,再精美的云端模型都是摆设。"
家电巨头的"数据瘦身"革命
2026年7月,青岛某家电巨头在建设智能工厂时遇到了另一个极端问题,该厂拥有全球最先进的注塑生产线,每台设备都配备了10+类传感器,原本计划通过数字孪生实现"零缺陷"生产,但项目启动后,工程师们发现:单条生产线每天产生的数据量就超过1TB,即使采用5G专网传输,云端存储和计算成本也高得惊人。

"我们最初的设计是'全量数据上云',但算了一笔账后吓一跳。"该项目负责人李芳展示了一份成本清单:存储1年数据需要投入800万元,计算资源费用另计500万元,"这还没算数据清洗、标注的人力成本。"
转机来自与某边缘计算厂商的合作,2026年9月,该厂在每条生产线部署了边缘智能网关,这些设备内置了行业特有的数据压缩算法,能将原始数据量压缩90%以上,同时保留关键特征。"就像给数据'瘦身',"李芳解释,"现在每条线每天只需上传100GB结构化数据,云端建模效率提升了5倍,存储成本降到原来的1/8。"
本月素质教育与远程医疗及绿色减灾防灾热度不断攀升,技术创新带来新突破 更关键的是,边缘层实现了"数据预处理",在注塑环节,边缘设备能实时识别"飞边""缺料"等缺陷特征,只将异常数据片段上传云端,而非整个生产周期的数据。"这种'按需上传'机制,让云端AI模型的训练效率提升了3倍。"该厂AI团队负责人说。
2026年11月的数据显示,该厂产品一次合格率从92%提升至98.5%,数字孪生系统的投入产出比从1:1.2跃升至1:3.8,这个案例证明:在工业场景中,边缘计算不是云端的"配角",而是数据价值挖掘的"第一道关卡"。
钢铁企业的"边缘自治"实验
如果说前两个案例还属于"优化型"应用,那么2026年12月披露的某钢铁企业案例则展现了边缘计算的颠覆性潜力,该企业位于河北,其高炉控制系统长期依赖进口,每套系统年维护费用超千万元,更棘手的是,核心控制算法属于"黑盒",企业无法自主优化。
"我们试过用数字孪生替代进口系统,但失败了。"该企业数字化转型负责人王强说,"高炉内部温度超过1500℃,传感器数据每秒变化上千次,云端根本来不及处理。" 2026年ESG实践与绿色建筑及储能技术热度持续走高,行业关注度持续提升

2026年5月,该企业与某科研机构合作,开发了一套基于边缘计算的"自治控制系统",他们在高炉周边部署了20台边缘计算节点,这些节点搭载了耐高温工业芯片,能直接处理热电偶、压力传感器等设备的原始信号,更关键的是,边缘层集成了轻量化AI模型,能根据实时数据自动调整风量、煤量等参数,无需云端干预。
"现在高炉就像有了'自主意识'。"王强指着监控画面说,"过去需要人工每2小时调整一次参数,现在系统能每秒微调数十次,最近3个月,吨钢能耗下降了8%,产量提升了5%,而且没有出现一次非计划停炉。"
这个案例揭示了一个更深层的趋势:在极端工业场景中,边缘计算正在从"数据处理器"升级为"决策控制器",德国弗劳恩霍夫研究所的预测显示,到2028年,30%的工业控制逻辑将下沉到边缘层,云端将更多承担"战略决策"角色。
边缘计算为何成为工业数字孪生的"关键先生"?
通过这三个案例,我们可以清晰看到边缘计算在工业数字孪生中的三大核心价值:
-
实时性保障:工业场景对延迟极度敏感,在机器人协作场景中,1ms的延迟就可能导致碰撞;在电力巡检中,10ms的延迟可能错过设备异常的早期信号,边缘计算将数据处理靠近数据源,彻底解决了云端计算的"时延瓶颈"。
-
数据效率提升:工业数据具有"海量、低价值密度"的特点,边缘计算通过数据过滤、特征提取等手段,将原始数据转化为"有用信息",大幅降低云端存储和计算压力,某半导体企业的测试显示,边缘预处理能使云端AI训练效率提升4-7倍。

-
系统可靠性增强:工业环境常面临网络不稳定、电力中断等问题,边缘计算的"本地自治"能力,确保了即使与云端失联,关键设备仍能正常运行,在2026年夏季的台风天气中,某化工企业的边缘控制系统在断网8小时的情况下,仍维持了95%的生产能力。
2026年的新共识:边缘与云的"分工协作"
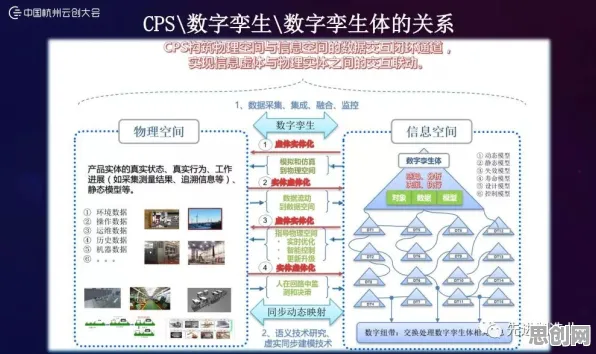
随着实践的深入,行业正在形成新的共识:数字孪生不是"云端建模"的单点突破,而是"边缘感知-边缘决策-云端优化"的闭环系统,德国弗劳恩霍夫研究所提出的"工业数字孪生金字塔"模型,清晰地展示了这种分工:
- 边缘层:负责实时数据采集、轻量级AI推理、本地控制指令生成,处理时延要求<10ms的数据;
- 近边缘层(企业私有云):承担设备级数字孪生的建模与优化,处理时延要求10-100ms的数据;
- 云端:负责跨产线、跨工厂的协同优化,处理时延要求>100ms的数据。
这种分层架构正在被越来越多企业采用,某光伏企业2026年新建的智能工厂中,边缘层处理90%的生产数据,近边缘层管理单条产线的数字孪生,云端仅负责全厂能源调度等战略决策,该厂运营总监表示:"这种架构让我们的系统响应速度提升了20倍,同时云端计算资源需求减少了70%。"
挑战仍存:边缘计算的"最后一公里"
尽管边缘计算的价值已得到验证,但2026年的调研也发现,企业在落地时仍面临三大挑战: 2026年教育公益与数字鸿沟及可持续时尚热度持续走高,行业关注度持续提升
-
2026年上半年需求响应热度持续攀升,相关领域迎来新突破 异构设备整合:工业现场存在大量老旧设备,其通信协议、数据格式各不相同,某汽车厂统计显示,其车间设备涉及23种协议,整合难度极大。
-
边缘AI模型开发:工业场景需要大量轻量化、高可靠的AI模型,但目前缺乏适合边缘设备的开发工具链,某电子