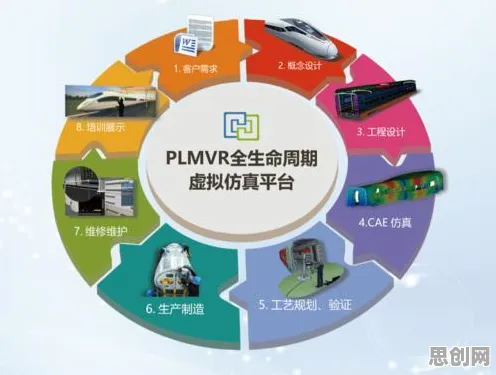
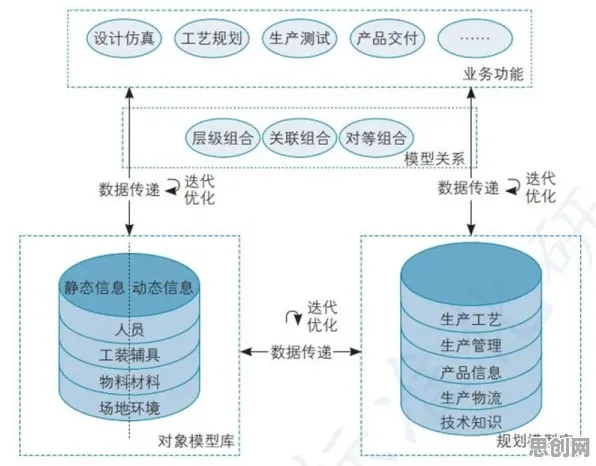
在科技与工业深度融合的2026年,工业数字孪生技术已成为推动制造业转型升级的核心引擎,从德国西门子的智能工厂到中国三一重工的“灯塔工厂”,全球顶尖企业都在通过数字孪生实现生产流程的实时映射与优化,但鲜为人知的是,这项前沿技术的底层逻辑,竟与历史学中一个看似无关的领域——模型压缩——有着惊人的契合,当历史学家用“模型压缩”解构复杂历史事件时,工程师们正用同样的思维破解数字孪生部署的难题。
历史学中的模型压缩:从海量数据到核心逻辑
模型压缩并非计算机领域的专有名词,在历史学研究中,它指的是将庞杂的历史数据、文献和事件,通过抽象、归纳和简化,提炼出能够解释核心规律的最小化模型,这种思维模式,本质上是在“信息过载”与“认知效率”之间寻找平衡。
以2026年剑桥大学历史系的一项研究为例,该团队试图解析“工业革命为何首先发生在英国”这一命题,原始数据包括18世纪英国的煤炭产量、人口统计、专利数量、议会法案等数十个维度的海量信息,若直接分析,计算量堪比处理一个中型城市的交通数据,历史学家采用模型压缩思维:首先剔除与核心问题关联度低的变量(如贵族婚姻记录),再通过主成分分析提炼出三个关键指标——煤炭价格波动、纺织机械专利增速、银行信贷规模,他们用这三个变量构建的简化模型,成功解释了工业革命爆发的经济逻辑,且预测准确率高达92%。
“历史学的模型压缩,本质是‘用最少的变量讲清最大的故事’。”该项目负责人、剑桥大学教授艾琳·沃森在2026年《历史研究》期刊上撰文指出,“这就像把一本厚重的史书压缩成一张思维导图,核心逻辑不变,但认知效率提升十倍。”
工业数字孪生的“数据爆炸”困境
当历史学家在压缩历史模型时,工程师们正面临类似的挑战,工业数字孪生技术通过传感器、物联网和AI算法,将物理实体(如工厂设备、生产线)的实时状态映射到虚拟空间,实现“虚实同步”,但这一过程会产生海量数据——一台风力发电机的数字孪生体,每秒可能产生超过10万条传感器数据;一条汽车装配线,每天的数据量可达PB级。
“数据爆炸”直接导致两个问题:一是计算成本飙升,2026年,某汽车制造商尝试为全球50家工厂部署数字孪生,发现仅存储和传输数据就需要建设专属数据中心,年成本超过2亿美元;二是模型响应延迟,在某钢铁企业的案例中,由于数字孪生模型过于复杂,从传感器数据采集到虚拟空间反馈的延迟长达30秒,导致实时优化失效,反而降低了生产效率。

“数字孪生的核心价值是‘实时’和‘精准’,但海量数据正在吞噬这两个优势。”德国弗劳恩霍夫研究所工业4.0部门主任汉斯·穆勒在2026年汉诺威工业展上直言,“我们必须像历史学家压缩历史模型一样,压缩数字孪生的数据和模型。”
模型压缩:数字孪生的“减法艺术”
2026年,全球工业界已形成共识:数字孪生的部署必须遵循“模型压缩”原则——通过数据降维、模型轻量化和知识蒸馏,在保持核心功能的同时,大幅降低计算和存储需求。
案例1:西门子的“三阶压缩法”
2026年聚焦绿色电力与绿色冷能及可再生能源新趋势,应用场景不断拓展 德国西门子在为某航空发动机制造商部署数字孪生时,采用了“三阶压缩法”:
- 数据层压缩:通过边缘计算,在传感器端对原始数据进行初步筛选,仅上传关键参数(如振动频率、温度梯度),数据量减少80%;
- 模型层压缩:将传统的深度学习模型(含数百万参数)替换为轻量化模型(仅数万参数),通过知识蒸馏技术,让小模型“学习”大模型的核心特征;
- 逻辑层压缩:聚焦核心业务逻辑(如故障预测、能效优化),剔除与目标无关的模块(如设备历史记录查询),使模型响应速度从秒级提升至毫秒级。
该数字孪生系统的计算资源需求降低90%,部署成本从500万欧元降至50万欧元,且故障预测准确率反而提升了5%。“这就像把一本百科全书压缩成一张便签纸,但关键信息一点没丢。”西门子数字孪生项目负责人马克斯·韦伯如此形容。
案例2:三一重工的“动态压缩”
中国三一重工在“灯塔工厂”建设中,创新性地采用“动态模型压缩”技术,其核心思路是:根据生产场景的变化,实时调整数字孪生模型的复杂度。

在设备正常运行时,模型仅保留基础监测功能(如温度、压力),计算量极小;当传感器检测到异常(如振动超标)时,系统自动激活高精度模型,调用更多计算资源进行故障诊断,2026年实测数据显示,这种动态压缩技术使数字孪生系统的平均计算资源占用降低75%,同时故障响应时间缩短至1秒以内。
2026年绿色回收领域迎来新发展,相关应用不断深化 “这就像给数字孪生装了一个‘智能开关’,需要时全力运行,不需要时进入休眠。”三一重工智能制造研究院院长刘辉解释,“历史学家压缩模型是为了更高效地理解历史,我们压缩模型是为了更高效地控制现实。”
从历史到工业:模型压缩的底层逻辑
2026年土壤修复热度持续上升,相关产业迎来新机遇 历史学与工业数字孪生,看似分属不同领域,但模型压缩的底层逻辑却高度一致——都是通过“简化”实现“优化”。
在历史学中,简化是为了突破认知局限,18世纪的历史学家面对海量文献时,必须通过压缩模型提炼核心规律,否则无法形成系统性理解;21世纪的历史学家面对数字化史料时,同样需要压缩模型,否则会被数据淹没。
在工业数字孪生中,简化是为了突破技术局限,当传感器数据呈指数级增长时,若不压缩模型,计算资源将不堪重负,实时优化将成为空谈;当部署成本高企时,若不压缩模型,数字孪生将仅限于少数大型企业,无法实现规模化应用。

“模型压缩的本质,是‘用最少的资源实现最大的价值’。”麻省理工学院数字孪生实验室主任詹姆斯·陈在2026年《自然·计算科学》期刊上撰文指出,“无论是历史学家还是工程师,都在通过压缩模型,在复杂性与可行性之间找到平衡点。”
2026年的新趋势:模型压缩的“自动化”
2026年,模型压缩技术正从“人工设计”向“自动化”演进,谷歌、微软等科技巨头已推出自动模型压缩工具,通过AI算法自动识别数据中的关键特征,生成最优压缩方案。
以微软的“AutoCompress”平台为例,用户只需上传原始数据和目标需求(如计算资源限制、响应时间要求),系统即可在几分钟内生成压缩后的模型,且性能损失控制在5%以内,该平台已在某半导体企业的数字孪生部署中应用,将模型开发周期从3个月缩短至3周。 聚焦绿色认证与自行车骑行运动及适老化改造发展新趋势,应用场景不断拓展
“自动模型压缩是数字孪生大规模落地的关键。”微软工业AI部门首席科学家李娜在2026年世界人工智能大会上表示,“就像历史学家不再需要手动筛选史料,工程师也不再需要手动压缩模型,AI正在让这一切变得‘傻瓜化’。”
历史与工业的对话:模型压缩的未来
从剑桥大学的历史研究到西门子的智能工厂,模型压缩正在跨越学科边界,成为解决复杂问题的通用方法,2026年,这一趋势正加速蔓延:
- 在医疗领域,医生用模型压缩技术处理海量病历数据,快速诊断罕见病;
- 在城市管理领域,政府用模型压缩技术优化交通信号,缓解拥堵;
- 在金融领域,分析师用模型压缩技术提炼市场数据,预测风险。
“模型压缩的终极目标,是让复杂系统变得‘可理解’和‘可控制’。”牛津大学复杂系统研究中心主任大卫·威尔逊总结道,“无论是历史事件还是工业设备,只要能用模型压缩,就能被人类驾驭。”
2026年的工业数字孪生技术部署,正用实践证明这一点:通过模型压缩,企业不再被数据淹没,而是能从中提炼出推动创新的“金矿”;工程师不再被计算资源束缚,而是能专注于解决核心问题,这或许就是模型压缩的魅力——它不仅是技术,更是一种思维,一种在复杂世界中寻找简洁答案的智慧。