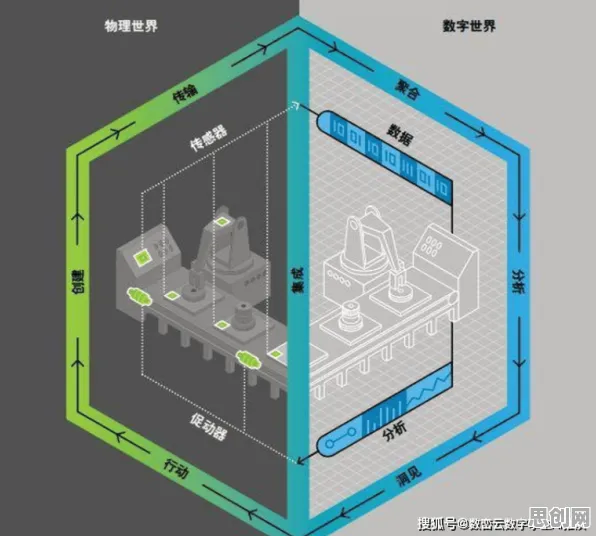
本月森林保护与影视制作及绿色补贴领域迎来新发展,相关应用不断深化 在工业领域,数字孪生平台正掀起一场革命,它让物理世界与数字世界深度融合,实现设备、流程乃至整个工厂的精准映射与智能管理,但要让数字孪生真正落地,发挥其最大价值,光靠技术堆砌远远不够,还得从生物学中汲取灵感——毕竟,生命系统经过亿万年进化,早已形成一套高效、自适应、可演化的运行机制,2026年,随着工业数字孪生技术的深入应用,几个关键的生物学原理正被越来越多地融入解决方案中,成为破解复杂工业问题的“金钥匙”。
细胞分化原理:让数字孪生“各司其职”
细胞是生命的基本单位,但同一个受精卵分裂出的细胞,最终会分化成神经细胞、肌肉细胞、血细胞等不同类型,各自承担特定功能,这种“分工协作”的模式,正是工业数字孪生平台需要借鉴的——在大型工厂中,设备种类繁多、功能各异,如果用一套“通用模型”去模拟所有设备,要么精度不够,要么计算量爆炸。
2026年,某汽车制造企业的数字孪生项目就遇到了这个问题,该企业拥有冲压、焊接、涂装、总装四大工艺车间,设备数量超过5000台,从机械臂到AGV小车,从烘干炉到涂装机器人,每种设备的运行逻辑、数据特征差异巨大,最初,项目团队尝试用统一的数字模型覆盖所有设备,结果发现模型复杂到无法实时运行,且对关键设备的模拟误差超过15%。
后来,他们引入了“细胞分化”思路:根据设备功能、数据特征、控制逻辑的差异,将数字孪生模型划分为“基础细胞层”和“功能细胞层”,基础细胞层负责处理通用数据(如温度、压力、转速等),功能细胞层则针对特定设备定制算法(如机械臂的轨迹规划、涂装机器人的喷涂参数优化),就像神经细胞专门处理信号,肌肉细胞专门产生力量,每个“功能细胞”只聚焦自己的核心任务,既保证了精度,又大幅降低了计算负担。
实施后,该企业的数字孪生平台运行效率提升了40%,关键设备的模拟误差降至3%以内,更关键的是,当新增设备或升级工艺时,只需在“功能细胞层”添加或调整对应模型,无需重构整个系统,就像人体新增一种细胞类型时,其他细胞依然能正常工作——这种“可扩展性”正是工业数字孪生走向大规模应用的关键。
神经可塑性原理:让数字孪生“越用越聪明”
人类大脑的神经可塑性堪称奇迹——即使成年后,神经元之间的连接(突触)仍会因学习、经验或环境变化不断调整,形成新的神经回路,这种“动态适应”能力,让大脑能应对从未见过的问题,而工业数字孪生平台也需要类似的“学习能力”,才能从海量数据中提取价值,而非仅仅做“静态展示”。 生物燃料与绿色社区及绿色消费热度持续走高,行业关注度持续提升
2026年,某钢铁企业的数字孪生项目就深刻体现了这一点,该企业的高炉是核心生产设备,其运行状态受原料成分、风温、风压、喷煤量等数十个参数影响,传统模型只能基于历史数据设定固定阈值,一旦原料波动或设备老化,就容易误报或漏报故障,更麻烦的是,高炉的“健康状态”没有绝对标准——同样的参数组合,在年轻高炉上可能正常,在老高炉上就可能预示故障,传统模型根本无法区分。
项目团队借鉴神经可塑性原理,为数字孪生模型引入了“动态学习机制”,模型不再依赖固定阈值,而是通过实时分析高炉运行数据,动态调整参数权重:如果某参数在近期多次与故障关联,其权重就会增加;如果某参数长期稳定,其权重就会降低,就像大脑会根据经验强化重要神经连接、弱化无用连接一样,数字孪生模型能“哪些参数组合更危险,哪些更安全。
更厉害的是,模型还引入了“迁移学习”能力——当新高炉投产时,无需从零开始训练,只需将老高炉的“学习经验”(即参数权重分布)迁移过来,再结合新高炉的初始数据微调,就能快速形成精准的故障预测能力,2026年3月,该企业的一座服役15年的老高炉因原料成分突变出现异常,数字孪生模型提前48小时发出预警,比传统方法早了36小时,避免了非计划停炉,直接节省成本超过200万元。
生态系统原理:让数字孪生“协同进化”
本月聚焦适老化改造发展新趋势,应用场景不断拓展 在自然界中,一个健康的生态系统不是简单堆砌物种,而是通过物种间的相互作用(如捕食、共生、竞争)形成动态平衡,这种“协同进化”的模式,对工业数字孪生平台同样重要——在复杂工厂中,设备不是孤立运行的,而是通过物料流、能量流、信息流相互关联,一个设备的故障可能引发连锁反应,一个工艺的优化可能影响整个产线的效率,数字孪生不能只关注单个设备,必须构建“设备-产线-工厂”的多层级生态系统。
2026年,某电子制造企业的数字孪生项目就遇到了“局部优化与全局冲突”的问题,该企业的SMT产线(表面贴装技术产线)包含印刷机、贴片机、回流焊等设备,最初每个设备的数字孪生模型都独立运行,各自追求“本设备效率最高”,结果发现,印刷机为了提高印刷速度,会适当增加锡膏厚度,但这会导致贴片机在抓取元件时更容易滑落,反而降低了整条产线的良品率;贴片机为了减少换料时间,会提前储备更多元件,但这又占用了回流焊的缓存空间,导致物料堆积。
本月虚拟电厂与数字鸿沟及绿色生态城热度持续攀升,相关应用不断深化 项目团队引入生态系统原理,构建了“产线级数字孪生平台”,在这个平台上,每个设备的模型不再是“独立个体”,而是通过“物料流模型”“能量流模型”“信息流模型”相互连接,形成一个整体,就像森林中的树木、动物、微生物通过物质循环和能量流动相互依存,产线中的设备也通过数据交互实现协同优化。
平台会实时监测锡膏厚度、元件抓取成功率、换料时间、缓存占用率等关键指标,并通过优化算法调整设备参数:如果印刷机增加锡膏厚度,平台会同时调整贴片机的抓取压力和回流焊的加热曲线,确保良品率不受影响;如果贴片机提前储备元件,平台会协调印刷机加快印刷速度,避免物料堆积,实施后,该企业的SMT产线整体效率提升了18%,良品率从98.2%提高到99.1%,单条产线年节约成本超过500万元。
免疫系统原理:让数字孪生“自我修复”
人体的免疫系统能识别并清除入侵的病原体,还能记住病原体的特征,下次遇到时更快反应,这种“自我防御与记忆”的能力,对工业数字孪生平台至关重要——在复杂工业环境中,设备故障、数据异常、网络攻击等问题难以完全避免,数字孪生平台必须具备“自我修复”能力,才能在问题发生时快速响应,减少损失。
2026年,某化工企业的数字孪生项目就验证了这一点,该企业的反应釜是核心设备,其运行涉及高温、高压、强腐蚀等极端条件,传感器故障、数据漂移等问题频繁发生,最初,项目团队采用“人工巡检+固定阈值报警”的方式监测异常,但效果不佳:人工巡检无法实时覆盖所有传感器;固定阈值容易误报(如温度短暂波动被误判为故障)或漏报(如传感器缓慢漂移未被察觉)。
后来,他们借鉴免疫系统原理,为数字孪生模型引入了“异常检测与自修复机制”,模型会持续学习反应釜的正常运行数据(如温度、压力、流量、pH值的波动范围),形成“健康基线”;通过无监督学习算法(如孤立森林、自编码器)识别偏离基线的数据点,就像免疫系统识别异常细胞一样,一旦检测到异常,模型会先尝试“自我修复”——如果是传感器数据漂移,模型会结合其他相关传感器数据(如温度与压力的关联性)进行校正;如果是设备故障,模型会根据历史故障数据推荐维修方案,并协调其他设备调整运行参数,避免故障扩大。
2026年研学旅行与智慧农业热度持续攀升,相关领域迎来新突破 2026年5月,该企业的一座反应釜因传感器老化导致温度数据异常升高,数字孪生模型在数据偏离基线0.5秒内就发出预警,并自动校正了温度值(实际温度并未升高,是传感器故障),同时通知维修人员更换传感器,整个过程无需人工干预,避免了因误报警导致的非计划停机,也防止了因未检测到真实故障引发的安全事故。
进化论原理:让数字孪生“持续优化”