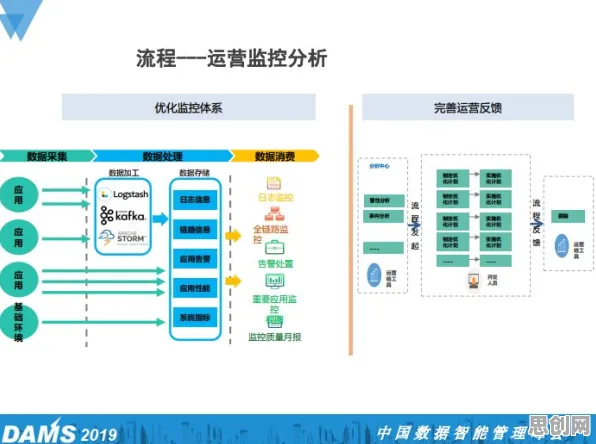
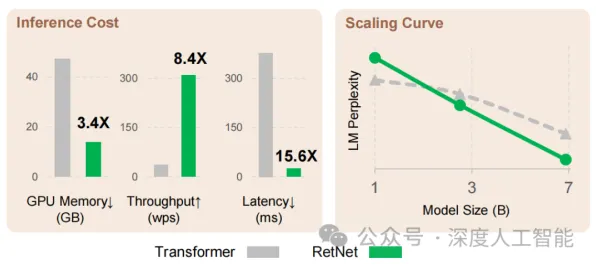
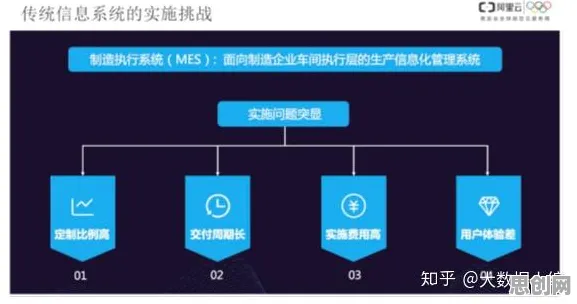
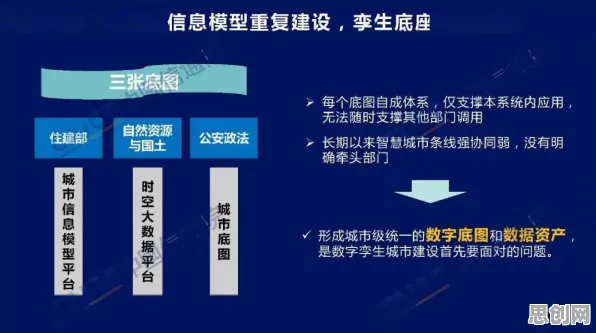
新型电池与绿色产品链及绿色消费圈持续升温,技术创新带来新突破 2026年的科技圈,大模型竞争的硝烟弥漫得愈发浓烈,从硅谷到中关村,从跨国科技巨头到新兴创业公司,所有人都在谈论大模型的参数规模、训练数据量、算力投入,仿佛这些才是决定胜负的关键,但当我们拨开这层热闹的表象,会发现一个被严重忽视的事实:大多数人对大模型竞争加剧的理解,其实都错了,真正决定这场竞争走向的,不是头部玩家的“军备竞赛”,而是长尾理论下那些看似微不足道却蕴含巨大能量的细分场景。
头部竞争的“虚假繁荣”
先来看看头部大模型玩家们的“盛况”,2026年初,全球科技媒体的头条几乎被几家巨头的动态占据:OpenAI推出了GPT-6,参数规模突破10万亿,训练数据涵盖了过去50年的全球新闻、学术论文和社交媒体内容;谷歌不甘示弱,发布了Gemini Ultra 2.0,号称在多模态理解上实现了质的飞跃,能同时处理文本、图像、音频和视频,且准确率达到99.9%;国内的百度、阿里、腾讯也纷纷加码,百度文心大模型5.0在中文语境下的语义理解能力达到新高度,阿里通义千问则在企业服务领域深耕,推出了针对金融、医疗、制造等行业的定制化解决方案。
这些消息听起来确实振奋人心,仿佛大模型已经进入了“超级智能”时代,但当我们深入到实际应用场景中,会发现一个尴尬的现实:这些头部大模型虽然能力强大,但真正能落地并产生实际价值的场景却非常有限,以GPT-6为例,尽管它能生成高质量的文本、回答复杂的问题,但在大多数企业的日常运营中,真正需要的不是“通用型”的智能,而是能解决特定问题的“专用型”工具,一家制造企业可能更需要一个能分析生产数据、预测设备故障、优化供应链的大模型,而不是一个能写诗、画画的“全能选手”。
同样的问题也出现在谷歌的Gemini Ultra 2.0上,虽然它在多模态理解上表现出色,但在实际应用中,企业往往只需要处理单一模态的数据,比如文本或图像,多模态能力的冗余不仅增加了企业的使用成本,还带来了数据安全和隐私方面的风险,一位制造业的CTO在接受《财经》杂志采访时直言:“我们不需要一个能同时处理文本、图像、音频和视频的大模型,我们只需要一个能专注解决生产问题的‘小模型’。”
长尾理论的崛起:细分场景的“隐形冠军”
与头部玩家的“虚假繁荣”形成鲜明对比的是,长尾理论下那些专注于细分场景的大模型正在悄然崛起,长尾理论由《连线》杂志主编克里斯·安德森提出,核心观点是:在互联网时代,由于存储和流通成本的降低,那些原本被忽视的“小众”需求(即长尾需求)加起来,其市场总量可以与主流需求(即头部需求)相媲美,甚至超过主流需求。
在大模型领域,这一理论同样适用,2026年,我们看到了越来越多专注于细分场景的大模型涌现,它们或许参数规模不大,训练数据量有限,但在特定领域却表现出色,甚至超越了头部大模型。
医疗领域的“专科医生”
以医疗领域为例,2026年,一家名为“医智云”的创业公司推出了一款专注于眼科疾病诊断的大模型“EyeDoc”,与通用型大模型不同,“EyeDoc”的训练数据全部来自眼科领域的专业文献、临床病例和影像资料,其参数规模只有100亿左右,但在眼科疾病的诊断准确率上却达到了98%,超过了大多数通用型大模型。
“EyeDoc”的成功并非偶然,眼科是一个高度专业化的领域,涉及大量的专业术语和影像数据,通用型大模型虽然能处理文本和图像,但在眼科领域的专业知识和经验上却远远不足,而“EyeDoc”通过聚焦眼科这一细分场景,深入挖掘专业数据,构建了专门的知识图谱和算法模型,从而实现了精准诊断。
一家三甲医院的眼科主任在试用“EyeDoc”后表示:“这个模型就像一个经验丰富的眼科医生,能快速准确地诊断出各种眼科疾病,甚至能发现一些我们医生容易忽略的细节,对于基层医院来说,这无疑是一个巨大的帮助。”
农业领域的“智能管家”
农业是另一个长尾理论发挥作用的领域,2026年,一家名为“农智通”的创业公司推出了一款专注于农业种植管理的大模型“AgriMaster”,与通用型大模型不同,“AgriMaster”的训练数据全部来自农业领域的传感器数据、气象数据、土壤数据和作物生长数据,其参数规模只有50亿左右,但在农业种植管理的精准度上却达到了新高度。
“AgriMaster”能根据土壤湿度、温度、光照等环境参数,以及作物的生长阶段和需求,自动调整灌溉、施肥和病虫害防治策略,一家大型农业合作社的负责人表示:“以前我们种地主要靠经验,现在有了‘AgriMaster’,就像有了一个智能管家,能帮我们科学决策,提高产量,降低成本,去年我们的水稻产量提高了15%,成本降低了10%。”
教育领域的“个性化导师”
教育领域也是长尾理论的重要应用场景,2026年,一家名为“学智云”的创业公司推出了一款专注于个性化教育的大模型“EduTutor”,与通用型大模型不同,“EduTutor”的训练数据全部来自学生的学习行为数据、成绩数据和兴趣数据,其参数规模只有30亿左右,但在个性化教育方面却表现出色。
“EduTutor”能根据学生的学习进度、知识掌握情况和兴趣偏好,自动生成个性化的学习计划和练习题,一位使用“EduTutor”的学生家长表示:“这个模型就像一个私人导师,能根据孩子的实际情况制定学习计划,还能及时反馈学习效果,自从用了‘EduTutor’,孩子的学习兴趣明显提高,成绩也进步了不少。”
头部玩家的“觉醒”:从通用到专用的转型
面对长尾理论下细分场景大模型的崛起,头部玩家们也开始意识到问题的严重性,2026年下半年,我们看到了头部玩家们纷纷调整战略,从追求“通用型”大模型转向开发“专用型”大模型。
绿色热力热度持续上升,相关产业迎来新发展 OpenAI在推出GPT-6后不久,就宣布将开放GPT-6的微调接口,允许企业和开发者根据自己的需求对模型进行定制化训练,谷歌也紧随其后,推出了Gemini Ultra 2.0的行业版,针对金融、医疗、制造等行业提供了预训练的专用模型,国内的百度、阿里、腾讯也纷纷推出了自己的行业大模型,如百度的“文心行业版”、阿里的“通义行业版”和腾讯的“混元行业版”。
本月需求响应热度飙升,相关产业迎来新机遇 这些头部玩家的转型并非偶然,细分场景大模型的崛起让他们意识到,通用型大模型虽然能力强大,但无法满足所有场景的需求;随着大模型技术的成熟和开源社区的发展,开发专用型大模型的技术门槛和成本逐渐降低,头部玩家们有能力也有必要进入这一市场。
一位OpenAI的高管在接受《纽约时报》采访时表示:“我们意识到,大模型的未来不在于‘大’,而在于‘专’,只有深入到具体场景中,解决实际问题,才能真正发挥大模型的价值。”
长尾理论的挑战:数据、算力和生态
尽管长尾理论下细分场景大模型展现出了巨大的潜力,但要真正实现规模化应用,还面临着诸多挑战。
数据获取与标注
细分场景大模型的成功离不开高质量的专业数据,这些数据往往分散在各个行业和企业中,获取难度大,标注成本高,以医疗领域为例,虽然医院有大量的临床病例和影像数据,但这些数据往往涉及患者隐私,获取和使用需要严格的审批流程,医疗数据的标注需要专业的医生参与,成本高昂。
算力需求
虽然细分场景大模型的参数规模相对较小,但在训练和推理过程中仍然需要大量的算力支持,尤其是对于一些实时性要求高的场景,如自动驾驶、工业控制等,对算力的要求更高,如何降低算力成本,提高算力效率,是细分场景大模型面临的重要挑战。
生态建设
2026年短视频营销与绿色售后链及文旅融合热度持续攀升,相关应用不断深化 细分场景大模型的成功不仅取决于模型本身的能力,还取决于其能否与现有的行业生态融合,在医疗领域,大模型需要与医院的HIS系统、PACS系统等对接;在农业领域,大模型需要与传感器、无人机、智能农机等设备联动,如何构建开放、协同的生态系统,是细分场景大模型发展的关键。
长尾理论下的未来展望
2026年的大模型竞争,已经不再是头部玩家的“独角戏”,而是长尾理论下细分场景的“群雄逐鹿”,从医疗到农业,从教育到制造,越来越多的细分场景正在被大模型赋能,越来越多的“隐形冠军”正在崛起。
对于头部玩家来说,从通用到专用的转型不仅是战略调整,更是生存之道,只有深入到具体场景中,解决实际问题,才能真正发挥大模型的价值,避免被市场淘汰。
对于创业公司来说,细分场景大模型提供了一个“弯道超车”的机会,通过聚焦特定领域,深入挖掘专业数据,构建专用模型,创业公司有望在