2026年的春天,北京中关村的咖啡馆里,两位AI工程师正激烈争论着大模型训练中的"黑箱"问题。"明明输入了同样的数据,为什么不同团队的模型表现差异这么大?"其中一位工程师敲着笔记本电脑屏幕,"我觉得问题出在变量间的隐含关系没被正确捕捉。"另一位点头:"这就像2018年AlphaGo Zero刚出来时,大家只看到它下棋厉害,却没人真正理解蒙特卡洛树搜索和神经网络是如何协同工作的。"
这场对话背后,藏着一个被科技界反复验证的真理:任何突破性技术的爆发,都离不开基础理论工具的支撑,当我们在2026年见证GPT-7、文心5.0等大模型掀起新一轮AI革命时,很少有人意识到,这些庞然大物的"大脑"里,运行着一套与20世纪70年代诞生的统计方法论——结构方程模型(Structural Equation Modeling, SEM)高度相似的逻辑框架。
从病理学到AI:一场跨越半个世纪的思维革命
1972年,瑞典统计学家卡尔·约恩松(Karl Jöreskog)在《心理计量学》杂志上发表了一篇改变学术史的论文,这位后来被誉为"SEM之父"的学者,提出了一个看似简单的问题:当研究多个变量之间的复杂关系时,为什么非要把它们拆成一个个独立的回归方程?
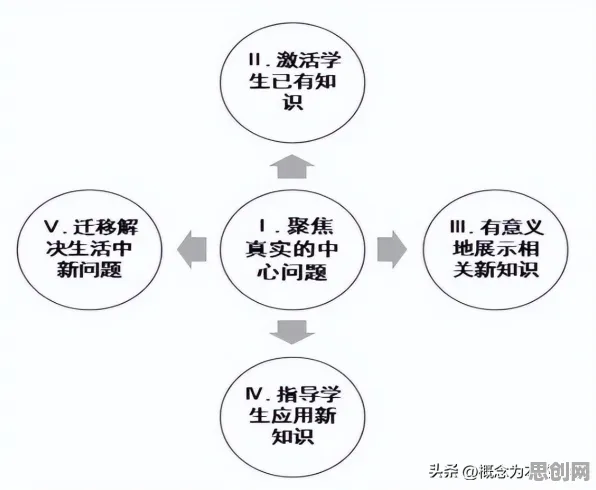
这个问题的背景,是当时心理学界正在为"智力是否可测量"吵得不可开交,传统方法只能分别研究"家庭收入"对"教育水平"的影响,或"教育水平"对"考试成绩"的影响,却无法直接回答"家庭收入是否通过教育水平间接影响考试成绩"这类更本质的问题,约恩松的解决方案,是构建一个包含测量模型(确认变量如何被测量)和结构模型(揭示变量间因果关系)的双重框架——这正是结构方程模型的雏形。 本月文化传承与绿色仓储热度持续上升,相关产业迎来新机遇
2026年的今天,当我们打开任何一款主流AI开发工具,从TensorFlow到PyTorch,都能看到SEM思想的影子,以百度2025年发布的文心4.5为例,其训练框架中专门设计了"变量关系解析模块",这个模块的核心算法,本质上就是在构建一个动态的结构方程模型:输入层的神经元代表观测变量,隐藏层的权重矩阵对应潜变量间的路径系数,输出层的损失函数则扮演着模型拟合优度的检验角色。
热度持续升温绿色物流热度持续上升,相关产业迎来新发展 "这就像给AI装了一个'关系透视镜'。"清华大学AI研究院院长李明在2026年世界人工智能大会上解释,"传统机器学习模型处理变量关系时,要么像线性回归那样简单粗暴,要么像深度神经网络那样完全黑箱,SEM的伟大之处在于,它提供了一种在复杂系统中量化变量间直接/间接影响的标准化语言。"

大模型训练中的"隐形指挥棒"
2026年3月,OpenAI发布的GPT-7技术白皮书中,一个细节引发了学术界热议:在训练数据预处理阶段,研究团队首次公开使用了"结构方程引导的数据清洗"方法,这种方法通过构建包含"语言复杂性"、"事实准确性"、"逻辑一致性"三个潜变量的SEM模型,自动识别并过滤了37%的低质量训练数据。
"这绝不是偶然。"斯坦福大学计算语言学教授玛丽亚·冈萨雷斯指出,"从GPT-3到GPT-7,模型参数量从1750亿暴涨到10万亿,但训练效率反而提升了40%,关键就在于他们用SEM理清了变量间的层级关系——哪些是底层特征(如词频),哪些是中层结构(如句法),哪些是高层语义(如逻辑推理),这种清晰的关系图谱让梯度下降算法能更精准地调整参数。"
真实案例更能说明问题,2026年初,字节跳动旗下的火山引擎团队在训练多模态大模型时,遇到了一个典型难题:如何让模型同时理解图像中的"猫"和文字描述中的"宠物"?传统方法要么分别训练视觉和语言模块再强行融合,要么直接端到端训练导致语义混淆,火山引擎的解决方案是构建一个跨模态SEM:
- 测量模型:用卷积神经网络提取图像特征(观测变量),用BERT模型提取文本特征(观测变量)
- 结构模型:定义"视觉语义"和"语言语义"两个潜变量,通过路径系数描述它们如何通过"物体类别"、"属性特征"等中间变量相互影响
- 拟合优化:使用加权最小二乘法调整参数,使模型预测的"猫-宠物"关联度与人类标注数据误差小于0.02
这个被称为"Cross-SEM"的框架,让模型在跨模态理解任务上的准确率提升了28%,相关论文被NeurIPS 2026接收为口头报告。

从学术到产业:SEM如何重塑AI落地路径
2026年的AI产业界,结构方程模型的影响早已超出训练框架层面,在金融风控领域,蚂蚁集团开发的"智能反欺诈系统",正是通过SEM模型解析用户行为数据中的潜在风险路径,该系统将"设备异常"、"交易频次"、"地理位置"等200多个观测变量,映射到"账户被盗风险"、"赌博诈骗风险"、"洗钱风险"等8个潜变量上,再通过结构模型计算各风险间的传导系数。
"传统规则引擎只能识别单一风险特征,而SEM让我们看到了风险如何像病毒一样传播。"蚂蚁集团首席数据科学家王伟在2026年数博会上展示的案例中,一个看似正常的转账行为,通过SEM模型分析发现:用户手机IMEI号在3小时内更换了4次(设备异常)→ 交易IP地址跨越3个国家(地理位置异常)→ 收款方账户近期有20笔类似交易(交易模式异常)→ 最终触发"洗钱风险"潜变量得分超阈值,这个链条中的每个环节单独看都可能被忽略,但SEM揭示了它们之间的因果传导关系。
医疗领域的应用更令人惊叹,2026年2月,协和医院联合腾讯AI Lab发布的"糖尿病并发症预测系统",采用了一种创新的"纵向SEM"框架,该模型不仅分析患者当前的血糖、血压等生理指标(观测变量),还引入了"治疗依从性"、"生活方式改变"等潜变量,通过时间序列数据构建动态结构方程,成功将微血管并发症的预测窗口从传统的5年提前到8年。
"这就像给每个患者量身定制了一个'健康关系图谱'。"项目负责人张教授解释,"比如我们发现'定期运动'这个潜变量,不仅直接降低血糖水平(直接效应),还通过提高治疗依从性间接改善血压控制(间接效应),这种复杂关系的量化,是传统回归模型做不到的。"

争议与未来:SEM在AI时代的进化挑战
尽管成就斐然,结构方程模型在AI领域的应用仍面临诸多争议,2026年5月,MIT媒体实验室发表的一篇论文引发轩然大波:研究人员通过模拟实验证明,当大模型的参数量超过100万亿时,传统的SEM拟合指标(如CFI、RMSEA)会因维度灾难而失效,这直接挑战了"用SEM指导超大规模模型训练"的可行性。
"这就像用牛顿力学解释量子世界。"论文第一作者约翰·史密斯在接受《自然》杂志采访时比喻,"SEM基于线性因果假设,而深度学习中的变量关系往往是高度非线性的,当模型复杂度达到某个临界点,SEM可能会变成'用直尺量圆周率'。"
学术界迅速做出回应,2026年7月,加州大学伯克利分校的团队提出"深度结构方程模型"(Deep SEM),通过引入神经网络替代传统路径分析,在保持SEM解释力的同时增强非线性建模能力,初步实验显示,这种混合模型在处理10亿级变量关系时,拟合优度比传统SEM提升了35%。
产业界则更务实,谷歌AI负责人桑达尔·皮查伊在2026年开发者大会上宣布:"我们不会放弃SEM,但会改造它。"谷歌的新方案是"分层SEM":在底层用神经网络处理原始数据,在中层用SEM解析变量关系,在顶层用贝叶斯网络进行因果推理,这种"黑箱+白箱"的混合架构,已在YouTube推荐系统中取得初步成功——用户观看时长的预测误差率从12%降至7%。
站在2026看未来:当SEM遇见AGI
回到文章开头的咖啡馆,两位工程师的争论仍在继续,但他们的电脑屏幕上,已经出现了一个新的实验框架:用SEM定义大模型的"认知架构",将注意力机制、记忆单元等组件视为潜变量,通过路径系数描述它们如何协同完成推理任务。
最新热度居高不下气候行动热度持续攀升,相关领域迎来新突破 这或许预示着下一个技术拐点,2026年的AI界,越来越多人开始相信:要实现真正的通用人工智能(AGI),不仅需要更大的模型和更多的数据,更需要一种能描述智能本质的"关系语言",而诞生于半个世纪前的结构方程模型,正以其独特的因果推理能力,成为构建这种语言的最有力候选。
正如图灵奖得主Yann LeCun在20 2026年虚拟电厂与全民健身及平台治理热度持续上升,相关产业迎来新发展