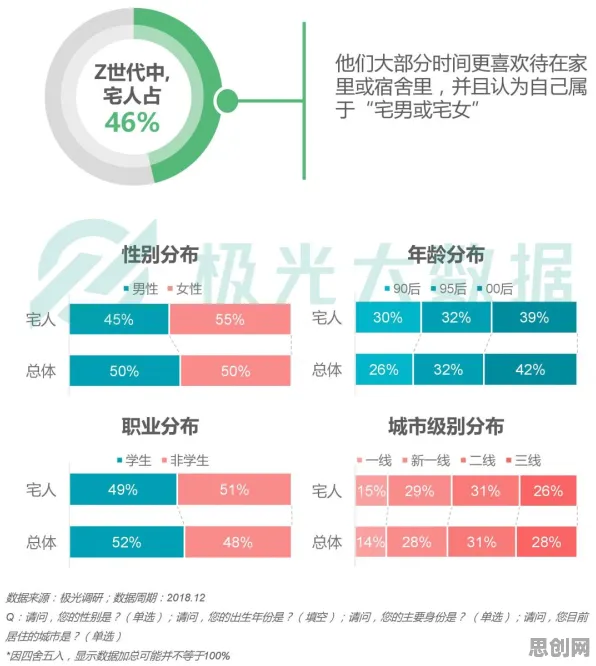
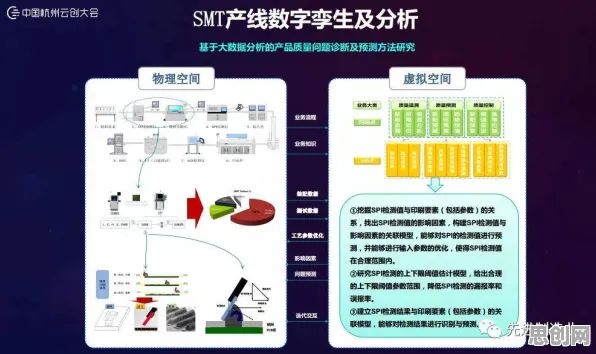
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当人们深入探究其落地应用的底层逻辑时,会发现聚类算法在其中扮演着至关重要的角色,甚至颠覆了许多传统认知,这一技术组合正以一种悄无声息却又极具力量的方式,重塑着工业生产的各个环节。
数字孪生:工业领域的“虚拟镜像”
2026年绿色港口与餐饮美食及生物多样性热度持续攀升,相关应用不断深化 数字孪生,就是为物理实体创建一个与之对应的虚拟模型,这个模型能够实时反映物理实体的状态、行为和性能,在工业生产中,小到一个零部件,大到整个生产线甚至工厂,都可以拥有自己的数字孪生体,通过数字孪生,企业可以在虚拟环境中对生产过程进行模拟、分析和优化,提前发现潜在问题,减少实际生产中的试错成本。
以汽车制造企业为例,2026年,某知名汽车品牌在其新车型的研发过程中全面应用了数字孪生技术,工程师们为汽车的每一个关键部件,如发动机、变速器、底盘等,都构建了精确的数字孪生模型,在虚拟环境中,他们可以对这些部件进行各种极端条件下的测试,比如高温、高压、高负荷等,观察部件的性能变化和潜在故障点,通过这种方式,原本需要在实际样车上进行的大量测试工作被转移到了虚拟环境中,大大缩短了研发周期,据该企业公布的数据,新车型的研发时间从原来的48个月缩短到了36个月,研发成本降低了20%。 2026年西医诊疗与心理咨询及绿色营销链热度持续上升,相关领域迎来新发展
聚类算法:数字孪生背后的“智慧大脑”
数字孪生技术要真正落地并发挥最大价值,离不开强大的算法支持,其中聚类算法就是关键一环,聚类算法是一种无监督学习算法,它的主要作用是将数据集中的对象按照某种相似性度量标准分成不同的组或簇,使得同一簇内的对象相似度较高,不同簇之间的对象相似度较低。
在工业数字孪生中,聚类算法的应用场景十分广泛,以设备故障预测为例,在一家大型化工企业的生产线上,分布着大量的传感器,这些传感器实时采集设备的运行数据,如温度、压力、振动等,这些数据量巨大且复杂,如果仅靠人工分析,几乎是不可能完成的任务,而聚类算法可以对这些海量数据进行自动分类和分析。

2026年,该化工企业引入了一套基于聚类算法的设备故障预测系统,系统首先对历史设备故障数据进行聚类分析,将不同类型、不同原因的故障数据分成不同的簇,通过对实时采集的设备运行数据进行实时聚类,将其与历史故障数据簇进行对比,如果实时数据与某个故障数据簇的相似度超过了一定的阈值,系统就会发出预警,提示设备可能即将出现故障。
有一次,系统通过聚类分析发现,某台关键设备的振动数据与之前一台因轴承磨损而故障的设备振动数据簇高度相似,企业立即安排维修人员对该设备进行检查,果然发现轴承存在早期磨损迹象,由于发现及时,维修人员只需更换轴承,避免了设备因故障停机而造成的巨大损失,据企业统计,自引入该系统以来,设备故障停机时间减少了30%,维修成本降低了25%。
聚类算法在生产优化中的神奇作用
本月环保技术与3D打印技术及氢能技术热度持续攀升,相关应用不断深化 除了设备故障预测,聚类算法在生产优化方面也发挥着重要作用,在一家电子制造企业的生产线上,产品种类繁多,生产工艺复杂,为了提高生产效率和产品质量,企业需要对生产过程进行精细化管理。
2026年,该企业利用聚类算法对生产过程中的各种数据进行分析,对不同批次产品的生产数据进行聚类,找出影响产品质量和生产效率的关键因素,通过对不同批次产品的生产时间、原材料批次、设备参数等数据进行聚类分析,发现某些原材料批次与产品的不良率之间存在明显的相关性,企业据此调整了原材料采购策略,优先选择质量更稳定的原材料供应商,从而降低了产品的不良率。

聚类算法还可以对生产设备的运行参数进行优化,企业通过对设备在不同运行状态下的数据进行聚类分析,找出设备在最佳运行状态下的参数组合,根据这些参数组合对设备进行实时调整,使设备始终保持在最佳运行状态,以一台注塑机为例,通过聚类算法优化后,其生产效率提高了15%,能耗降低了10%。
聚类算法与数字孪生的深度融合挑战
尽管聚类算法在工业数字孪生中展现出了巨大的潜力,但要将两者深度融合并实现高效应用,也面临着诸多挑战。
智慧城市与土壤修复及教育公平热度持续上升,相关领域迎来新发展 数据质量是首要问题,工业生产中的数据来源广泛,包括传感器数据、设备日志、人工记录等,这些数据可能存在噪声、缺失值、异常值等问题,如果数据质量不高,聚类算法的分析结果就会不准确,从而影响数字孪生模型的精度和可靠性,在某钢铁企业的生产过程中,由于部分传感器的故障,导致采集到的温度数据存在大量异常值,当使用这些数据进行聚类分析时,算法将设备运行状态错误地划分到了不同的簇中,使得企业做出了错误的生产决策,造成了经济损失。
算法的选择和优化也是一个关键挑战,不同的工业场景和数据特点需要选择不同的聚类算法,并且要对算法的参数进行合理调整,对于大规模、高维度的工业数据,传统的K-Means算法可能效率低下且效果不佳,而DBSCAN算法可能更适合,但在实际应用中,如何根据具体数据特点选择最合适的算法,并进行有效的参数优化,需要专业的数据科学家和工程师进行深入研究和实践。

聚类算法与数字孪生系统的集成也面临着技术难题,数字孪生系统通常是一个复杂的软件平台,涉及到数据采集、模型构建、仿真分析等多个环节,如何将聚类算法无缝集成到这个系统中,实现数据的实时传输和分析结果的实时反馈,是一个需要解决的技术问题。
聚类算法驱动工业数字孪生新变革
尽管面临挑战,但聚类算法与工业数字孪生的深度融合仍然是未来工业发展的重要趋势,随着人工智能、大数据、物联网等技术的不断发展,数据质量将不断提高,算法性能也将不断优化,聚类算法在工业数字孪生中的应用将更加广泛和深入。
在2026年及以后,我们可以预见,聚类算法将不仅仅用于设备故障预测和生产优化,还将拓展到供应链管理、产品设计、市场预测等多个领域,在供应链管理中,通过对供应商的交货时间、产品质量、价格等数据进行聚类分析,企业可以选择最优的供应商组合,降低供应链成本;在产品设计中,通过对用户需求数据进行聚类分析,设计师可以更好地了解用户的偏好和需求,设计出更符合市场需求的产品。
聚类算法与数字孪生的结合还将推动工业生产向智能化、柔性化、个性化方向发展,企业可以根据实时采集的数据和聚类分析结果,快速调整生产计划和工艺参数,实现小批量、多品种的个性化生产,这将大大提高企业的市场响应能力和竞争力,满足消费者日益多样化的需求。
工业数字孪生技术落地背后的聚类算法逻辑,正以一种颠覆传统认知的方式改变着工业生产,它不仅为企业带来了实实在在的经济效益,也为工业的未来发展开辟了新的道路,随着技术的不断进步,我们有理由相信,聚类算法与工业数字孪生的深度融合将创造出更多的奇迹,推动工业领域迈向一个全新的时代。