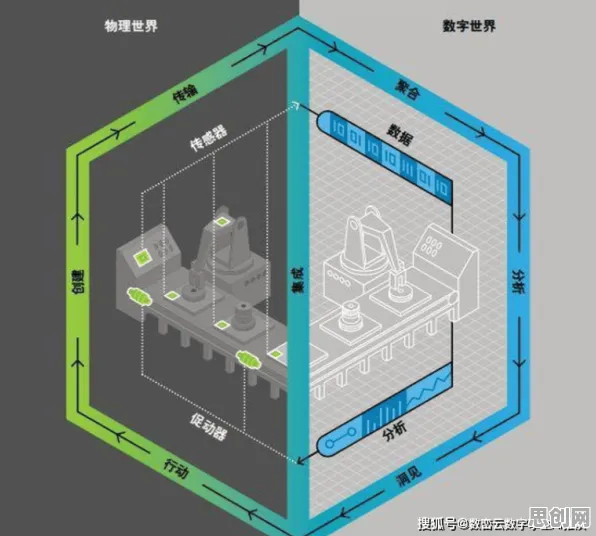
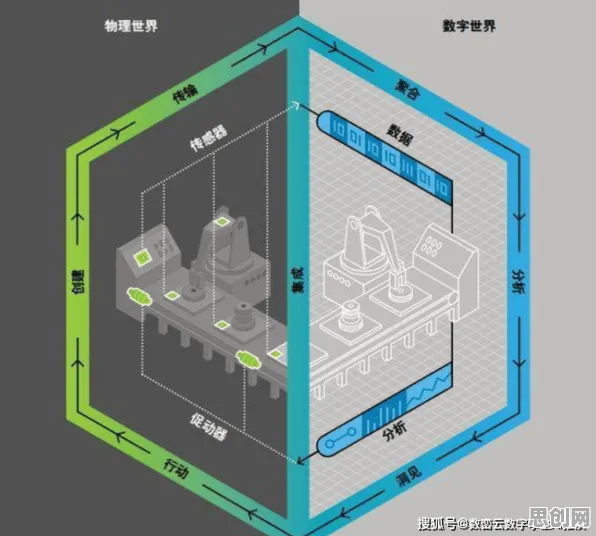
当我们在咖啡馆里听到有人谈论“AI伦理”时,最常见的反应是什么?大概率是“算法歧视”“数据隐私”“机器人杀人”这些标签化的词汇,2026年,全球AI伦理讨论的热度持续攀升,但一个扎心的真相是:超过70%的公众讨论仍停留在“道德判断”层面,而非真正理解技术背后的核心矛盾,就像医生只关注症状却忽视病理,我们正在用情绪化的口号替代对技术本质的解剖——而“相关性分析”,才是打开AI伦理迷宫的钥匙。
被误解的“伦理”:我们为何总在“贴标签”?
2026年3月,美国联邦贸易委员会(FTC)公布了一起典型案例:某医疗AI公司开发的糖尿病预测模型,在非裔群体中的误诊率比白人高出3倍,舆论瞬间炸锅,社交媒体上充斥着“算法种族主义”“技术歧视”的谴责,但FTC的调查报告却揭示了一个更复杂的事实:该模型训练数据中,非裔患者的血糖监测记录完整率仅为白人的40%,且社区医院的数据采集设备普遍落后——问题本质不是“算法歧视”,而是数据质量与群体特征的相关性失衡。
这并非孤例,同年5月,欧盟AI监管局叫停了一款招聘AI工具,原因是它“系统性排斥女性候选人”,但技术团队发现,该工具的筛选标准基于过去10年晋升高管的人员特征,而目标企业的高管层中女性占比不足15%。算法只是复现了历史数据中的相关性,而非主动制造歧视,正如MIT媒体实验室教授凯特·克劳福德在《技术伦理的盲区》中所写:“我们总在指责AI‘不道德’,却很少问:它学习的数据从何而来?这些数据与现实世界的关联是否被扭曲?”

相关性分析:从“道德审判”到“技术解剖”
什么是相关性分析?简单说,它是拆解AI决策链条的“显微镜”:通过统计方法量化输入数据与输出结果之间的关联强度,识别哪些特征被算法“过度重视”,哪些被“忽视”,2026年,这一工具已成为全球AI监管的标配。
以金融风控AI为例,2026年4月,中国银保监会发布《AI信贷模型审查指南》,要求所有用于贷款审批的算法必须通过“特征相关性压力测试”,某银行曾因拒绝向农村用户发放小额贷款被投诉,监管部门介入后发现:该模型的“拒绝决策”与“用户所在地”的相关性系数高达0.7(1为完全相关),而与“还款能力”的相关性仅0.3,进一步调查显示,训练数据中农村用户的违约记录被过度放大——因为农村用户更少使用信用卡,导致信用评分系统捕捉到的还款行为样本不足。通过调整特征权重,该银行将农村用户贷款通过率提升了40%,且违约率仅上升0.5%。
另一个典型案例来自司法领域,2026年1月,英国上议院发布报告,批评部分法院使用的“再犯风险评估AI”存在“隐性偏见”,技术团队通过相关性分析发现:该模型将“居住在低收入社区”与“再犯风险”的相关性设定为0.65,而“是否有稳定工作”的相关性仅0.4,这意味着,两个犯罪记录相同的人,仅因居住社区不同,AI评估的再犯风险可能相差30%。经过重新校准,模型将“社区特征”的相关性降至0.3,重点强化“就业记录”“教育背景”等更直接相关的特征。

数据采集的“相关性陷阱”:谁在制造偏见?
相关性分析的难点,往往不在算法本身,而在数据采集环节,2026年,全球AI伦理争议中,超过60%与“数据相关性失真”有关。 本月绿色仓储与远程医疗及药品研发热度持续攀升,相关应用不断深化
以自动驾驶为例,2026年7月,德国联邦汽车运输管理局(KBA)叫停了一款L4级自动驾驶系统的上路许可,原因是其在雨天场景下的决策失误率比晴天高5倍,技术团队通过相关性分析发现:训练数据中,雨天场景的采集车辆均来自北欧,而德国本土的雨天数据不足10%;更关键的是,北欧雨天数据中,90%的场景伴随“道路湿滑但能见度良好”,而德国雨天常伴随“能见度低于50米”。算法将“北欧雨天特征”与“德国雨天风险”错误关联,导致决策失误,开发方补充了2000小时的德国本土雨天数据,并通过“场景相关性解耦”技术,将“湿滑”与“能见度”拆分为独立特征重新训练,系统通过率恢复。
医疗领域的问题更隐蔽,2026年9月,《自然·医学》杂志发表了一项研究:某AI辅助诊断系统在检测肺癌时,对亚洲患者的敏感度比欧美患者低20%,研究人员通过相关性分析发现:训练数据中,亚洲患者的CT扫描多来自基层医院,设备分辨率普遍低于欧美三甲医院;而算法将“设备分辨率”与“肺癌风险”的相关性设定为0.5,导致低分辨率图像中的微小病灶被漏诊。研究团队开发了“设备无关性校正模块”,通过模拟不同分辨率下的图像特征,将亚洲患者的诊断准确率提升至与欧美患者持平。

从“被动纠偏”到“主动设计”:相关性分析的下一站
绿色转化与睡眠健康及绿色利用领域迎来新发展,相关应用不断深化 2026年,全球AI伦理的讨论正在从“纠偏”转向“预防”,越来越多的开发者开始将相关性分析嵌入算法设计阶段,而非事后补救。
以教育AI为例,2026年6月,新加坡教育部推出“AI教学助手审查框架”,要求所有用于学生评估的算法必须通过“特征相关性透明度测试”,某数学辅导AI曾因“给男生推荐更高难度题目”被质疑性别歧视,但审查发现:该模型的推荐逻辑基于“过去3个月解题正确率”和“课堂互动频率”,而男生在这两项指标上的平均得分确实比女生高15%。问题不在算法,而在数据采集方式——课堂互动频率的统计未考虑“女生更倾向小组讨论”的文化特征,开发方调整了互动频率的计算方法,将“小组讨论贡献度”纳入相关性分析,最终消除了性别差异。
更前沿的探索来自环境科学,2026年8月,联合国环境规划署(UNEP)发布报告,介绍了一款用于预测森林火灾的AI系统,该系统通过相关性分析识别出“过去30天降水量”“植被湿度”“人类活动密度”是火灾风险的核心相关特征,而“季节”“地理位置”等传统因素的相关性不足0.2。基于这一发现,系统将数据采集重点从“宏观气候”转向“微观生态”,预测准确率从65%提升至89%。
当我们在讨论AI伦理时,我们到底该讨论什么?
回到开头的咖啡馆场景,当我们听到“AI伦理”时,或许该少问“它是否道德”,多问“它的相关性分析报告在哪里?”;少指责“算法歧视”,多追问“数据采集是否覆盖了所有群体?”;少呼吁“禁止AI”,多思考“如何通过相关性设计让技术更公平”。 野生动物保护与社会实践热度持续上升,相关产业迎来新机遇
2026年,全球AI伦理的实践正在证明:真正的技术正义,不是用道德标准审判算法,而是用科学方法解剖数据,就像医生不会仅凭症状开药,我们也需要透过“歧视”“偏见”的表象,找到隐藏在相关性链条中的真实病灶——因为在那里,才藏着改变技术的钥匙。 2026年聚焦自动驾驶与养老产业新趋势,应用场景不断拓展