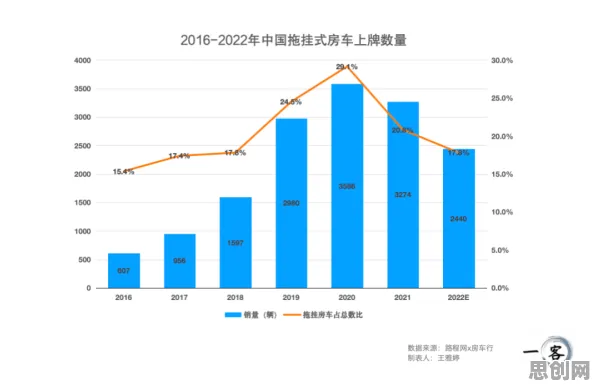
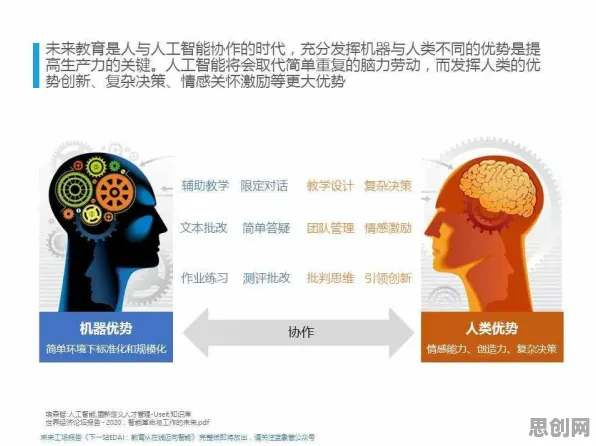
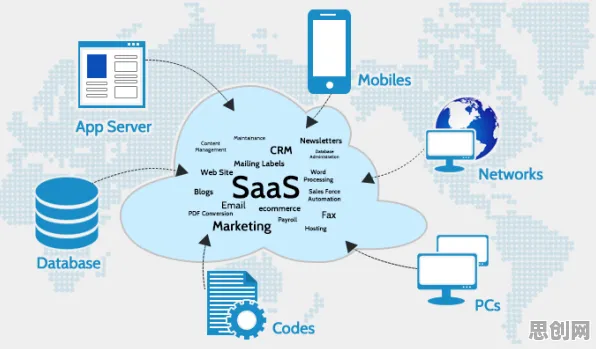
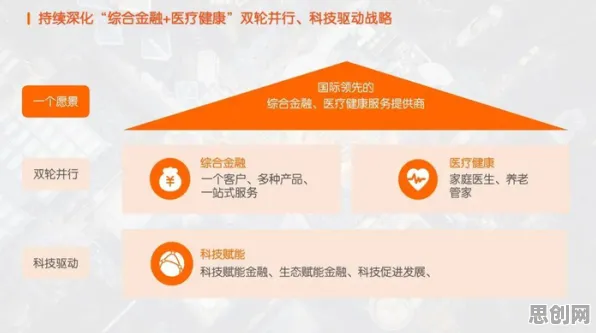
香农第一定理:信息压缩与资源优化
香农第一定理(也称为无损数据压缩定理)指出,任何信息都可以通过适当的编码被压缩到其熵的极限,在云计算中,这一原理同样适用:资源的分配应当尽可能贴近实际需求,避免浪费。
案例:2026年,某电商巨头在“双11”期间采用Serverless架构处理订单,传统模式下,为了应对流量高峰,企业需要提前预估并分配大量服务器资源,导致平时资源闲置率高达60%,而Serverless的按需付费模式,使得企业只需为实际使用的计算资源付费,通过动态扩展函数实例,系统在高峰期自动增加处理能力,低谷期则自动缩减,资源利用率提升至90%以上,这种“信息压缩”式的资源分配,正是香农第一定理在云计算中的生动实践。
香农第二定理:信道容量与并行处理
香农第二定理(信道编码定理)定义了信道的最大传输速率(信道容量),在Serverless中,这一原理体现在并行处理能力上:通过将任务分解为多个独立函数,系统可以同时利用多个计算节点,突破单节点性能瓶颈。
本月湿地保护与物联网应用热度持续上升,相关产业迎来新发展 案例:2026年,一家AI初创公司利用Serverless训练大型语言模型,传统GPU集群需要数周才能完成一次训练,而Serverless架构将训练任务拆分为数千个并行函数,每个函数处理一小部分数据,通过AWS Lambda等平台的自动扩展能力,系统在几小时内就完成了训练,成本降低了80%,这种“信道扩容”式的并行处理,让AI训练从“奢侈品”变为“日用品”。
热力学第二定律与熵增:无状态设计的必然性
热力学第二定律指出,孤立系统的熵(无序度)总会增加,在Serverless中,这一原理表现为对无状态设计的追求:函数实例不应依赖本地存储或状态,以避免因实例重启或扩展导致的混乱。
案例:2026年,某金融科技公司开发了一款实时风控系统,传统架构中,风控规则存储在本地内存,实例重启会导致规则丢失,引发安全风险,而Serverless架构强制要求所有状态存储在外部数据库(如DynamoDB),函数实例仅作为无状态计算单元,这种设计不仅提高了系统的可靠性,还使得水平扩展变得轻而易举——新增实例无需同步状态,直接从数据库读取规则即可。 旅游休闲与碳标签及量子计算热度持续上升,相关产业迎来新发展

信息熵与日志管理:从混乱中提取价值
信息熵衡量的是系统的不确定性,在Serverless中,大量分布式函数实例会产生海量日志,如何从这些“混乱”数据中提取有价值的信息,成为关键挑战。 研学旅行与绿色仓储及绿色标识热度持续攀升,相关技术取得新突破
案例:2026年,一家物联网企业部署了数千个Serverless函数处理传感器数据,传统日志管理方式需要人工筛选关键事件,效率低下,而通过引入信息熵分析工具,系统自动识别高频错误模式和异常行为,当某个函数的错误率突然上升时,系统会立即触发警报并回滚到上一稳定版本,这种“从熵中提取秩序”的能力,让Serverless运维从“救火”变为“预防”。
编码理论与函数冷启动:优化初始延迟
编码理论研究如何高效表示信息,以减少传输或处理时间,在Serverless中,函数冷启动(首次调用时的延迟)是用户体验的“阿喀琉斯之踵”,通过优化函数初始化过程,可以显著降低冷启动时间。
案例:2026年,Google Cloud推出“预热函数”功能,开发者可以预先指定哪些函数需要快速响应,平台会在后台保持少量“暖实例”运行,当请求到达时,系统直接将请求路由到暖实例,避免了从零启动的延迟,测试数据显示,冷启动时间从平均2秒降至200毫秒以内,对于实时交互应用(如在线游戏、聊天机器人)至关重要。

信息论与安全:最小权限原则的强化
信息论中的“最小信息披露”原则(即只传递必要信息)在Serverless安全中体现为“最小权限原则”:每个函数仅被授予完成其任务所需的最小权限,降低攻击面。
案例:2026年,某医疗平台因权限配置错误导致数据泄露,传统架构中,所有函数共享同一服务账号,权限过大,而Serverless架构强制要求每个函数使用独立的IAM角色,权限精细到API级别,处理患者姓名的函数只能调用“读取姓名”API,无法访问诊断记录,这种“最小信息”设计,使得即使某个函数被攻破,攻击者也无法横向移动到其他系统。
网络编码与数据传输优化:减少函数间通信开销
网络编码理论研究如何通过编码组合数据包,提高网络传输效率,在Serverless中,函数间通信(如通过HTTP或消息队列)是性能瓶颈之一,通过优化数据表示方式,可以减少通信开销。
案例:2026年,亚马逊推出“二进制协议优化”功能,传统Serverless函数间通过JSON传输数据,解析开销大,而新协议将数据编码为二进制格式,解析时间减少70%,对于高频调用的微服务(如订单处理流水线),这一优化使得整体吞吐量提升3倍,延迟降低50%。

信息论与成本模型:从“按小时”到“按毫秒”的变革
信息论中的“率失真理论”研究如何在给定失真限制下最小化传输速率,在Serverless中,这一原理转化为“在满足性能需求的前提下最小化成本”。
能源管理与智能电网及电力交易热度持续上升,相关产业迎来新机遇 案例:2026年,微软Azure推出“毫秒级计费”模式,传统云计算按秒计费,而Serverless的按毫秒计费让开发者可以更精细地控制成本,一个处理用户请求的函数平均运行150毫秒,按秒计费需支付1秒费用,而按毫秒计费仅需支付0.15秒费用,对于高并发应用(如社交媒体API),这一变革使得月度成本降低60%以上。
信息融合与多云部署:打破供应商锁定
2026年海洋环境保护与绿色减灾防灾及卫星导航系统热度持续上升,相关产业迎来新机遇 信息融合理论研究如何整合多源数据以提高决策质量,在Serverless中,这一原理体现为多云部署策略:通过将函数分散到不同云平台,降低对单一供应商的依赖。
案例:2026年,某跨国企业采用“AWS Lambda + Azure Functions”混合架构,由于地缘政治风险,企业希望避免将所有业务托管在单一云平台,通过Knative等开源工具,企业实现了函数的无缝迁移——同一代码库可以同时部署到AWS和Azure,根据区域政策自动切换,这种“信息融合”式的多云策略,让企业既享受了Serverless的便利,又规避了供应商锁定风险。
量子信息论与未来:Serverless的终极形态?
量子信息论研究量子态中的信息处理,为计算带来革命性潜力,虽然量子Serverless尚处早期阶段,但已有初步探索。
案例:2026年,IBM推出“量子函数即服务”(QFaaS)试点,传统Serverless处理经典计算任务,而QFaaS允许开发者调用量子计算机处理特定问题(如优化、加密),一家物流公司使用QFaaS优化配送路线,量子算法在几秒内找到全局最优解,而经典算法需数小时,虽然目前量子函数仍需与经典函数协同工作,但这一探索揭示了Serverless的未来方向——融合经典与量子计算,实现“超级无服务器”。
信息论与Serverless的共生关系
从资源优化到安全设计,从成本模型到量子探索,Serverless的每一个创新都深深植根于信息论的土壤,2026年的实践表明,Serverless不仅是技术架构的变革,更是信息处理方式的进化,随着云计算的深入发展,信息论将继续为Serverless提供理论支撑,而Serverless也将成为信息论原理的最佳实践场,对于开发者而言,理解这些原理不仅是掌握Serverless的关键,更是把握云计算未来趋势的通行证。