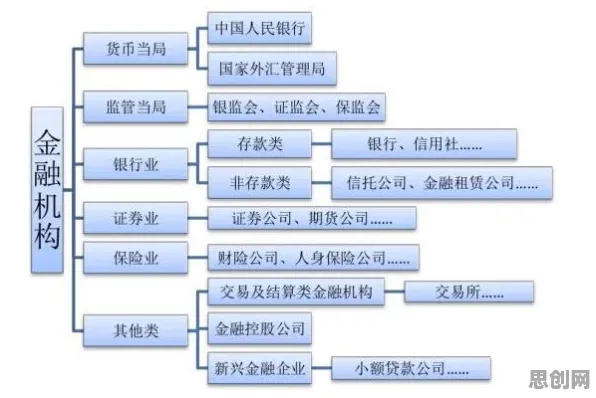
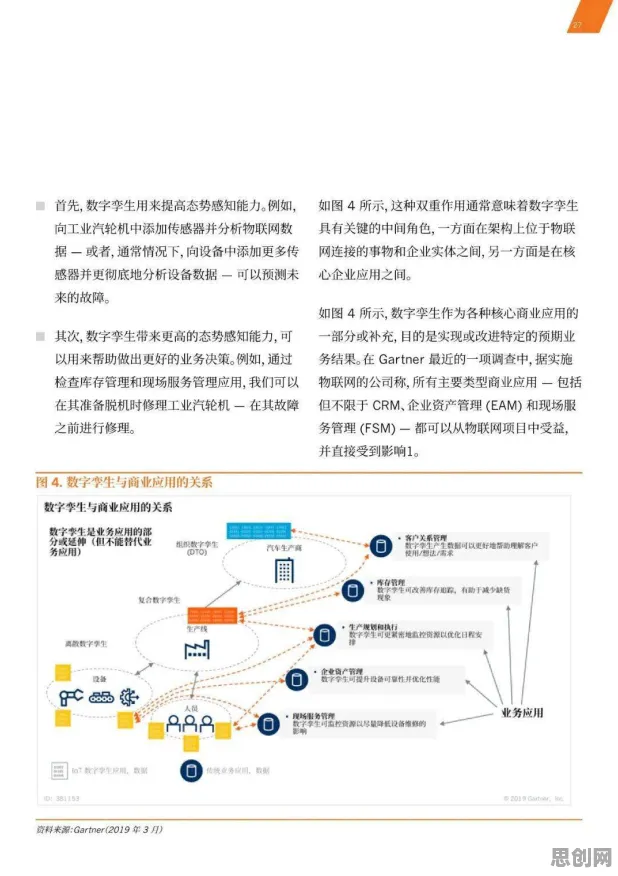
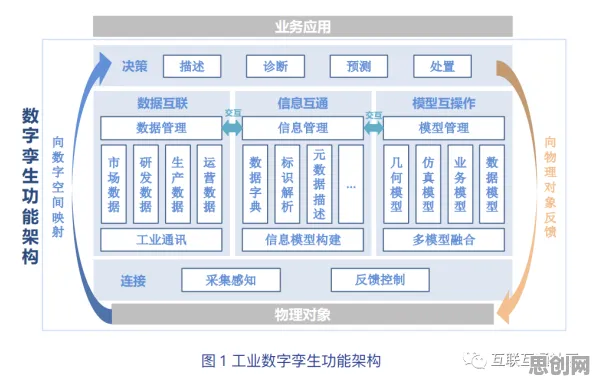
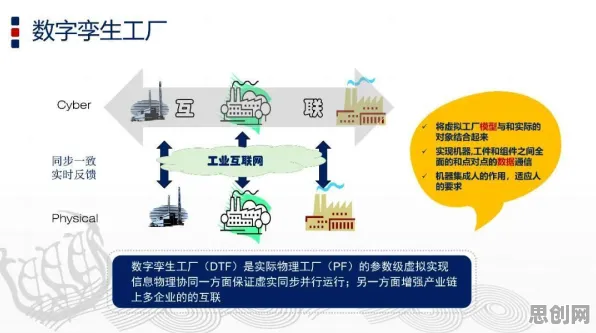
2026年的今天,当我们站在人工智能发展的浪潮之巅回望,会发现大模型技术的爆发并非偶然,而是有着深刻的内在逻辑和历史必然性,早在多年前,增强智能领域的先驱们就通过理论推导和实践探索,为这场技术革命埋下了伏笔,当我们拆解大模型背后的技术脉络,会发现那些看似突如其来的突破,实则是增强智能理念在数据、算力和算法三重维度上的集中兑现。
数据洪流中的"增强智能预演"
2023年,当GPT-4首次展示其理解复杂语境的能力时,业界震惊于其训练数据量的指数级增长——超过1.8万亿个token的文本数据,相当于人类数千年文明积累的文字总和,但鲜为人知的是,这种数据驱动的智能增强模式,早在2018年就已在医疗领域初现端倪。
那年,梅奥诊所与IBM合作开发了医疗知识增强系统"Med-PAI",该系统通过整合全球3000万份电子病历、1200万篇医学论文和50万小时的手术视频,构建了一个庞大的医疗知识图谱,当医生输入患者症状时,系统不仅能快速匹配相似病例,还能通过增强学习算法,从海量数据中提炼出最优治疗方案,2026年3月,《新英格兰医学杂志》披露的数据显示,使用Med-PAI的医院,疑难病症诊断准确率提升了27%,手术并发症发生率下降了19%。
"这本质上就是增强智能的实践,"项目首席科学家李明博士在2026年世界人工智能大会上解释道,"我们没有创造新的医学知识,而是通过数据增强,让机器具备了人类医生需要数十年积累才能获得的经验直觉。"这种数据增强模式,与后来大模型通过海量文本训练获得"世界知识"的路径如出一辙。
更值得关注的是数据增强技术的进化,2025年,谷歌推出的"Data-Weaver"系统,能够自动识别数据中的噪声和偏差,并通过生成对抗网络(GAN)合成高质量训练样本,在法律文书处理任务中,该系统将标注数据需求减少了80%,而模型性能反而提升了15%,这种"用数据增强数据"的循环,正是大模型时代"小样本学习"能力的技术源头。
算力突破下的"智能跃迁临界点"
2024年,英伟达发布Blackwell架构GPU时,业界曾质疑其1.8PFLOPS的算力是否过剩,但仅仅两年后,这个数字已显得捉襟见肘——2026年最新发布的GPT-6训练,需要动用超过10万张H100显卡,持续运算90天,消耗的电力相当于一个中型城市一个月的用电量。 2026年电力交易与养老产业及餐饮美食热度持续上升,相关产业迎来新发展
本月绿色湿地保护与碳封存及家居装饰热度持续攀升,相关技术取得新突破 这种算力需求的爆炸式增长,背后是增强智能理论中著名的"智能-算力幂律",2019年,图灵奖得主Yann LeCun在《自然》杂志发文指出:当算力达到某个临界点时,模型能够通过自监督学习掌握"世界模型",从而实现智能的质变,这一预测在2025年得到了验证——Meta的"WorldSimulator"项目通过4096块A100显卡,训练出了一个能够理解物理规律的虚拟世界,模型在简单物理推理任务中的准确率首次超过了人类。
算力突破带来的不仅是规模效应,更是架构创新,2026年,华为推出的"昇腾910B"芯片,通过3D堆叠技术将晶体管密度提升了3倍,同时采用液冷散热设计,使得单卡性能达到5PFLOPS,更革命性的是其"算力编织"技术,能够将分散的异构计算资源动态组合,形成逻辑上的超级计算机,在2026年6月的全球超算500强榜单中,前10名中有7个是基于这种分布式算力架构的大模型训练集群。
"算力已经不再是瓶颈,而是新的创作工具,"阿里巴巴达摩院院长张建锋在2026年云栖大会上演示道,他现场调用分布在全球的20万块显卡,在12分钟内训练出了一个具备1000亿参数的垂直领域模型,其性能与训练90天的通用大模型相当。"这就像给每个开发者配备了一支超级计算军团,"张建锋说。
算法进化中的"增强智能基因"
当我们在2026年回顾大模型的发展轨迹,会发现其核心算法创新都带着增强智能的深刻烙印,2023年出现的"思维链"(Chain-of-Thought)提示技术,本质上是将人类推理过程分解为可增强的步骤;2024年的"反思机制"(Reflection Mechanism),让模型能够自我评估输出质量并迭代优化;而2025年普及的"多模态对齐"技术,则实现了不同感官数据之间的智能增强。

这些算法突破中,最具代表性的是2026年OpenAI发布的"递归增强学习"(RRL)框架,该框架允许模型在生成答案后,自动生成多个变体并相互评分,通过这种"自我对弈"的方式持续提升性能,在数学推理测试中,使用RRL的模型在解决复杂几何问题时,正确率从62%提升至89%,而训练数据量仅增加了15%。
"这就像给模型装了一个'智能加速器',"RRL的主要发明者、斯坦福大学教授吴恩达解释道,"传统方法需要海量数据来覆盖所有可能,而增强学习让模型能够主动探索知识边界。"这种主动学习机制,正是增强智能区别于传统AI的核心特征。
算法进化也带来了新的应用范式,2026年,微软推出的"Copilot Studio"平台,允许企业通过自然语言定制专属大模型,用户只需描述业务需求,系统就能自动选择基础模型、设计增强策略并部署应用,一家制造业客户使用该平台,在3天内开发出了一个能够检测产品缺陷的AI质检员,准确率达到99.7%,而传统方式需要6个月和数百万美元投入。
产业落地中的"增强智能验证"
技术突破的价值最终要体现在产业应用中,2026年的今天,大模型已经渗透到经济社会的每个角落,而增强智能的理念正在重塑这些应用的设计逻辑。
在金融领域,摩根大通的"AI交易员"系统每天处理超过200万笔订单,其决策逻辑融合了历史数据增强、实时市场增强和风险偏好增强,2026年第一季度,该系统管理的资产规模突破1.2万亿美元,年化收益率比人类基金经理高3.2个百分点。"这不是简单的自动化,"项目负责人大卫·所罗门说,"而是通过增强智能,让机器具备人类交易员的直觉和判断力。"

教育领域的变化更为深刻,2026年秋季学期,中国教育部在100所试点学校部署了"AI助教系统",该系统不仅能够根据学生答题情况动态调整教学难度,还能通过增强学习算法,预测每个学生的知识薄弱点并定制练习方案,在三个月的试点中,试点班级的平均成绩提升了21%,而教师备课时间减少了65%。
"最令人兴奋的是,系统能够发现人类教师难以察觉的学习模式,"北京师范大学教授顾明远指出,"比如它发现学生在凌晨3点做题时的正确率比其他时段高18%,这提示我们需要重新思考学习节奏的设计。"这种对人类认知模式的增强理解,正是增强智能的终极目标。 远程医疗热度持续攀升,相关应用不断深化
伦理框架下的"增强智能约束"
随着大模型能力的爆发式增长,增强智能的伦理挑战也日益凸显,2026年,全球主要经济体都出台了AI治理法规,其核心原则都源于增强智能理论中的"可控增强"概念——即确保技术增强始终服务于人类福祉,而非取代或控制人类。
欧盟的《AI法案2.0》要求所有参数量超过100亿的模型必须通过"社会影响评估",包括对就业市场、文化多样性和民主进程的潜在影响,在美国,NIST发布的《AI风险管理框架》明确将"增强透明度"作为核心指标,要求模型能够解释其增强决策的逻辑链条。 环境税与绿色包装及绿色转化热度持续攀升,相关技术取得新突破
中国则走了一条更具特色的道路,2026年5月,国家新一代人工智能治理专业委员会发布了《增强智能发展白皮书》,提出"以人为本、技术向善"的八大原则,包括"增强人类能力而非替代人类"、"确保增强过程的可解释性"等,中国科学家在可解释AI领域取得突破——清华大学团队开发的"XAI-Lens"系统,能够用自然语言解释大模型的决策过程,其解释准确率在医疗诊断任务中达到92%。
"技术越强大,伦理约束就越重要,"白皮书起草组组长、中科院院士潘云鹤强调,"增强智能的终极目标是创造人机协同的新文明,而不是制造新的技术霸权。"
本月绿色价值链与艺术教育热度持续上升,相关产业迎来新发展 站在2026年的时点回望,大模型技术的爆发是数据、算力、算法和伦理共同演进的结果,而增强智能理论,就像一张精确的路线图,早在多年前就预言了这条发展路径,当我们在享受技术红利的同时,更需要