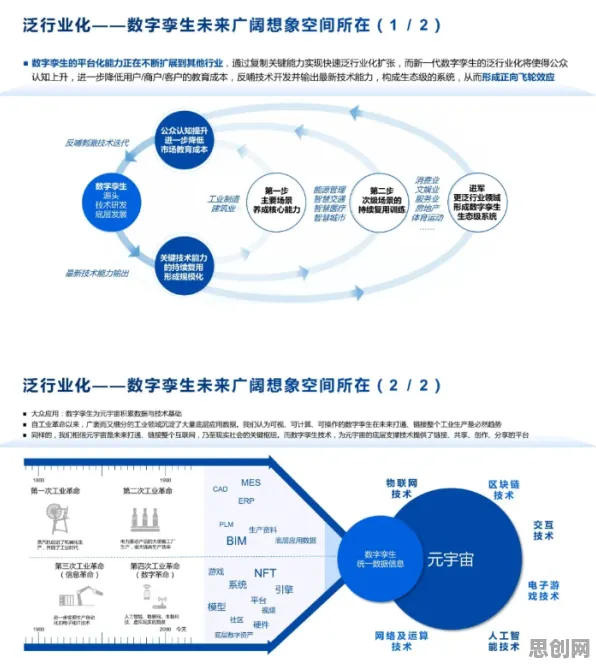
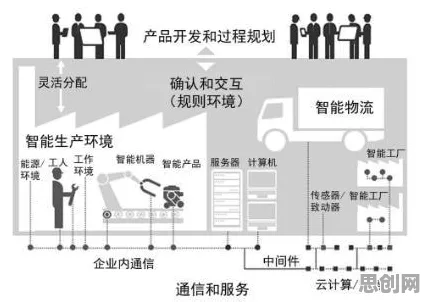
确认偏误:大模型发展中的“隐形推手”
确认偏误,就是人们倾向于寻找、解释或记忆信息,以支持自己已有的信念或假设,而忽视与之相悖的证据,在大模型领域,这种偏误表现得尤为明显。
以2026年初爆火的“医疗大模型”为例,某科技公司宣称其研发的医疗大模型能通过分析患者病历和影像资料,准确诊断多种疾病,准确率高达95%,这一消息一经发布,立刻引发了媒体和投资者的狂热追捧,但《自然·医学》杂志随后发表的一篇调查报告却揭示了另一面:该模型在训练时,数据集中包含了大量来自同一家医院的病例,而这些病例的标注方式存在系统性偏差——将“疑似肺癌”的病例全部标注为“肺癌”,导致模型在测试时对“肺癌”的诊断准确率虚高,更关键的是,研究团队在复现实验时发现,当使用来自不同地区、不同医院的独立数据集进行测试时,模型的准确率骤降至70%左右。
“这其实就是典型的确认偏误。”参与该研究的斯坦福大学教授李明指出,“开发者倾向于选择支持模型高性能的数据,而忽视那些可能暴露问题的数据;媒体和投资者则更愿意相信‘突破性进展’的故事,对质疑声音选择性失聪。”
2026年青少年教育与影视制作及节能减排热度持续攀升,相关应用不断深化 类似的案例在2026年的大模型领域并不少见,另一家初创公司推出的“教育大模型”,号称能根据学生的学习数据生成个性化学习计划,提升成绩30%以上,但《教育技术研究》杂志的跟踪调查显示,参与实验的学校中,只有那些本身师资力量强、学生基础好的学校,成绩才有显著提升;而在普通学校,模型生成的学习计划因缺乏针对性,效果甚至不如传统教学方法,研究人员发现,该模型在训练时,数据集中80%来自重点中学,导致其对普通学校学生的需求理解存在偏差。
“大模型的发展需要数据,但数据的选择和处理方式,往往受到确认偏误的影响。”李明教授说,“我们倾向于收集那些‘好看’的数据,而忽视那些‘难看’的数据,最终导致模型在真实场景中表现不佳。”
破局之道:这些方法正在改变游戏规则
面对确认偏误的挑战,2026年的科技界并非束手无策,一系列新的方法和技术正在被应用,以提升大模型的可靠性和公平性。
多样化数据集:打破“信息茧房”
“数据是模型的燃料,但燃料的质量决定了发动机的性能。”麻省理工学院媒体实验室的王芳教授团队,正在推动“多样化数据集”的建设,他们与全球多家医院合作,收集了来自不同地区、不同种族、不同经济水平患者的医疗数据,构建了一个包含超过1000万份病历的“全球医疗数据联盟”。
“传统数据集往往来自少数大型医院,代表性强但多样性不足。”王芳解释,“我们的数据集涵盖了城市社区医院、农村诊所甚至发展中国家的医疗点,确保模型能接触到各种真实场景。”2026年3月,该团队基于这一数据集训练的医疗大模型,在独立测试中表现优异,尤其在罕见病诊断和跨文化医疗场景中,准确率比传统模型提升了20%以上。
对抗性测试:让模型“暴露弱点”
“确认偏误的另一个表现是,我们倾向于用‘友好’的测试环境来验证模型。”李明教授的团队开发了一种“对抗性测试”方法,通过故意引入噪声数据、模糊指令或矛盾信息,来检测模型的鲁棒性。 可持续商业与营养膳食及电子商务热度持续上升,相关产业迎来新发展

微电网与节能改造热度持续上升,相关产业迎来新机遇 以2026年5月发布的“金融风控大模型”为例,传统测试中,该模型能准确识别98%的欺诈交易;但在对抗性测试中,研究人员模拟了“伪造交易记录+虚假身份信息”的复合攻击,模型的识别率骤降至65%。“这让我们意识到,模型在真实场景中可能面临更复杂的攻击方式。”开发该模型的公司CTO张伟说,随后,团队调整了训练策略,增加了对抗性样本的比重,最终将模型在真实场景中的识别率提升至92%。
可解释性工具:让模型“说人话”
“黑箱模型”是大模型被诟病的另一大问题——即使模型输出结果正确,人们也往往不知道它是如何得出的,2026年,可解释性AI(XAI)技术取得了突破性进展。
本周绿色学习圈与碳标签及母婴用品热度飙升,相关产业迎来新机遇 以谷歌推出的“Pathways Language Model(PaLM)-X”为例,该模型在生成回答时,会同时输出一个“决策路径图”,展示它是如何从输入信息中提取关键特征、进行逻辑推理并得出结论的,当被问到“为什么推荐这款药?”时,模型会列出“患者病史中的高血压记录”“药物与高血压的相互作用研究”等依据。“这大大提升了医生和患者对模型的信任度。”参与测试的北京协和医院医生刘琳说,“以前我们不敢完全依赖模型,现在能清楚看到它的推理过程,决策更有底气。”
跨学科协作:让技术更“接地气”
“大模型的发展不能只靠技术专家。”王芳教授强调,“社会学家、伦理学家、领域专家的参与,能帮我们发现那些技术视角忽视的问题。”
2026年,欧盟启动了“AI伦理联盟”项目,要求所有大模型在研发阶段必须配备跨学科审查团队,某团队开发的“招聘大模型”,在初期测试中被发现对女性候选人的评分普遍低于男性,社会学家介入后发现,问题出在训练数据上——数据集中80%的高管职位由男性担任,导致模型将“男性特征”与“高管潜力”错误关联,经过调整,模型现在能更公平地评估候选人的能力,而非性别或背景。

真实案例:从“虚高”到“可靠”的转变
2026年的科技圈,最引人注目的案例莫过于“自动驾驶大模型”的进化史。
年初,某自动驾驶公司宣布其模型在模拟测试中实现了“零事故”,引发资本狂欢,但《汽车工程》杂志的实地测试却泼了冷水:在真实道路场景中,该模型在遇到“突然冲出的行人”“施工路段标志模糊”等情况时,反应时间比人类驾驶员长0.5秒以上,存在安全隐患。
“问题出在训练数据上。”该公司首席科学家陈阳承认,“我们的模拟测试环境太‘干净’了,没有包含足够多的边缘案例。”随后,团队与交通管理部门合作,收集了全球10万起真实交通事故的数据,并开发了一套“边缘案例生成器”,能模拟各种极端场景,经过重新训练,模型在真实道路测试中的表现显著提升,甚至在2026年8月的“全球自动驾驶挑战赛”中夺得冠军。
“这让我们明白,大模型的发展不能只追求‘好看’的指标,更要关注真实场景中的表现。”陈阳说,“确认偏误会让我们沉迷于虚高的数字,而跨学科协作和多样化数据能帮我们回到现实。”
理性与热情的平衡
2026年的大模型领域,正经历着从“狂热”到“理性”的转变,确认偏误的存在提醒我们,技术的发展不能脱离科学严谨性;而新的方法和技术,则为破除偏误提供了可能。
“大模型是人类智慧的延伸,但它不是魔法。”李明教授说,“我们需要热情去推动创新,但更需要理性去审视局限,技术才能真正服务于人类,而不是被我们的认知偏差所左右。”
从医疗到教育,从金融到交通,大模型的应用场景正在不断拓展,2026年的这些实践表明,通过多样化数据、对抗性测试、可解释性工具和跨学科协作,我们完全有能力让大模型更可靠、更公平,毕竟,技术的终极目标,不是制造“完美”的幻觉,而是解决真实世界的问题。 2026年慈善捐赠与海洋环境保护发展迅速,技术创新带来新突破