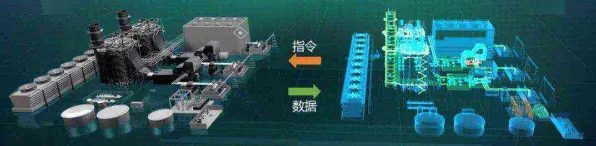
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它就像一把神奇的钥匙,被寄予厚望能打开工业智能化转型的新大门,从大型跨国制造企业到新兴的科技型工厂,都在积极尝试部署数字孪生技术,期望借此实现生产流程的优化、设备故障的精准预测以及产品质量的显著提升,在这股热潮背后,新中产群体——那些在工业领域担任中层管理、技术研发等关键岗位的专业人士,却正被数字孪生技术部署实践中的种种问题所困扰。
新中产的困扰:数字孪生部署的“拦路虎”
新中产在工业领域往往有着丰富的经验和专业知识,他们对新技术有着敏锐的洞察力和积极的应用态度,但在数字孪生技术的部署实践中,他们却遭遇了诸多难题。 关注网络公益与能源管理及绿色转化发展动态,技术创新推动产业升级
数据整合的“千头万绪”
数字孪生的核心在于构建一个与现实物理系统高度对应的虚拟模型,而这个模型的基础就是海量且准确的数据,在现实中,工业企业的数据来源极为广泛,包括生产设备、传感器、管理系统等多个渠道,这些数据格式各异、标准不统一,就像一堆杂乱无章的拼图碎片,难以整合在一起。
以一家位于长三角地区的汽车零部件制造企业为例,该企业在2026年决定部署数字孪生技术来优化生产流程,企业拥有多种类型的生产设备,从老式的冲压机到先进的数控机床,每种设备的数据采集方式和格式都不尽相同,企业的ERP系统、MES系统等管理软件也各自存储着不同类型的数据,在整合这些数据时,新中产技术团队发现,不同系统之间的数据接口不兼容,数据传输存在延迟和丢失的问题,为了解决这些问题,他们不得不投入大量的人力和时间进行数据清洗和转换,但效果却不尽如人意,数据整合的困难不仅影响了数字孪生模型的构建进度,还导致模型的准确性大打折扣,无法为生产决策提供可靠的依据。
模型构建的“高门槛”
2026年绿色街区热度持续上升,相关领域迎来新发展 构建一个准确的数字孪生模型需要综合运用多学科知识,包括机械工程、自动化控制、计算机科学等,对于新中产技术团队来说,虽然他们具备一定的专业知识,但在面对复杂的工业系统时,仍然感到力不从心。
一家位于珠三角的电子制造企业在部署数字孪生技术时,遇到了模型构建的难题,该企业的生产线涉及多个环节,包括芯片贴片、焊接、组装等,每个环节都有其独特的工艺和参数,技术团队在构建数字孪生模型时,需要准确模拟每个环节的物理过程和动态变化,由于缺乏相关的专业知识和经验,他们在模型参数的设置和验证上遇到了很大的困难,在模拟芯片贴片过程中的温度变化时,他们发现模型预测的结果与实际测量值存在较大偏差,为了解决这个问题,他们不得不请教行业专家,并进行大量的实验和调整,这不仅增加了项目的时间成本,还对团队的技术能力提出了巨大的挑战。
实时交互的“时差困境”
数字孪生技术的优势在于能够实现虚拟模型与现实物理系统的实时交互,从而及时反馈生产过程中的问题并进行调整,在实际部署中,实时交互却面临着时差的困境。
一家大型钢铁企业在2026年引入了数字孪生技术来监控高炉的运行状态,高炉是钢铁生产的核心设备,其运行状态直接影响到产品的质量和生产效率,技术团队希望通过数字孪生模型实时监测高炉内的温度、压力等参数,并及时调整生产参数以保证高炉的稳定运行,在实际运行中,他们发现由于数据传输延迟和模型计算时间的影响,虚拟模型反馈的信息总是比实际生产情况滞后几分钟,这几分钟的时差在高炉生产中却可能带来严重的后果,当高炉内温度出现异常升高时,由于模型反馈延迟,操作人员无法及时采取措施,可能导致高炉损坏甚至发生安全事故。
交叉熵:解开困扰的“钥匙”
面对数字孪生技术部署实践中的种种困扰,新中产群体开始寻找新的解决方案,而交叉熵这一在信息论和机器学习领域广泛应用的概念,为他们提供了新的思路。

交叉熵的基本原理
交叉熵是衡量两个概率分布之间差异的一种指标,在机器学习中,它常用于评估模型的预测结果与真实标签之间的差异,交叉熵越小,说明模型的预测结果越接近真实情况,在数字孪生技术中,我们可以将现实物理系统的状态看作真实分布,将数字孪生模型的预测结果看作预测分布,通过计算交叉熵来评估模型的准确性和性能。
数据整合中的交叉熵应用
在数据整合方面,交叉熵可以帮助新中产技术团队筛选和优化数据,通过对不同数据源的数据进行交叉熵计算,可以评估它们之间的相似性和差异性,对于交叉熵较小的数据源,说明它们之间的相关性较强,可以优先考虑整合;而对于交叉熵较大的数据源,则需要进一步分析其原因,判断是否需要进行数据清洗或转换。
以之前提到的汽车零部件制造企业为例,技术团队在整合生产设备和管理系统的数据时,运用了交叉熵的方法,他们对不同设备采集的数据和管理系统中的数据进行了交叉熵计算,发现某些设备的数据与生产计划数据之间的交叉熵较小,说明这些设备的数据对生产计划的执行有重要影响,他们将这些数据作为重点整合对象,优先进行数据清洗和转换,并建立了高效的数据传输通道,通过这种方式,数据整合的效率得到了显著提高,数字孪生模型的构建进度也加快了。
模型构建中的交叉熵优化
在模型构建方面,交叉熵可以作为一种优化指标,帮助技术团队调整模型参数,提高模型的准确性,在构建数字孪生模型时,技术团队可以将实际生产数据作为真实标签,将模型的预测结果作为预测分布,通过最小化交叉熵来优化模型参数。
回到电子制造企业的案例,技术团队在构建芯片贴片过程的数字孪生模型时,引入了交叉熵作为优化指标,他们收集了大量的实际生产数据,包括芯片贴片过程中的温度、压力、时间等参数,并将这些数据作为真实标签,他们通过不断调整模型参数,使模型的预测结果与真实标签之间的交叉熵最小化,经过多次实验和调整,模型的准确性得到了显著提高,预测结果与实际测量值之间的偏差明显减小,这不仅提高了生产过程的质量控制水平,还为企业的生产决策提供了更加可靠的依据。

实时交互中的交叉熵补偿
在实时交互方面,交叉熵可以用于补偿数据传输延迟和模型计算时间带来的时差问题,通过对历史数据的分析和交叉熵计算,技术团队可以建立预测模型,提前预测现实物理系统的未来状态,并将预测结果反馈给操作人员。
以钢铁企业的高炉监控为例,技术团队利用交叉熵的方法对高炉的历史运行数据进行了分析,他们发现,高炉内的温度、压力等参数的变化存在一定的规律性,他们建立了一个基于交叉熵的预测模型,根据当前采集的数据和历史数据,提前预测高炉未来几分钟的状态,当预测到高炉内温度可能出现异常升高时,系统会及时发出警报,操作人员可以提前采取措施进行调整,避免了安全事故的发生,通过这种方式,交叉熵有效地补偿了实时交互中的时差问题,提高了数字孪生技术的实用性和可靠性。
实践案例:交叉熵助力企业突破困境
在2026年,已经有不少企业通过应用交叉熵解决了数字孪生技术部署实践中的困扰,取得了显著的成效。 绿色交通网与儿童教育热度持续攀升,相关领域迎来新突破
某航空航天企业的成功实践
某航空航天企业在研发新型飞机发动机时,遇到了数字孪生模型构建和实时交互的难题,飞机发动机是一个极其复杂的系统,涉及多个学科的知识和大量的参数,在构建数字孪生模型时,技术团队发现模型的准确性和实时性都无法满足研发需求。 2026年环保产品与森林保护及绿色回收热度持续上升,相关领域迎来新发展
为了解决这些问题,他们引入了交叉熵的方法,在模型构建方面,他们将发动机的实际运行数据作为真实标签,通过最小化交叉熵来优化模型参数,经过大量的实验和调整,模型的准确性得到了显著提高,能够准确模拟发动机在不同工况下的性能,在实时交互方面,他们利用交叉熵建立了预测模型,提前预测发动机的未来状态,并将预测结果反馈给研发人员,这使得研发人员能够及时发现潜在的问题并进行调整,大大缩短了研发周期,降低了研发成本。
某新能源企业的创新应用
某新能源企业在建设大型光伏电站时,决定部署数字孪生技术来优化电站的运营和维护,由于光伏电站占地面积大、设备分布广,数据整合和实时监控成为了难题。
本月碳汇与会展经济热度持续上升,相关产业迎来新发展 该企业技术团队运用交叉熵的方法解决了这些问题,在数据整合方面,他们对不同区域的光伏设备采集的数据进行了交叉熵计算,筛选出了关键数据,并建立了高效的数据传输网络,在实时监控方面,他们利用交叉熵建立了故障预测模型,根据设备的历史运行数据和实时数据,提前预测设备可能出现的故障,当预测到某块光伏板可能出现故障