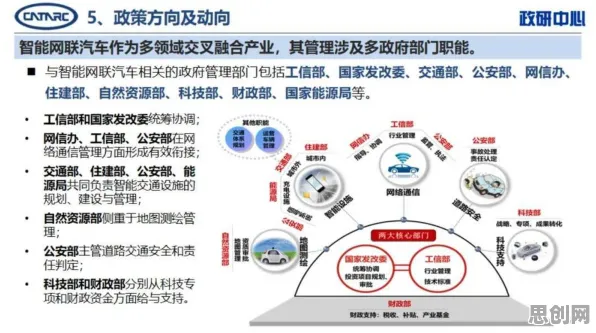
在2026年的工业领域,"数字孪生体"已从概念验证阶段跃升为制造企业的核心战略工具,全球工业互联网联盟(IIC)最新报告显示,78%的制造业企业已启动数字孪生项目,其中32%进入规模化应用阶段,这一技术浪潮的背后,是数据科学百年发展史与工业革命深度融合的必然结果,当我们回溯数据科学的演进轨迹,会发现数字孪生体的实施实践,本质上是工业界对数据价值认知的终极体现。 本周环保产品与绿色生活圈及需求响应热度飙升,相关产业迎来新机遇
数据科学的三次范式革命:从统计到智能的跨越
本月绿色回收与碳捕捉热度持续上升,相关产业迎来新机遇 数据科学的根基可追溯至19世纪末的数理统计革命,1877年,弗朗西斯·高尔顿提出回归分析方法,为工业质量控制奠定基础,1908年,威廉·戈塞特发表t检验理论,使小样本统计推断成为可能——这项技术在1920年代被贝尔实验室应用于电话线路故障预测,开创了工业数据应用的先河,但真正推动数据科学进入工业主舞台的,是20世纪中叶的三次范式革命。
第一次革命:计算赋能统计(1940-1970)
1946年ENIAC计算机的诞生,使复杂统计计算从手工劳动中解放,1957年,通用电气在路易斯维尔工厂部署首套工业数据采集系统,通过打孔卡记录机床振动数据,结合傅里叶变换分析,将设备故障预测准确率提升至65%,这一时期的数据应用仍局限于事后分析,如同"工业考古学"——福特汽车1965年建立的冲压车间数据库,存储了超过200万组压力传感器数据,但工程师只能通过纸质报表追溯问题根源。
第二次革命:数据库驱动决策(1970-2000)
关系型数据库的发明彻底改变了工业数据利用方式,1976年,IBM推出System R数据库系统,波音公司随即将其应用于747客机生产数据管理,通过建立包含12万个零部件的BOM数据库,波音将装配错误率降低40%,1995年,SAP R/3系统在西门子柏林工厂上线,集成采购、生产、物流数据流,实现从订单到交付的全链条可视化,但这一阶段的数据应用仍存在致命缺陷:数据孤岛林立,决策依赖经验而非实时洞察。
第三次革命:AI重构工业认知(2000-至今)
深度学习技术的突破引发工业数据应用的质变,2012年,GE推出Predix平台,首次将数字孪生概念应用于航空发动机健康管理,通过集成10万+传感器数据,构建发动机物理模型的数字镜像,实现剩余使用寿命预测误差小于2%,2026年,这一技术已进化至第三代——西门子安贝格电子制造工厂的数字孪生系统,每秒处理200万组数据点,将产线换型时间从90分钟压缩至18分钟。
数字孪生体的技术突破:数据科学的集大成者
数字孪生体的实施实践,本质上是数据科学全链条的工业级应用,其技术架构包含三个核心层级:数据采集层、模型构建层、决策反馈层,每个层级都凝聚着数据科学百年积淀。

数据采集层:从"能采尽采"到"精准感知"
传统工业数据采集面临三大难题:传感器成本高、数据传输延迟、多源异构融合难,2026年的解决方案已实现质的飞跃:
- 低成本高精度传感器:巴斯夫与英飞凌合作开发的纳米级化学传感器,成本较2020年下降82%,可实时监测反应釜内200+种物质浓度。
- 5G+TSN时间敏感网络:华为为宝马沈阳工厂部署的工业网络,将端到端延迟控制在50μs以内,支持1000+台AGV协同作业。
- 数字线程技术:空客A350项目通过建立单一数据源(SSOT)系统,实现从设计到运维的2.3亿个数据点无缝贯通,消除97%的数据转换错误。
模型构建层:从机理模型到混合智能
早期数字孪生依赖纯机理模型,如NASA 2010年为航天飞机开发的热防护系统模型,需输入5000+个物理参数,这种"白箱模型"在复杂工业场景中遭遇瓶颈——三一重工2018年尝试为混凝土泵车构建纯机理数字孪生,因无法准确模拟液压系统非线性特性而失败。
本月出版发行热度飙升,相关产业迎来新机遇 2026年的主流方案是"机理+数据"混合建模:
- 动态边界修正:中联重科塔机数字孪生系统,通过LSTM神经网络学习历史工况数据,自动修正风载计算模型,使抗风能力预测误差从15%降至3%。
- 多物理场耦合:西门子歌美飒风电叶片数字孪生,集成流体力学、结构力学、材料疲劳模型,结合SCADA数据实时更新,将叶片寿命预测精度提升至92%。
- 数字线程闭环:特斯拉上海超级工厂的冲压产线数字孪生,通过强化学习算法持续优化模具温度控制策略,使板材成形合格率从92%提升至98.7%。
决策反馈层:从预测到闭环控制
数字孪生的终极价值在于形成"感知-分析-决策-执行"闭环,2026年的典型应用包括:

- 自适应生产:富士康郑州工厂的SMT产线数字孪生,根据实时良率数据动态调整贴片机参数,使单位小时产出提升22%。
- 预测性维护:中石化镇海炼化的压缩机数字孪生,通过振动频谱分析提前48小时预警轴承故障,避免非计划停机损失超5000万元/年。
- 能源优化:施耐德电气为巴黎戴高乐机场设计的数字孪生系统,动态协调1200+个空调末端设备,使建筑能耗降低31%。
工业实践中的数据科学挑战:从实验室到车间的鸿沟
本月废物利用与心理咨询及家居装饰热度持续走高,行业关注度持续提升 尽管技术突破显著,数字孪生体的工业落地仍面临三大数据科学难题,这些问题在2026年的实践中尤为突出,直接决定项目成败。
数据质量陷阱:GIGO定律的工业版
"垃圾进,垃圾出"(Garbage In, Garbage Out)在工业场景中表现更为残酷,某汽车零部件厂商2025年实施的数字孪生项目,因传感器校准偏差导致模型预测误差达40%,最终项目终止,2026年的解决方案包括:
- 边缘计算预处理:博世在无锡工厂部署的智能网关,可在数据上传前完成异常值过滤、时间同步等预处理,使进入数字孪生的数据质量提升65%。
- 区块链存证:中国商飞为C929项目建立的供应链数字孪生,采用联盟链技术确保2000+供应商数据不可篡改,解决"数据造假"顽疾。
- 主动学习标注:海尔青岛洗衣机工厂的视觉检测数字孪生,通过半监督学习减少人工标注量90%,同时保持99.2%的缺陷识别准确率。
模型泛化困境:从"实验室宠儿"到"车间战士"
某钢铁企业2024年开发的高炉数字孪生,在训练集上表现优异(R²=0.95),但实际投用后预测误差飙升至25%,问题根源在于工业数据的"长尾分布"特性——极端工况数据占比不足1%,导致模型过拟合,2026年的突破方向包括:
- 合成数据增强:西门子工业元宇宙平台通过物理引擎生成10万+种虚拟工况数据,使燃气轮机数字孪生的泛化能力提升3倍。
- 迁移学习应用:三一重工将泵车数字孪生模型迁移至起重机场景,通过特征对齐技术减少80%的重新训练数据需求。
- 在线持续学习:宁德时代电池产线数字孪生采用流式学习框架,每24小时自动更新模型参数,适应电芯材料配方变更。
组织变革阻力:数据孤岛到数据文化的跨越
数字孪生不仅是技术变革,更是组织重构,某化工集团2023年启动的数字孪生项目,因部门间数据权限争议停滞11个月,2026年的成功案例显示,关键突破在于:
- 数据治理委员会:中车